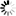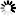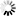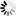如上所述,当HTML源码时,可以通过charset去得知文件编码。
但是,很多时候,我们去打开一个文件时,
可能会遇到乱码,但是由于未必立刻就已知其文件编码是什么
所以,只能去猜测其编码是什么,然后再切换到对应的编码类型,去查看内容是否可以正常显示。
例 3.2. 出现乱码,猜测出是西欧编码,切换到ISO 8859-1而消除乱码
比如遇到一个例子:
打开文件时,出现是乱码:
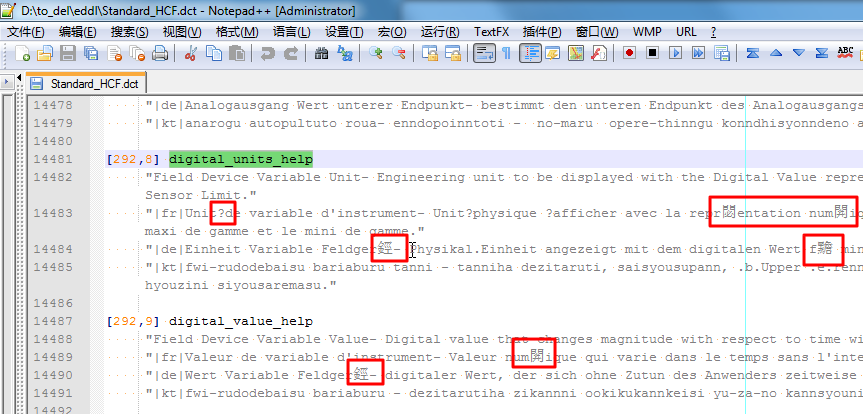 |
看起来,就像是西欧类的字符,所以,去切换到对应的ISO 8859-1编码:
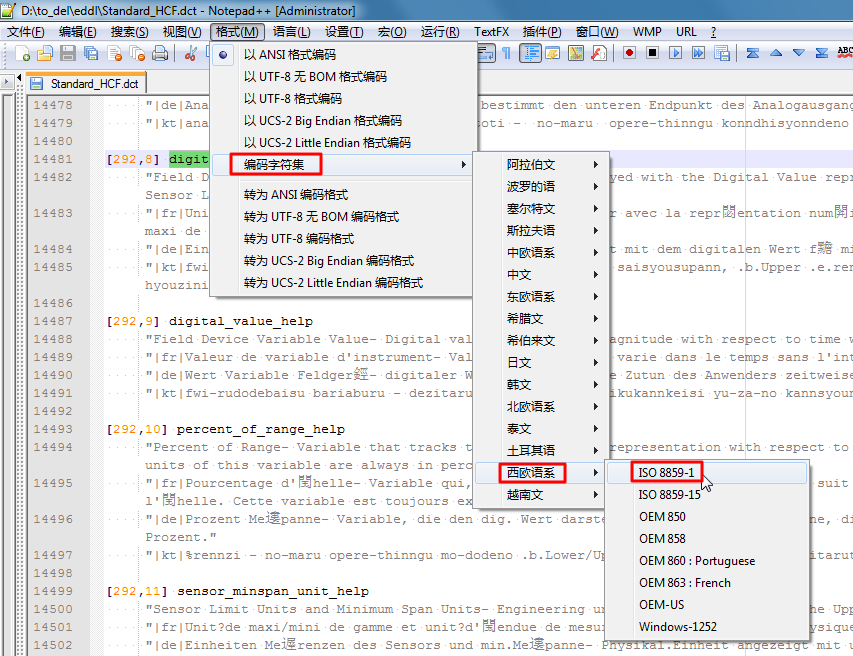 |
然后真的就消除了乱码,可以正常显示出对应的一些特殊的西欧字符了:
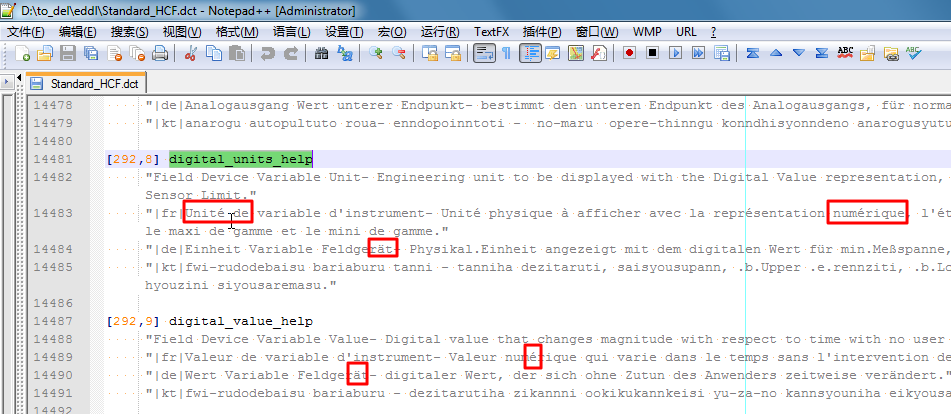 |
此处,很明显,由于对于编码稍微熟悉,所以一次就猜对了编码,而使得快速消除了乱码。
如果,你对于编码不是很熟悉,则可以多去尝试不同的编码,
最后,肯定也还是可以切换到正确的编码,可以正常显示字符的。
而随着对于字符编码的了解越来越深入,则自然会越加熟悉的,越容易一次或几次就猜对文件的正确的编码的。
 |  |  |
| 3.3.2. 用Notepad++选用合适的编码打开对应的文件 |  | 3.3.4. 用Notepad++实现不同字符编码之间的转换 |