【已解决】汽车之家车型车系数据:优化去掉js加速抓取车型参数配置
crifan 4年前 (2020-08-27) 1509浏览 0评论
折腾: 【已解决】汽车之家车型车系数据:抓取车型的详细参数配置 期间,已经基本上实现了获取参数配置数据了。 但是有个问题: 进入参数配置页面时,是通过: # https://car.autohome.com.cn/config/sp...
crifan 4年前 (2020-08-27) 1509浏览 0评论
折腾: 【已解决】汽车之家车型车系数据:抓取车型的详细参数配置 期间,已经基本上实现了获取参数配置数据了。 但是有个问题: 进入参数配置页面时,是通过: # https://car.autohome.com.cn/config/sp...
crifan 4年前 (2020-08-22) 3684浏览 0评论
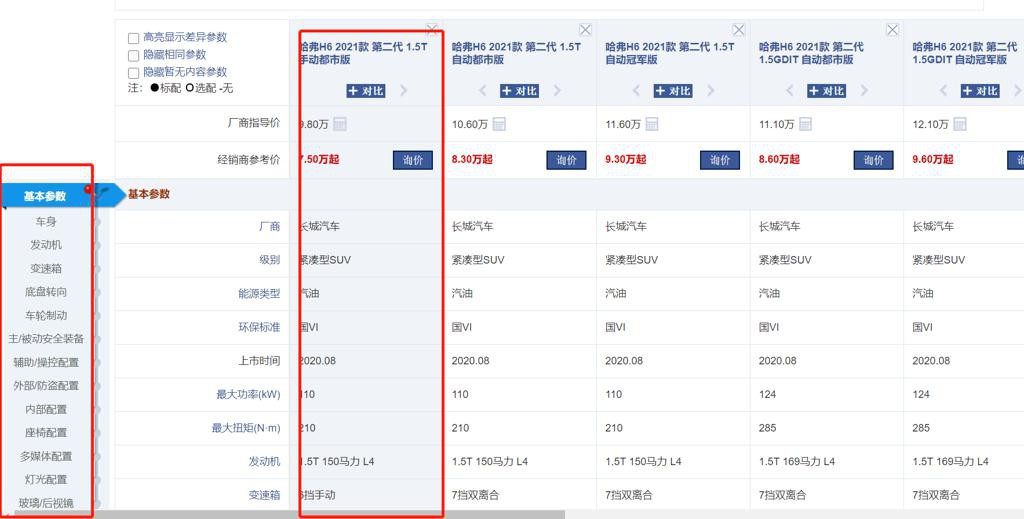
折腾: 【未解决】用Python爬取汽车之家的车型车系详细数据 期间,希望继续去支持:详细参数配置的抓取 类似于这种: 对此: 要去搞清楚:从哪里入手可以打开进入这个页面 以及,是否有比这个页面更好的抓取的地方,如果有,就用新的页面去抓取这些参数...

crifan 4年前 (2020-02-27) 4013浏览 0评论
视频app 数据 视频app 数据 获取 初探抖音的数据采集,竟然简单到无脑! – 简书 抖音APP的视频数据采集方法(简书首发) – 云+社区 – 腾讯云 爬虫—如何抓取app的思路和方案_Pytho...
crifan 6年前 (2018-08-31) 2276浏览 0评论
折腾: 【未解决】用Charles抓取Android的app中的视频数据 期间,问题就转化为: Charles中,抓包看到的xxx这个app中的视频数据,是CONNECT类型的http的请求 所返回的数据,看起来像是二进制的data,但是还是要去搞清...
crifan 6年前 (2018-08-31) 1234浏览 0评论
折腾: 【已解决】抓取手机移动端中app的音视频数据 期间,已经可以用Charles去抓取Android的app中的数据了 接着就是研究具体数据的包,看看如何得到我们希望的 xxx中的视频。 去打开视频页面: 我会继续比赛: 对应抓包出来的请...
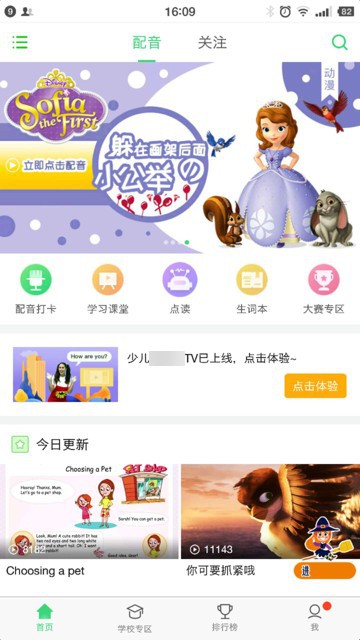
crifan 6年前 (2018-08-28) 2760浏览 0评论
需求: 想要抓取移动端的app中的音视频数据 比如此处的安卓中某app中有很多配音的视频: 想要爬取下来。 对于移动端app,不论是ios还是Android,都应该是类似的逻辑。 ios app 抓包 十分钟学会Charles抓包(iO...
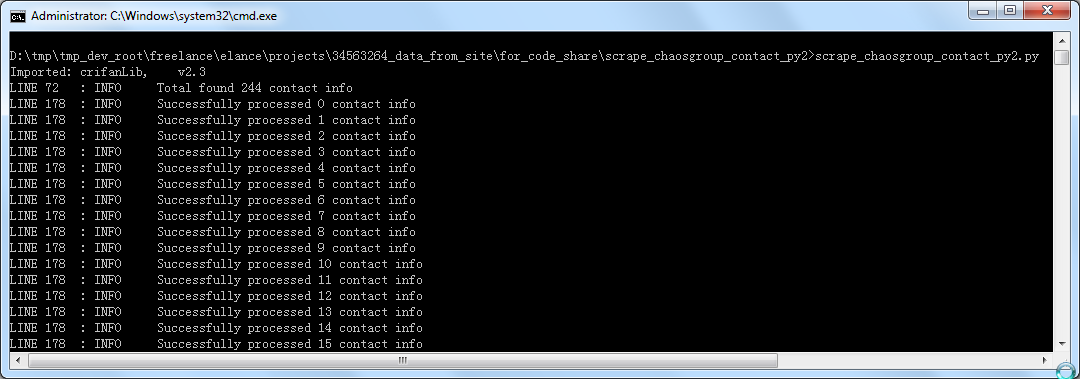
crifan 11年前 (2013-09-23) 2752浏览 0评论
背景】 之前写的,前后共写了两个版本的: Python 2.x版本 和 Python 3.x版本 去抓取 http://www.chaosgroup.com/ 中联系人信息,并保存为excel文件 【scrape_ch...
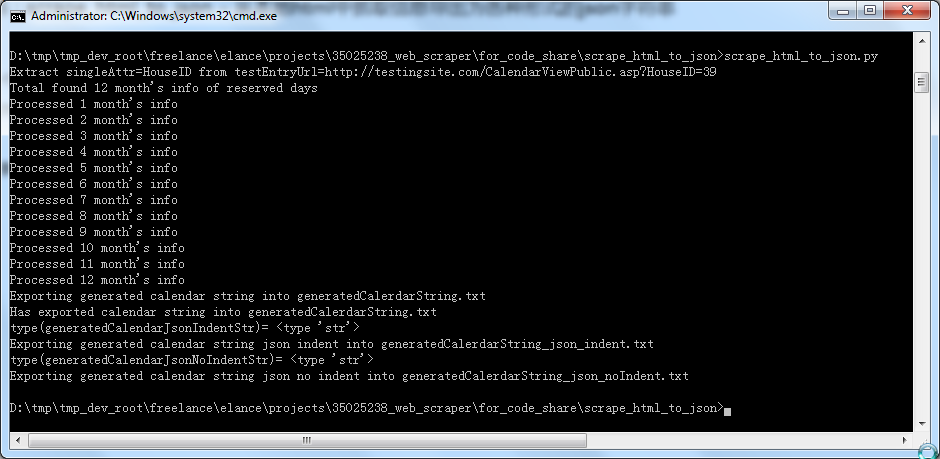
crifan 11年前 (2013-09-23) 2435浏览 0评论
背景】 之前写的,去处理本地已有的一个html文件, 然后对于提取出来的信息,导出为,各种形式的json字符串。 【scrape_html_to_json代码分享】 1.截图: (1)运行效果: (2)输出的各种json字符...
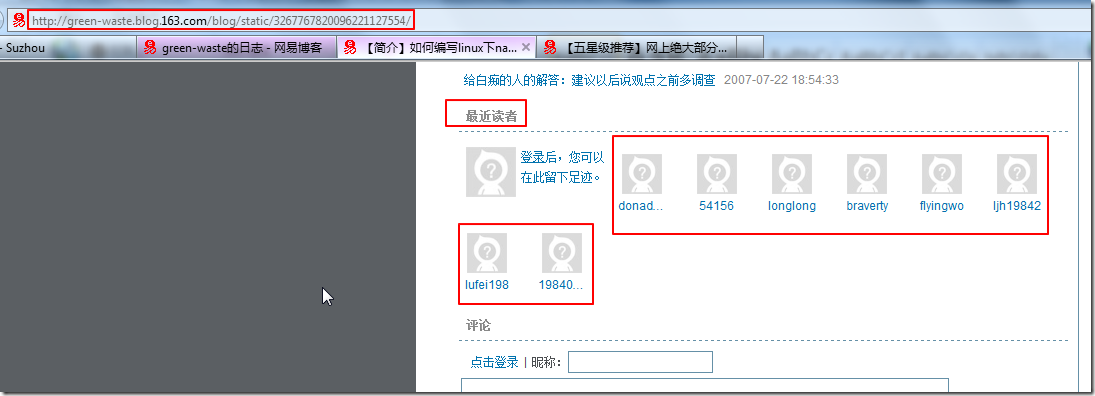
crifan 11年前 (2013-09-22) 9275浏览 9评论
背景 前面已经通过: 【教程】如何抓取动态网页内容 介绍了,关于抓取动态网页中的内容的逻辑过程。 下面通过具体的例子,来说明是如何实现此过程的。 前提知识 1.了解网页抓取等的基本背景知识 不了解的去参考: 【整理】关于抓取网页,分析网页内容,模拟登...
crifan 11年前 (2013-04-30) 5071浏览 1评论
【背景】 之前写过很多网页抓取方面的教程了。全都整理到这里了: 详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等) 现遇到别人问的问题: python 抓取动态网页的问题 即,如何分析和抓取: http://vip.stock....