【代码分享】Python代码:37959390_data_scraping_from_website – 下载www.autopartoo.com中图片并保存图片信息为csv
crifan 13年前 (2013-09-23) 3467浏览
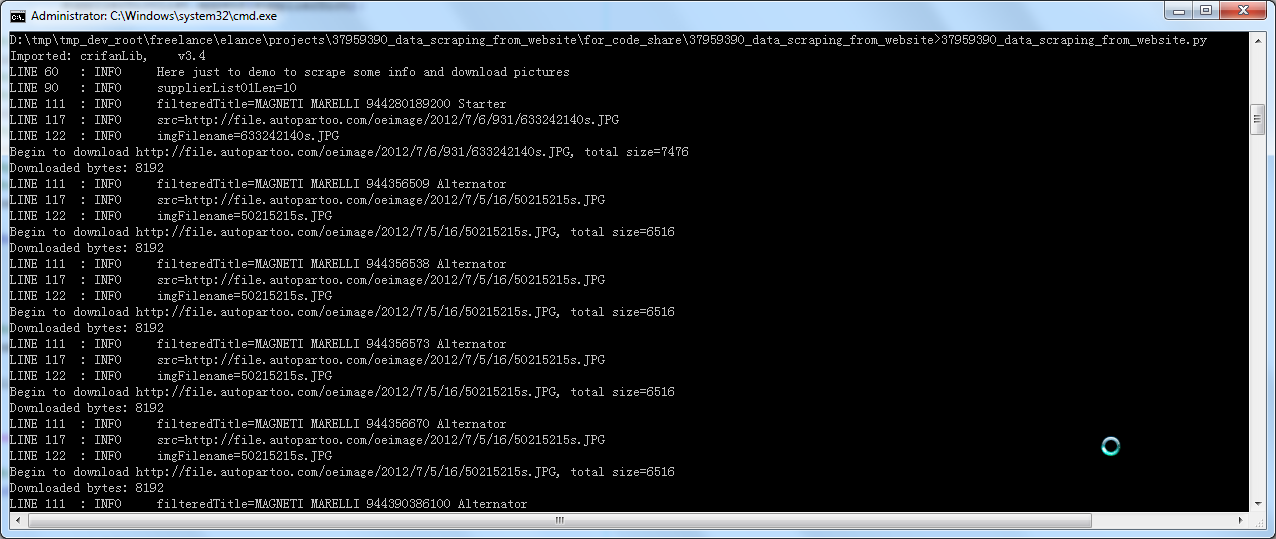
【背景】 之前写的,去下载: http://www.autopartoo.com 中的图片,并且保存图片信息为csv文件。 【37959390_data_scraping_from_website代码分享】 1.截图: (1...
crifan 13年前 (2013-09-23) 3467浏览
【背景】 之前写的,去下载: http://www.autopartoo.com 中的图片,并且保存图片信息为csv文件。 【37959390_data_scraping_from_website代码分享】 1.截图: (1...
crifan 13年前 (2013-09-23) 2413浏览
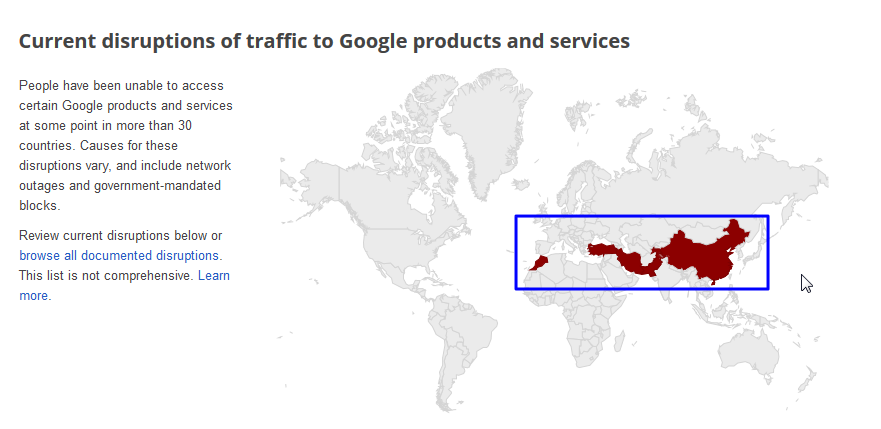
之前无意间发现, 关于google,其提供了各种服务 当然最常用的就是google搜索, 而这些服务,对于有些国家或地区, 出于各种原因而无法访问 比如天朝的长城,你懂的 其他有些还有因为某人在网上骂该某某,而被政府看着不爽,而禁了google的(当...
crifan 13年前 (2013-09-23) 2431浏览
【背景】 之前折腾docbook时,就看过此篇文章: DocBook 助你完成传世之作 之后,又看到过,该文章,只是worldhello: http://www.worldhello.net/doc/ 中的其中一个。 【技术趣闻】 之后,无意间发现,...

crifan 13年前 (2013-09-22) 3005浏览
【背景】 之前写了很多docbook。 已发布至: https://www.crifan.com/files/doc/docbook/ 现在,想要: 如果可以实现,把现有的docbook 即一堆的xml(和相关的xls和其他配置) 转换为wiki格式的...
crifan 13年前 (2013-09-22) 6912浏览
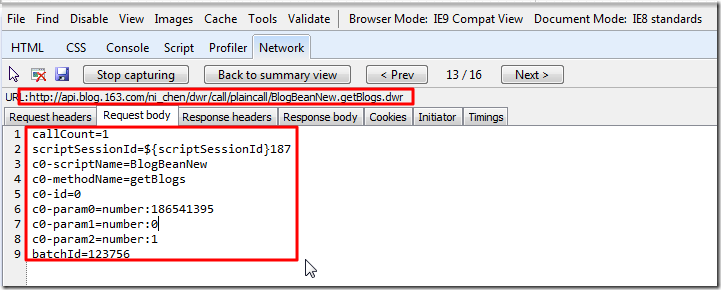
【背景】 之前的 BlogsToWordpress 不支持网易的心情随笔。 现在去添加此功能。 【解决过程】 1.结果使用: BlogsToWordpress.py -s http://blog.163.com/ni_chen 竟然结果连...
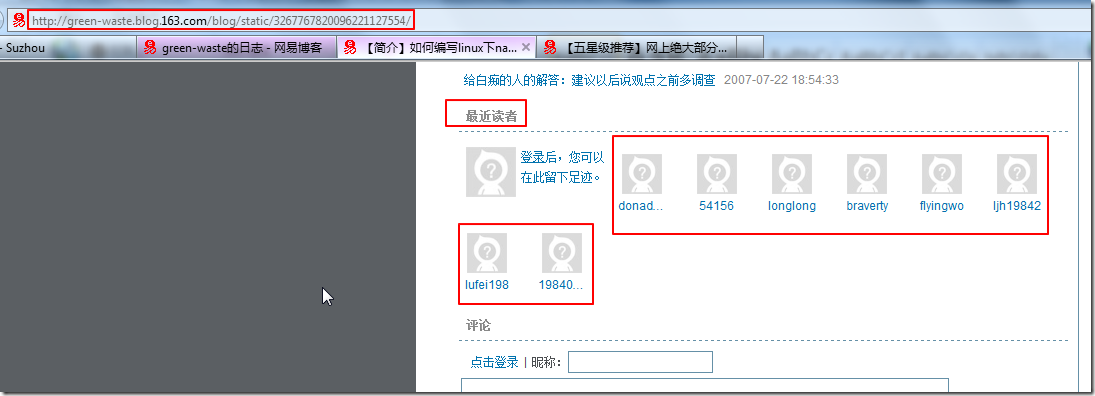
crifan 13年前 (2013-09-22) 11186浏览
背景 前面已经通过: 【教程】如何抓取动态网页内容 介绍了,关于抓取动态网页中的内容的逻辑过程。 下面通过具体的例子,来说明是如何实现此过程的。 前提知识 1.了解网页抓取等的基本背景知识 不了解的去参考: 【整理】关于抓取网页,分析网页内容,模拟登...
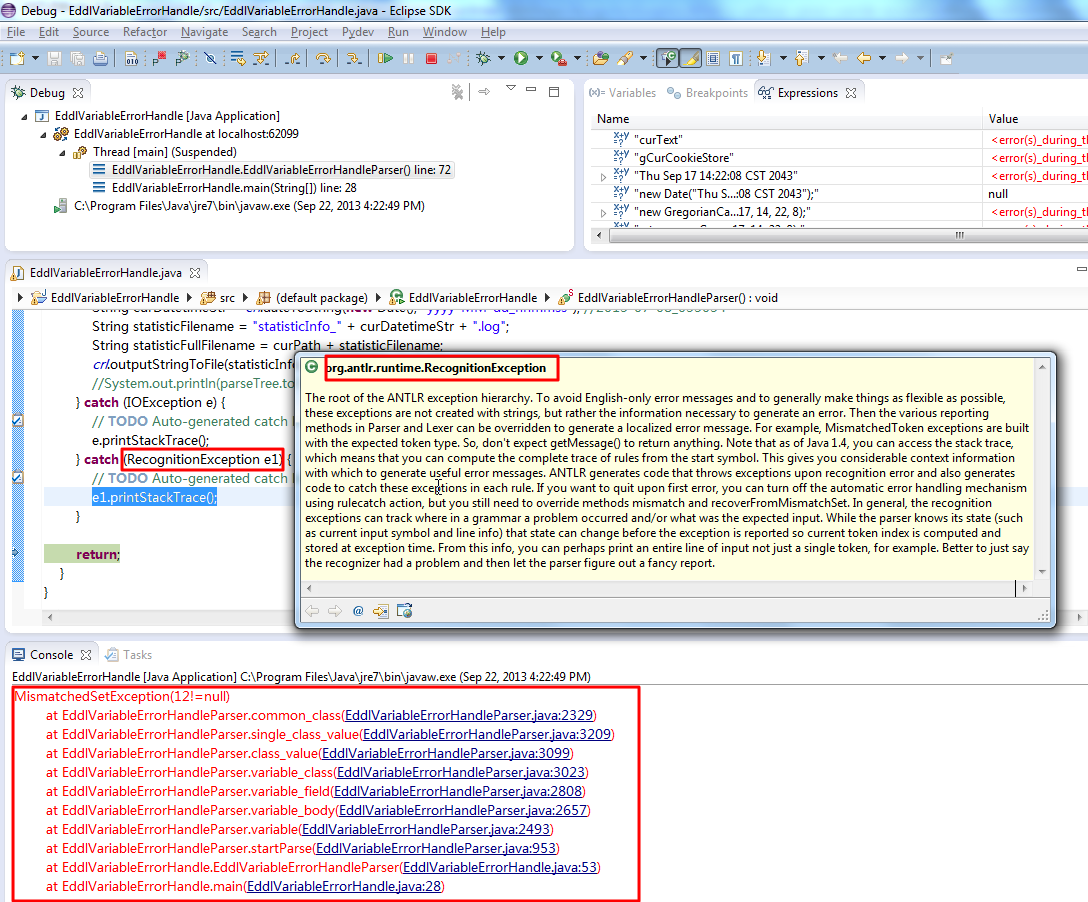
crifan 13年前 (2013-09-22) 4727浏览
【背景】 之前折腾了一些一些关于antlr的异常处理了: 【记录】尝试折腾antlr v3的异常处理和错误恢复:VARIABLE的CLASS的值INPUT故意写错为INPUT1 【记录】折腾antlr的异常处理:使得当初错时,输出更详细的错误信息,包...

crifan 13年前 (2013-09-22) 2708浏览
小苏打粉是超好用的天然除臭剂,如果你常用小苏打溶液当清洁剂清洗餐具、炊具时,可以避免洗槽排水产生臭味;若排水管堵塞时,可将一杯小苏打粉倒入,再注入热水,就可解决! 清洁餐具 以抹布或植物菜瓜布沾小苏打溶液洗涤碗筷餐具,可迅速而切实...
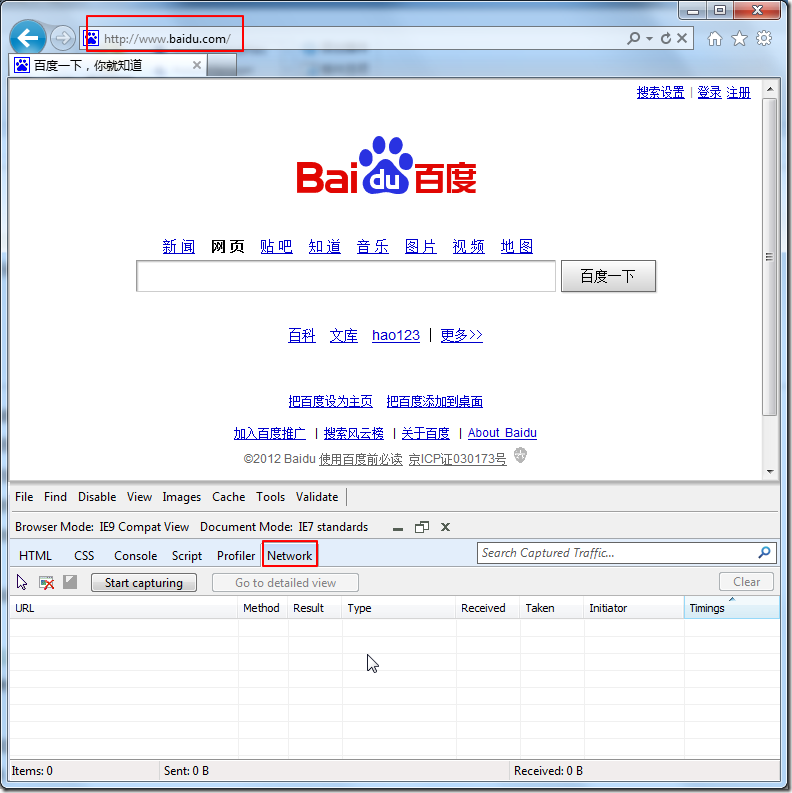
crifan 13年前 (2013-09-22) 40770浏览
重要提示: 1.此贴,以后不再更新; 2.想要看更新的内容,请移至: 详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等) 【前提】 想要实现使用某种语言,比如Python,C#等,去实现模拟登陆网站的话,首先要做...
crifan 13年前 (2013-09-22) 30126浏览
【背景】 问题参见: python2.7 urllib2 抓取新浪乱码 中的: 报错的异常是 UnicodeDecodeError: ‘gbk’ codec can’t decode...