现有srt的文本字幕文件,很多都是UTF-8的编码的:
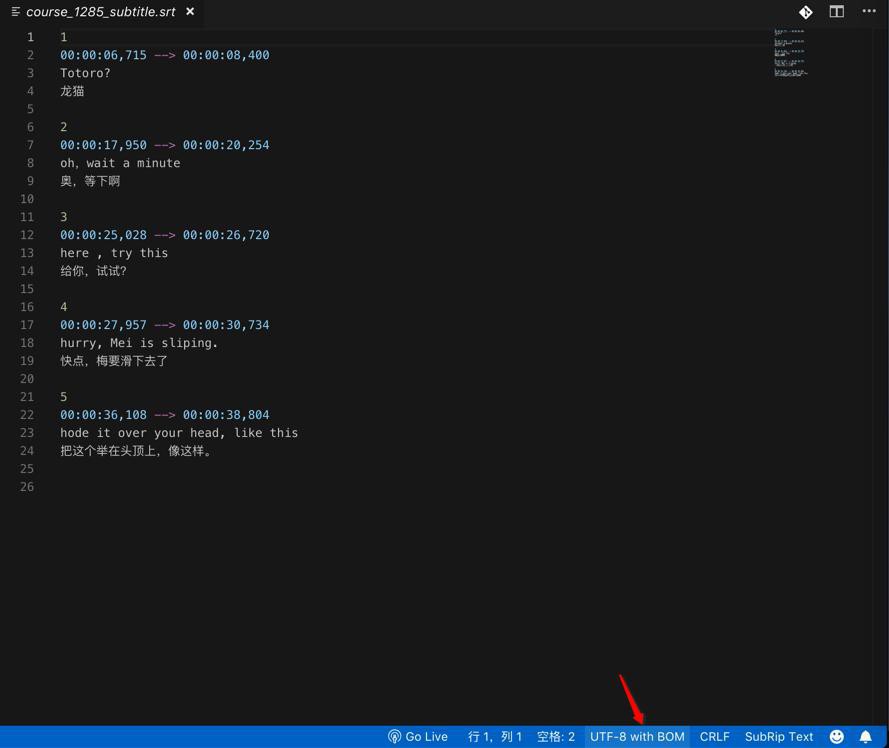
所以调用:
subtitleList = pysrt.open(subtitleFullPath, encoding="utf-8")
去打开是没问题的。
但是后来发现偶尔会是别的字符编码的,比如UTF-16 LE的:
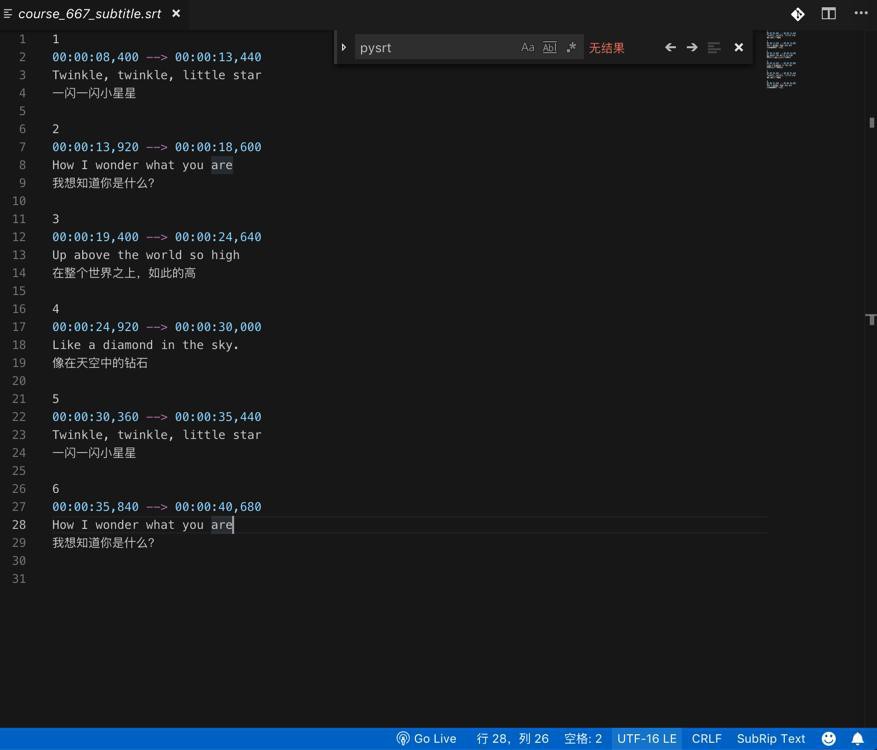
然后就会报错。
所以此处需要去:想办法检测出文件编码格式,然后再传入编码,再去解析,就不会出错了
python 文件 字符编码 检测
python 字符编码 检测
结果代码:
with open(eachFile,'r') as eachFp:
print("eachFp=%s" % eachFp)
fileContentStr = eachFp.read()
print("fileContentStr=%s" % fileContentStr)
detectedResult = chardet.detect(fileContentStr)调试出错:
发生异常: UnicodeDecodeError 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte File "/Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/charsetDetectDemo.py", line 25, in demoDetectFileCharset fileContentStr = eachFp.read()
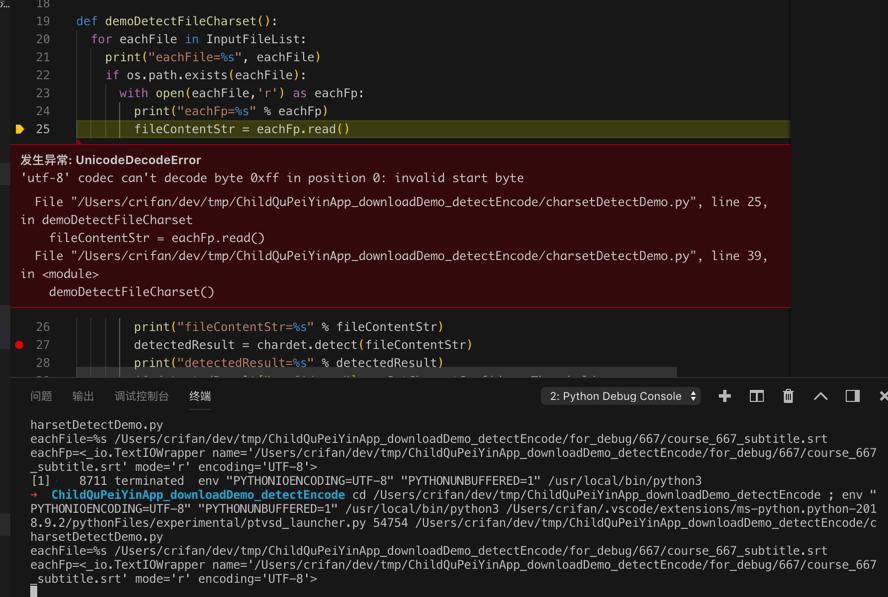
此处就尴尬了:
对于:希望用chardet去检测文件的编码,用于调用pysrt.open时指定正确编码,正确解析字幕信息
而此处用chardet时,先要获取文件编码信息,才能正确open文件,否则又会报错
而想要文件的正确的编码信息,却又不知道,想要通过chardet去获取
所以就成死循环了。。。
最后,参考:
突然想到,去试试rb的open,或许可以获取的是文件的二进制数据?或许就可以了?
最后换用rb去open后再read,即可获取文件的二进制,再去detect,即可得到结果。
【总结】
最后用代码:
import os
import chardet
import pysrt
SrtCharsetConfidenceThreshold = 0.8
InputFileList = [
# UTF-16 LE
"/Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/for_debug/667/course_667_subtitle.srt",
# UTF-8 With BOM
"/Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/output/course/1285/course_1285_subtitle.srt",
# UTF-8 With BOM
"/Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/output/course/36310/course_36310_subtitle.srt",
]
def demoDetectFileCharset():
for eachFile in InputFileList:
print("eachFile=%s", eachFile)
if os.path.exists(eachFile):
# with open(eachFile,'r') as eachFp:
with open(eachFile, 'rb') as eachFp:
print("eachFp=%s" % eachFp)
fileContentStr = eachFp.read()
# print("fileContentStr=%s" % fileContentStr)
detectedResult = chardet.detect(fileContentStr)
print("detectedResult=%s" % detectedResult)
# {'encoding': 'UTF-16', 'confidence': 1.0, 'language': ''}
# {'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}
if detectedResult["confidence"] >= SrtCharsetConfidenceThreshold:
possibleEncoding = detectedResult["encoding"]
print("possibleEncoding=%s" % possibleEncoding) # UTF-8-SIG
subtitleList = pysrt.open(eachFile, encoding=possibleEncoding)
print("subtitleList=%s" % subtitleList)
else:
print("Invalid charset %s for srt file %s" % (detectedResult, eachFile))
if __name__ == "__main__":
demoDetectFileCharset()输出:
➜ xxx_downloadDemo_detectEncode cd /Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode ; env "PYTHONIOENCODING=UTF-8" "PYTHONUNBUFFERED=1" /usr/local/bin/python3 /Users/crifan/.vscode/extensions/ms-python.python-2018.9.2/pythonFiles/experimental/ptvsd_launcher.py 58920 /Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/charsetDetectDemo.py
eachFile=%s /Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/for_debug/667/course_667_subtitle.srt
eachFp=<_io.BufferedReader name='/Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/for_debug/667/course_667_subtitle.srt'>
detectedResult={'encoding': 'UTF-16', 'confidence': 1.0, 'language': ''}
possibleEncoding=UTF-16
subtitleList=[<pysrt.srtitem.SubRipItem object at 0x10900c0b8>, <pysrt.srtitem.SubRipItem object at 0x10900c160>, <pysrt.srtitem.SubRipItem object at 0x10900c198>, <pysrt.srtitem.SubRipItem object at 0x10900c240>, <pysrt.srtitem.SubRipItem object at 0x10900c278>, <pysrt.srtitem.SubRipItem object at 0x10900c0f0>]
eachFile=%s /Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/output/course/1285/course_1285_subtitle.srt
eachFp=<_io.BufferedReader name='/Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/output/course/1285/course_1285_subtitle.srt'>
detectedResult={'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}
possibleEncoding=UTF-8-SIG
subtitleList=[<pysrt.srtitem.SubRipItem object at 0x10900c8d0>, <pysrt.srtitem.SubRipItem object at 0x10900cd68>, <pysrt.srtitem.SubRipItem object at 0x10900c908>, <pysrt.srtitem.SubRipItem object at 0x10900c080>, <pysrt.srtitem.SubRipItem object at 0x10900c6d8>]
eachFile=%s /Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/output/course/36310/course_36310_subtitle.srt
eachFp=<_io.BufferedReader name='/Users/crifan/dev/tmp/xxx_downloadDemo_detectEncode/output/course/36310/course_36310_subtitle.srt'>
detectedResult={'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}
possibleEncoding=UTF-8-SIG
subtitleList=[<pysrt.srtitem.SubRipItem object at 0x10900c588>, <pysrt.srtitem.SubRipItem object at 0x10900c2e8>, <pysrt.srtitem.SubRipItem object at 0x10900c0b8>, <pysrt.srtitem.SubRipItem object at 0x10900c320>, <pysrt.srtitem.SubRipItem object at 0x10900c438>]其中:
- UTF-16 LE 编码,detect出来是:UTF-16
- UTF-8 With BOM编码detect处理是:UTF-8-SIG
转载请注明:在路上 » 【已解决】Python中检测文件的字符编码