【已解决】Python中用正则re去搜索分组的集合
crifan 8年前 (2018-07-16) 3512浏览
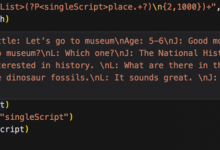
折腾: 【已解决】Python 3中用正则匹配多段的脚本内容 期间,想要对于这种: 去匹配到: 多个script 即分组的分组 结果用: <code>scriptMatch = re.search("(?P<sc...
工作相关的技术文章
crifan 8年前 (2018-07-16) 3512浏览
折腾: 【已解决】Python 3中用正则匹配多段的脚本内容 期间,想要对于这种: 去匹配到: 多个script 即分组的分组 结果用: <code>scriptMatch = re.search("(?P<sc...
crifan 8年前 (2018-07-16) 7242浏览
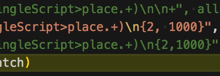
折腾: 【已解决】把文本格式的剧本内容用Python批量导入后台系统 期间,就是去写正则去匹配这种内容: <code>Place: School canteen Topic: food Tittle:Have lunch Age: 3-4...
crifan 8年前 (2018-07-16) 3067浏览
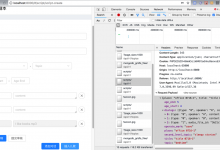
需要把文本格式的: 已编写的对话剧本 去用Python脚本处理,实现批量导入到系统中 而原本是手动的录入到系统中的: 所以去搞清楚 调用了后台的接口是: 1. Request URL: http://localhost:65000/api/v1/...
crifan 8年前 (2018-07-15) 1504浏览
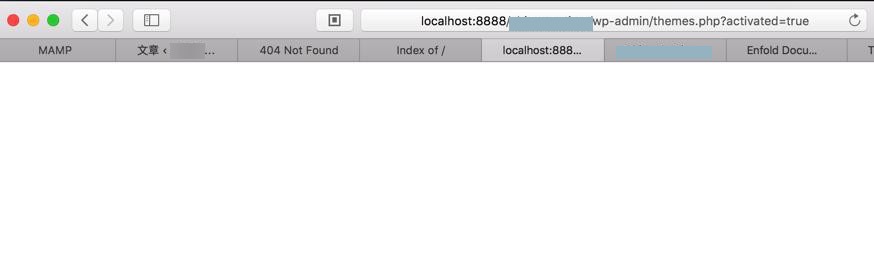
折腾: 【未解决】Wordpress中安装和配置Enfold主题 期间,上传并启用Enfold主题后,出现白屏 http://localhost:8888/xxx/ 调试看到,一闪而过后,加载了3个img图片数据 通过保留日志看到: Fail...
crifan 8年前 (2018-07-13) 10269浏览
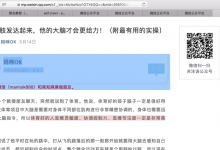
别人在发布文字,由于是转载 了一篇帖子过来,比如: 先让娃四肢发达起来,他的大脑才会更给力!(附最有用的实操) https://mp.weixin.qq.com/s?__biz=MzAwNzc1OTY4OQ==&mid=2651054302...
crifan 8年前 (2018-07-13) 6934浏览
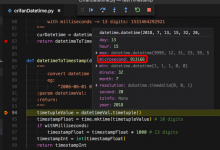
折腾: 【已解决】PySpider中下载mov文件出错:requests.exceptions.HTTPError HTTP 403 Forbidden 期间,需要去获取带毫秒的13位数的时间戳,比如: <code>#(2)http://...
crifan 8年前 (2018-07-13) 3420浏览
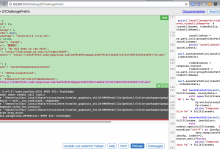
在尝试用PySpider去下载: http://xxx/Prelim 中的mov视频,比如: { "fetch": { "cookies": {}, "save": { ...
crifan 8年前 (2018-07-13) 3881浏览
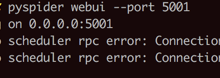
折腾: 【无法解决】PySpider的部署运行而非调试界面上RUN运行 期间,看看通过使用不同端口,实现避开多个PySpider的项目去运行和调试 (虽然理论上可以实现,用单个PySpider的WebUI界面中去管理多个spider,但是此处由于项目...
crifan 8年前 (2018-07-13) 2580浏览
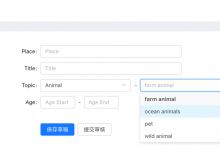
希望手动操作mysql,实现添加一个二级的topic 比如: 在一级topic:Animal 里加一个二级topic:ocean animals 而现有的一级topic的Animal中是没有这个二级topic,所以界面上是选择不出来的: 然后先去备...
crifan 8年前 (2018-07-13) 5536浏览
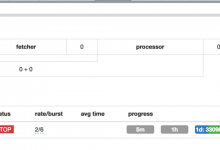
折腾: 【已解决】使用PySpider去爬取某网站中的视频 后,虽然可以打开: http://0.0.0.0:5000/ 在界面上把status改为DEBUG或RUN去运行,但是有些爬虫要爬完所有内容需要很长时间,比如此处:但是界面上调试运行,跑了好...