折腾:
【已解决】从不同版本的小花生apk中反编译出包含业务逻辑代码的dex和jar包源码
期间,已经得到了,我们想要的,包含业务逻辑的代码。
再去从jd-gui中导出全部代码:
用VSCode打开:
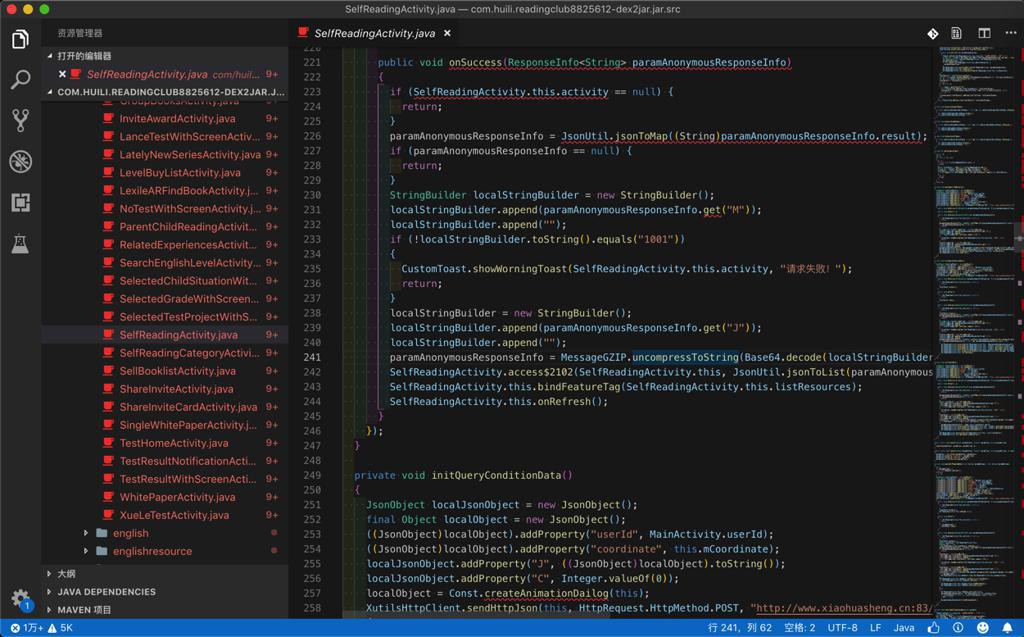
其中一个相关函数的代码是:
private void getSupportingResources()
{
JsonObject localJsonObject1 = new JsonObject();
JsonObject localJsonObject2 = new JsonObject();
localJsonObject2.addProperty("userId", MainActivity.userId);
localJsonObject2.addProperty("fieldName", this.mFieldName);
localJsonObject2.addProperty("fieldValue", this.mFieldValue);
localJsonObject2.addProperty("grade", this.mGrades);
localJsonObject2.addProperty("level", this.mLevels);
localJsonObject1.addProperty("J", localJsonObject2.toString());
localJsonObject1.addProperty("C", Integer.valueOf(0));
XutilsHttpClient.sendHttpJson(this, HttpRequest.HttpMethod.POST, "
http://www.xiaohuasheng.cn:83/Reading.svc/getSupportingResourcesInSelfReadingBookQueryCondition
", localJsonObject1.toString(), new RequestCallBack()
{
public void onFailure(HttpException paramAnonymousHttpException, String paramAnonymousString) {}
public void onStart() {}
public void onSuccess(ResponseInfo<String> paramAnonymousResponseInfo)
{
if (SelfReadingActivity.this.activity == null) {
return;
}
paramAnonymousResponseInfo = JsonUtil.jsonToMap((String)paramAnonymousResponseInfo.result);
if (paramAnonymousResponseInfo == null) {
return;
}
StringBuilder localStringBuilder = new StringBuilder();
localStringBuilder.append(paramAnonymousResponseInfo.get("M"));
localStringBuilder.append("");
if (!localStringBuilder.toString().equals("1001"))
{
CustomToast.showWorningToast(SelfReadingActivity.this.activity, "请求失败!");
return;
}
localStringBuilder = new StringBuilder();
localStringBuilder.append(paramAnonymousResponseInfo.get("J"));
localStringBuilder.append("");
paramAnonymousResponseInfo = MessageGZIP.uncompressToString(Base64.decode(localStringBuilder.toString()), "UTF-8");
SelfReadingActivity.access$2102(SelfReadingActivity.this, JsonUtil.jsonToList(paramAnonymousResponseInfo));
SelfReadingActivity.this.bindFeatureTag(SelfReadingActivity.this.listResources);
SelfReadingActivity.this.onRefresh();
}
});
}其中的
XutilsHttpClient.sendHttpJson
的onSuccess
中的
localStringBuilder = new StringBuilder();
localStringBuilder.append(paramAnonymousResponseInfo.get("J"));
localStringBuilder.append("");
paramAnonymousResponseInfo = MessageGZIP.uncompressToString(Base64.decode(localStringBuilder.toString()), "UTF-8");
SelfReadingActivity.access$2102(SelfReadingActivity.this, JsonUtil.jsonToList(paramAnonymousResponseInfo));
SelfReadingActivity.this.bindFeatureTag(SelfReadingActivity.this.listResources);
SelfReadingActivity.this.onRefresh();就是解码,解密相关的逻辑。
去研究看看,然后尝试用Python代码实现。
首先去找:
paramAnonymousResponseInfo = MessageGZIP.uncompressToString(Base64.decode(localStringBuilder.toString()), "UTF-8");
中的:
MessageGZIP
uncompressToString
Base64.decode
去看了看代码:
com/huili/readingclub/utils/MessageGZIP.java
public static String uncompressToString(byte[] paramArrayOfByte, String paramString)
{
if ((paramArrayOfByte != null) && (paramArrayOfByte.length != 0))
{
ByteArrayOutputStream localByteArrayOutputStream = new ByteArrayOutputStream();
Object localObject = new ByteArrayInputStream(paramArrayOfByte);
try
{
paramArrayOfByte = new java/util/zip/GZIPInputStream;
paramArrayOfByte.<init>((InputStream)localObject);
localObject = new byte['Ā'];
for (;;)
{
int i = paramArrayOfByte.read((byte[])localObject);
if (i < 0) {
break;
}
localByteArrayOutputStream.write((byte[])localObject, 0, i);
}
paramArrayOfByte = localByteArrayOutputStream.toString(paramString);
return paramArrayOfByte;
}
catch (IOException paramArrayOfByte)
{
paramArrayOfByte.printStackTrace();
return null;
}
}
return null;
}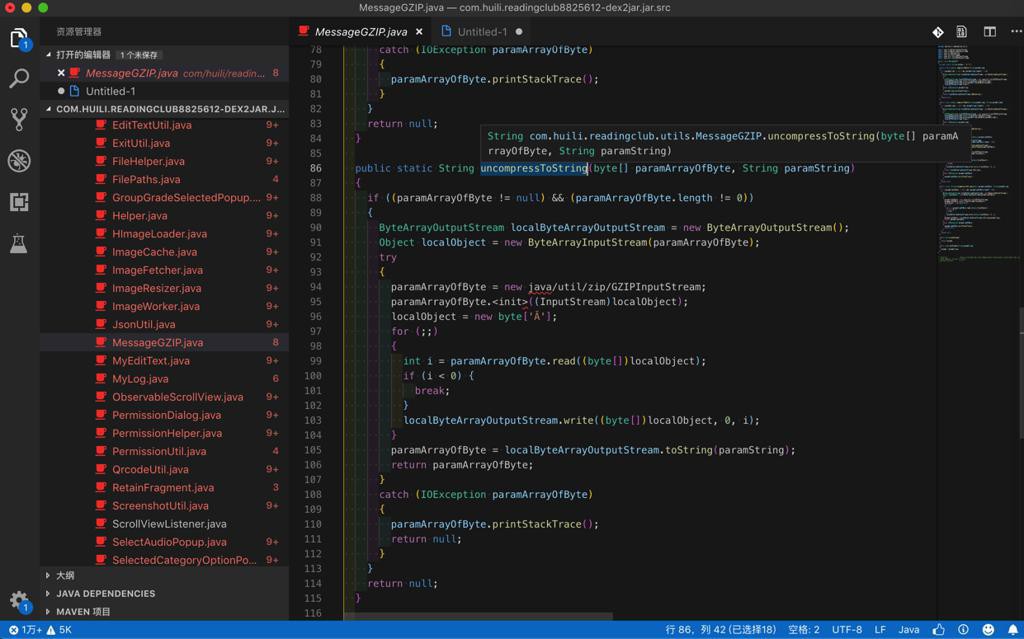
感觉好像只是:
1.先经过Base64.decode的解码
2.再去用gzip解压
就可以了?
而Base64.decode的源码是:
com/huili/readingclub/utils/Base64.java
package com.huili.readingclub.utils;
import java.util.Arrays;
public class Base64
{
private static final char[] CA = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".toCharArray();
private static final int[] IA = new int['Ā'];
static
{
Arrays.fill(IA, -1);
int i = CA.length;
for (int j = 0; j < i; j++) {
IA[CA[j]] = j;
}
IA[61] = 0;
}
public static final byte[] decode(String paramString)
{
if (paramString != null) {
i = paramString.length();
} else {
i = 0;
}
if (i == 0) {
return new byte[0];
}
int j = 0;
for (int k = 0; j < i; k = m)
{
m = k;
if (IA[paramString.charAt(j)] < 0) {
m = k + 1;
}
j++;
}
j = i - k;
if (j % 4 != 0) {
return null;
}
int m = 0;
while (i > 1)
{
localObject = IA;
k = i - 1;
if (localObject[paramString.charAt(k)] > 0) {
break;
}
i = k;
if (paramString.charAt(k) == '=')
{
m++;
i = k;
}
}
int n = (j * 6 >> 3) - m;
Object localObject = new byte[n];
k = 0;
int i = 0;
while (k < n)
{
m = 0;
j = 0;
while (m < 4)
{
i1 = IA[paramString.charAt(i)];
if (i1 >= 0) {
j = i1 << 18 - m * 6 | j;
} else {
m--;
}
m++;
i++;
}
int i1 = k + 1;
localObject[k] = ((byte)(byte)(j >> 16));
m = i1;
if (i1 < n)
{
k = i1 + 1;
localObject[i1] = ((byte)(byte)(j >> 8));
m = k;
if (k < n)
{
m = k + 1;
localObject[k] = ((byte)(byte)j);
}
}
k = m;
}
return (byte[])localObject;
}或许,好像,就是常见的,base64的decode?
不过刚注意到顶部还有:
private static final char[] CA = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".toCharArray();
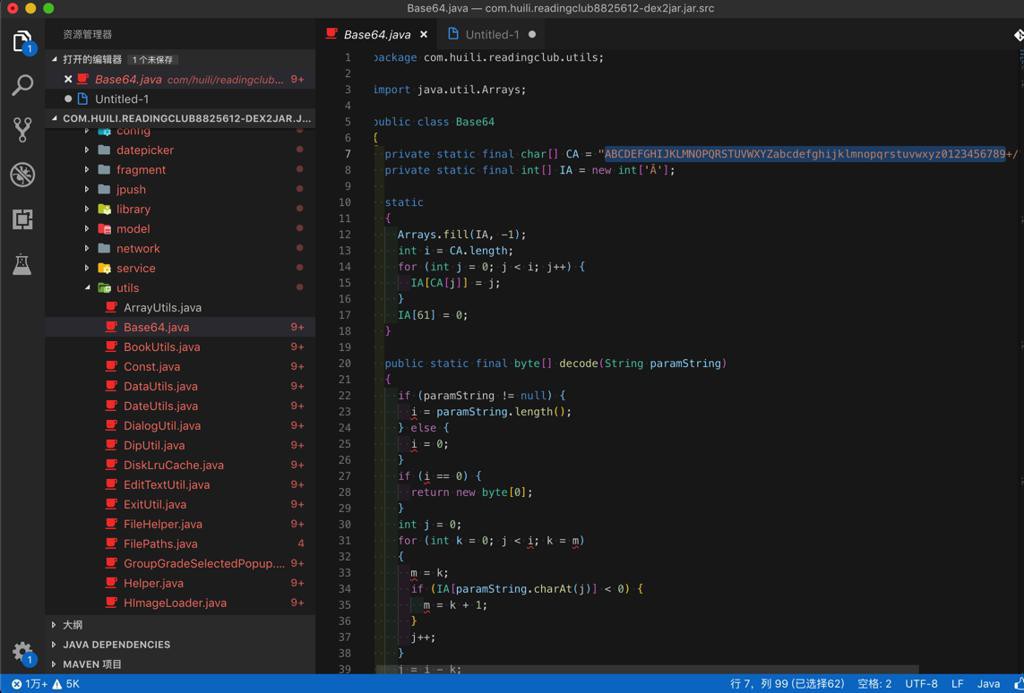
或许对解码有用?必不可少的?
不论如何,先去研究一下:
【已解决】Python中实现java中的Base64.decode解码加密字符串
然后去:
【已解决】python实现java的MessageGZIP.uncompressToString即gzip的解码
【总结】
至此,之前此处的java的:
paramAnonymousResponseInfo = MessageGZIP.uncompressToString(Base64.decode(localStringBuilder.toString()), "UTF-8");
用Python实现是:
import base64
import gzip
encodedStr = "H4sIAAAAAAAEALVXW0\/bSBj9K1Ze9oVdYjtOnD6WbbdoL0SlfVrtg5tMg7eJjWynW7SqFFbcuqQQSrmkgdJCubRLCiy3XEHqT6k8Y+epf2E\/xyFXmy2VKkWRx554vjlnzjlffv3TM\/zAc43zMj2e8JAoIRXdEbUY8lzz4NIirrwlq7Pm9IG5l8PpPfNZRi9s4acLnh4PkqIxUR26mAx37iuypPXJD5EC48ERVUPx3hv2rEGkiEgNiWEtoaBexkvzNM0wtJflaT8fDHz3+3AUXnBPlh\/0yQlJ81yjmWCPRxOiKrwK1iZja3itgMdL1IdTyigtk5Xd6vK4uVcb24WZ798Ya5u158\/XyFGJTKWrC+fN+dZVdfWlmXlBXo5ZA\/sKllUT8bigjPRLAxIaRJKGpLC1o4\/JFeP5Dll5gjf2rV2nd\/FksQ7F39mPyVXrp3IsMpCw6n3cYwPJ0t04ju8bmRKemjCK23bV3fANamiY6pc0mbqNhIgoRTvxrAP5E3qIYjcbDwaUfklCSkiIot5AsBfvj1ZX1x3Q9AZ6PEIiIsr1GyzrbcDbWpiFSwhKS4gSdVuQInKcuiUnVFSDuTYPJrmDaV0BYNW1w+r6XO03s3vGXwV7x3FRCimiBS3L8zAUHtWHviCcPVkRo40JPON1pcU4m8HZip4vkePRRknGk7eeCwY4OthNQfqILMwCEV\/nKLPwzfiZAO\/zOR1l+suP8vYczm01n1\/1aDcxZyxBNTGvDdsw93H8ZVIwJ98ZYydQNixug2hXVZdCA3yLuQ7wycE72LExW\/maPuLz+gN0N\/gM4\/188DuE8H++0imIJhkO+NNM25mnLQm04c8EuMvwt8vGubc4lzZejAGUZHHSTB6SleNW\/IMO9pM9A7CrWxPGIZjQUjfkd4YQdVe9JysSunAfKqTIUUWIx9HVfYhnfa5GxLGutnNRQShxz1rAKsIBYwefabcWv78VZtYCtQ1mmgv6XXEmy\/OwFJwTcyeJn6X08rKxnSQL43pxGjC3nGcrY5TmcXqqAThr8dqBONBFpub08gt4mV6cAH7M41OS24Sd6IXp6mYZF\/41ph2Y6Kf6BKnGAfXzCHVTVFSNqiFNXRfVcELUrs4GwzPuscC3p4I1dmHnlqAMI6VPjsVESf18Ytqg93vdXR2\/P8GLoK1TkpmvQ52ttNr7p3JKLxbhAlfWzYPXthDwm21j6sA5h30OQqhYy6zsG+kJvD+Hx84vz+RfBE2UJSFG\/YAsMQwPiWHqRzGi1ghCinp1MmiGcyUjyLmC35kCToXdiCTCtduXRnV7JNBcq1Y4plMrftpdKnizUh1dIhNnQIx12Eu7eH+WLJ3gZEbPPyXZMzgGZKUIIiAzm+b2lnmeIa9OgVrwok\/l0YZ+fBzXRZTxJEuONu39kldzeGq1unzSzc\/Ao\/uyEmlY1h0Fobpa6G\/Zy3OkgyM7SbwsDWkCHWmA5xzEEmyqww5DMl12SY56ZXclEV6uitoI+ClSHXXj3CHRbFta82yXjfkD7mICunE+j2eXyO66eT5jx0Ujsc3zLMCJx3fIYoG8bjqZL9Ad3ZbAUv+0bg8XypZwsrluPi7c4boYBR\/TgJgwGraO5NWF4qdddcJ3mBbvblr2Fajd3N6wxhcFfp5W2l2tmhmzXa3v+\/oQvAQaAZKaxHvl9gwKtpHnYzqjng5aHa+bsMZ37KAGzizHym2RV6\/tdreuiIUMWU03afN2BxAwRHKp6tox9Ajk6CV8QHUOhMUEVQXvuA7oqtQfojYE3X4MdRmbg3ZaAqYmHToA3ywDbbDTnzn+ixvgviExFvlGpUIxYcSpx6pxUdunu5iY9r8bTFfrxQUu8bn9CWNjx2609PyMjaZ5soHnDvXKfPVdCpoBvZjS80U9n\/Q8\/u0\/UDEtQFAPAAA="
decodedStr = base64.b64decode(encodedStr)
print("decodedStr=%s" % decodedStr)
decompressedStr = gzip.decompress(decodedStr)
print("decompressedStr=%s" % decompressedStr)
decompressedStrUnicode = decompressedStr.decode("UTF-8")
print("decompressedStrUnicode=%s" % decompressedStrUnicode)即可输出得到要的,加密前的,原始的,json字符串:
[{"pk":502,"chineseTitle":"廖彩杏英语启蒙书单","englishTitle":"","frontCover":"System/EnglishSeriesPicture/20181122103816897.jpg","bookCount":129,"tags":"语感培养 · 绘本阅读 · 启蒙认知 · 生活成长 · 绘本 · 非虚构 · 虚构","summaryInOneSentence":"“用有声书听出英语力”","soldOut":1},{"pk":31,"chineseTitle":"兰登分级阅读","englishTitle":"Step Into Reading","frontCover":"EnglishLevelFrontCoverOrInnerPage/79/封面.jpg","bookCount":107,"audioCount":330,"tags":"分级阅读 · Penguin Random House · 分级读本 · 非虚构 · 虚构 · 有音频 · 可点读","minPrice":388,"maxPrice":492,"originPrice":820,"summaryInOneSentence":"美国主流分级读物"},{"pk":519,"chineseTitle":"吴敏兰英语启蒙书单","englishTitle":"","frontCover":"System/EnglishSeriesPicture/20181130182627844.jpg","bookCount":121,"tags":"语感培养 · 绘本阅读 · 启蒙认知 · 科学阅读 · 生活成长 · 绘本 · 非虚构 · 虚构","minPrice":229,"maxPrice":229,"originPrice":458,"summaryInOneSentence":"“自然养成英语阅读力”"},{"pk":520,"chineseTitle":"汪培珽英语启蒙书单","englishTitle":"","frontCover":"System/EnglishSeriesPicture/20181122103840671.jpg","bookCount":220,"tags":"语感培养 · 绘本阅读 · 分级阅读 · 启蒙认知 · 生活成长 · 分级读本 · 绘本 · 虚构","minPrice":128,"maxPrice":188,"originPrice":275,"summaryInOneSentence":"“培养孩子的英文耳朵”"},{"pk":91,"chineseTitle":"图书馆系列","englishTitle":"The Usborne Reading Programme","frontCover":"EnglishLevelFrontCoverOrInnerPage/834/封面.jpg","bookCount":53,"tags":"分级阅读 · Usborne Publishing · 分级读本 · 虚构 · 有音频","minPrice":366,"maxPrice":375,"originPrice":1596,"summaryInOneSentence":"易读语言和优秀故事的美妙结合"},{"pk":328,"chineseTitle":"“我会读了”起步级之饼干狗","englishTitle":"I Can Read My First Level Biscuit","frontCover":"EnglishLevelFrontCoverOrInnerPage/282/封面.jpg","bookCount":18,"audioCount":18,"tags":"分级阅读 · HarperCollins · 分级读本 · 虚构 · 有音频","originPrice":600,"summaryInOneSentence":"家喻户晓的美国分级读物,人物形象孩子大爱","soldOut":1},{"pk":34,"chineseTitle":"国家地理少儿分级阅读","englishTitle":"National Geographic Kids Readers","frontCover":"EnglishLevelFrontCoverOrInnerPage/125/封面.jpg","bookCount":95,"tags":"分级阅读 · 科学阅读 · National Geographic Education · 分级读本 · 非虚构","minPrice":215,"maxPrice":525,"originPrice":616,"summaryInOneSentence":"好遗憾,我们小时候不曾有机会接触这样的书!"},{"pk":455,"chineseTitle":"牛津阅读树初阶","englishTitle":"Oxford Reading Tree Level 1-3","frontCover":"System/EnglishLevelFrontCover/20181031112816785.jpg","bookCount":198,"tags":"自然拼读 · 分级阅读 · Oxford University Press · 分级读本 · 可点读","minPrice":139,"maxPrice":835,"originPrice":1670,"summaryInOneSentence":"非常受欢迎的英语阅读进阶全方案"},{"pk":470,"chineseTitle":"大猫分级阅读幼儿园","englishTitle":"Collins Big Cat Reception","frontCover":"EnglishLevelFrontCoverOrInnerPage/61/封面.jpg","bookCount":88,"audioCount":88,"tags":"分级阅读 · 阅读理解 · Collins Education · 分级读本 · 非虚构 · 虚构 · 附音频CD · 附家长指导","minPrice":399,"maxPrice":428,"originPrice":1992,"summaryInOneSentence":"全系列英国学校主流阅读教材"},{"pk":408,"chineseTitle":"儿歌韵文洞洞书","englishTitle":"Classic Books with Holes","frontCover":"System/EnglishLevelInnerPage/20181017181321827.jpg","bookCount":18,"tags":"语感培养 · 绘本阅读 · 启蒙认知 · Child's Play · 绘本 · 虚构 · 韵文 · 可点读","minPrice":288,"maxPrice":288,"originPrice":576,"summaryInOneSentence":"将磨耳朵与洞洞趣味体验合二为一"}]格式化后是:
[{
"pk": 502,
"chineseTitle": "廖彩杏英语启蒙书单",
"englishTitle": "",
"frontCover": "System/EnglishSeriesPicture/20181122103816897.jpg",
"bookCount": 129,
"tags": "语感培养 · 绘本阅读 · 启蒙认知 · 生活成长 · 绘本 · 非虚构 · 虚构",
"summaryInOneSentence": "“用有声书听出英语力”",
"soldOut": 1
}, {
"pk": 31,
"chineseTitle": "兰登分级阅读",
"englishTitle": "Step Into Reading",
"frontCover": "EnglishLevelFrontCoverOrInnerPage/79/封面.jpg",
"bookCount": 107,
"audioCount": 330,
"tags": "分级阅读 · Penguin Random House · 分级读本 · 非虚构 · 虚构 · 有音频 · 可点读",
"minPrice": 388,
"maxPrice": 492,
"originPrice": 820,
"summaryInOneSentence": "美国主流分级读物"
}, {
"pk": 519,
"chineseTitle": "吴敏兰英语启蒙书单",
"englishTitle": "",
"frontCover": "System/EnglishSeriesPicture/20181130182627844.jpg",
"bookCount": 121,
"tags": "语感培养 · 绘本阅读 · 启蒙认知 · 科学阅读 · 生活成长 · 绘本 · 非虚构 · 虚构",
"minPrice": 229,
"maxPrice": 229,
"originPrice": 458,
"summaryInOneSentence": "“自然养成英语阅读力”"
}, {
"pk": 520,
"chineseTitle": "汪培珽英语启蒙书单",
"englishTitle": "",
"frontCover": "System/EnglishSeriesPicture/20181122103840671.jpg",
"bookCount": 220,
"tags": "语感培养 · 绘本阅读 · 分级阅读 · 启蒙认知 · 生活成长 · 分级读本 · 绘本 · 虚构",
"minPrice": 128,
"maxPrice": 188,
"originPrice": 275,
"summaryInOneSentence": "“培养孩子的英文耳朵”"
}, {
"pk": 91,
"chineseTitle": "图书馆系列",
"englishTitle": "The Usborne Reading Programme",
"frontCover": "EnglishLevelFrontCoverOrInnerPage/834/封面.jpg",
"bookCount": 53,
"tags": "分级阅读 · Usborne Publishing · 分级读本 · 虚构 · 有音频",
"minPrice": 366,
"maxPrice": 375,
"originPrice": 1596,
"summaryInOneSentence": "易读语言和优秀故事的美妙结合"
}, {
"pk": 328,
"chineseTitle": "“我会读了”起步级之饼干狗",
"englishTitle": "I Can Read My First Level Biscuit",
"frontCover": "EnglishLevelFrontCoverOrInnerPage/282/封面.jpg",
"bookCount": 18,
"audioCount": 18,
"tags": "分级阅读 · HarperCollins · 分级读本 · 虚构 · 有音频",
"originPrice": 600,
"summaryInOneSentence": "家喻户晓的美国分级读物,人物形象孩子大爱",
"soldOut": 1
}, {
"pk": 34,
"chineseTitle": "国家地理少儿分级阅读",
"englishTitle": "National Geographic Kids Readers",
"frontCover": "EnglishLevelFrontCoverOrInnerPage/125/封面.jpg",
"bookCount": 95,
"tags": "分级阅读 · 科学阅读 · National Geographic Education · 分级读本 · 非虚构",
"minPrice": 215,
"maxPrice": 525,
"originPrice": 616,
"summaryInOneSentence": "好遗憾,我们小时候不曾有机会接触这样的书!"
}, {
"pk": 455,
"chineseTitle": "牛津阅读树初阶",
"englishTitle": "Oxford Reading Tree Level 1-3",
"frontCover": "System/EnglishLevelFrontCover/20181031112816785.jpg",
"bookCount": 198,
"tags": "自然拼读 · 分级阅读 · Oxford University Press · 分级读本 · 可点读",
"minPrice": 139,
"maxPrice": 835,
"originPrice": 1670,
"summaryInOneSentence": "非常受欢迎的英语阅读进阶全方案"
}, {
"pk": 470,
"chineseTitle": "大猫分级阅读幼儿园",
"englishTitle": "Collins Big Cat Reception",
"frontCover": "EnglishLevelFrontCoverOrInnerPage/61/封面.jpg",
"bookCount": 88,
"audioCount": 88,
"tags": "分级阅读 · 阅读理解 · Collins Education · 分级读本 · 非虚构 · 虚构 · 附音频CD · 附家长指导",
"minPrice": 399,
"maxPrice": 428,
"originPrice": 1992,
"summaryInOneSentence": "全系列英国学校主流阅读教材"
}, {
"pk": 408,
"chineseTitle": "儿歌韵文洞洞书",
"englishTitle": "Classic Books with Holes",
"frontCover": "System/EnglishLevelInnerPage/20181017181321827.jpg",
"bookCount": 18,
"tags": "语感培养 · 绘本阅读 · 启蒙认知 · Child's Play · 绘本 · 虚构 · 韵文 · 可点读",
"minPrice": 288,
"maxPrice": 288,
"originPrice": 576,
"summaryInOneSentence": "将磨耳朵与洞洞趣味体验合二为一"
}]