折腾:
期间,用PySpider代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-03-27 15:35:20
# Project: XiaohuashengApp
from pyspider.libs.base_handler import *
import os
import json
import codecs
import base64
import gzip
######################################################################
# Const
######################################################################
SelfReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/selfReadingBookQuery2"
ParentChildReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/parentChildReadingBookQuery2"
RESPONSE_OK = "1001"
######################################################################
# Config & Settings
######################################################################
DefaultPageSize = 10
UserAgentNoxAndroid = "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; A0001 Build/KOT49H) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"
UserId = "1134723"
Authorization = 'NSTp9~)NwSfrXp@\\'
Timestamp = "1553671960"
Signature = "bc8d887e7f16ef92269f55bfd74e131b"
# Timestamp = "1553671956"
# Signature = "a1f51f6852f42d934f0ac154dc374500"
...
######################################################################
# Main
######################################################################
class Handler(BaseHandler):
crawl_config = {
'headers': {
"Host": "www.xiaohuasheng.cn:83",
"User-Agent": UserAgentNoxAndroid,
"Content-Type": "application/json",
"Connection": "keep-alive",
"Authorization": Authorization,
"userId": UserId,
"timestamp": Timestamp,
"signature": Signature,
# "Cookie": "ASP.NET_SessionId=nryv24qhtbi2wlryi1rm5dea”,
# "Accept-Encoding": "gzip",
},
}
def on_start(self):
offset = 0
limit = 10
jTemplate = '{\"userId\":\"%s\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":%d,\"limit\":%d}'
jcJsonDict = {
"J": jTemplate % (UserId, offset, limit),
"C": 0
}
parentChildReadingParamDict = {
"offset": offset,
"limit": limit,
"jTemplate": jTemplate,
"jcJsonDict": jcJsonDict
}
self.crawl(ParentChildReadingUrl,
method="POST",
data= jcJsonDict,
callback=self.getParentChildReadingCallback,
save=parentChildReadingParamDict
)
......结果直接运行出现500错误

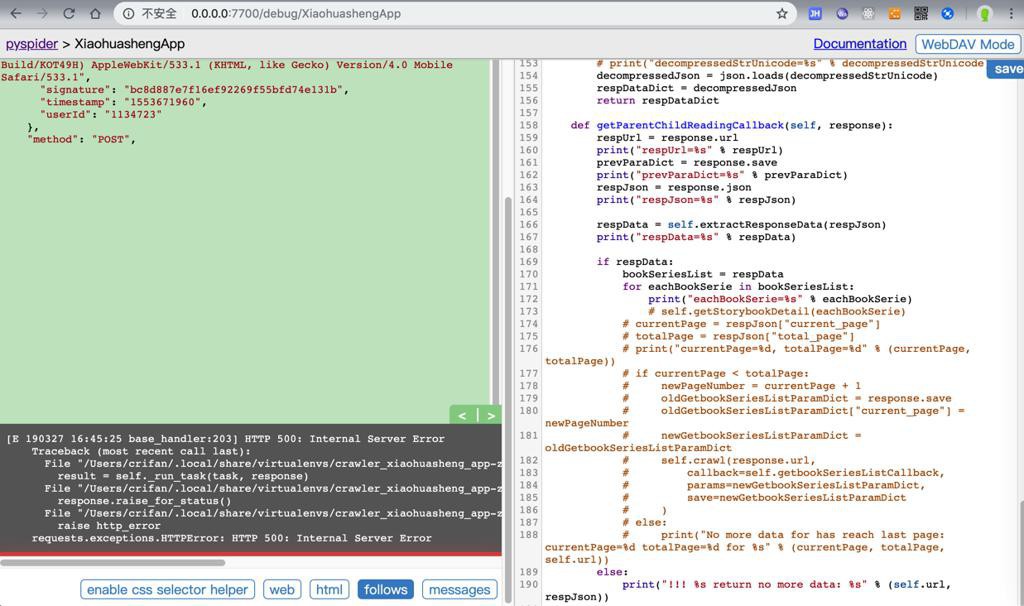
感觉需要去:
想办法先去Postman中测试通过,才能继续回来写代码,传参数。
结果代码中模拟了Postman中可以正常执行:
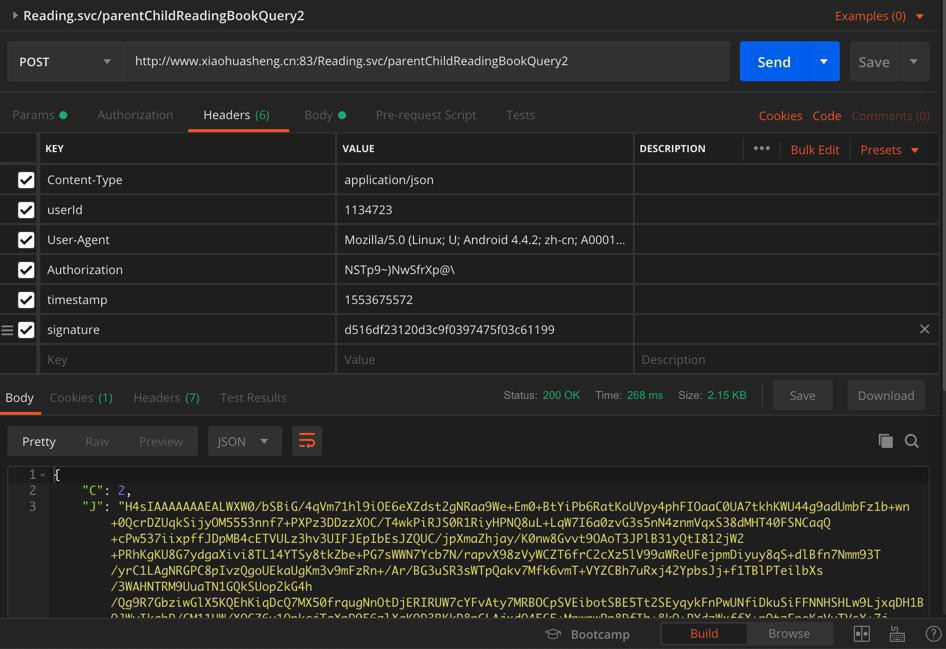
的代码:
UserAgentNoxAndroid = "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; A0001 Build/KOT49H) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"
UserId = "1134723"
Authorization = """NSTp9~)NwSfrXp@\\"""
Timestamp = "1553675572"
Signature = "d516df23120d3c9f0397475f03c61199"
class Handler(BaseHandler):
crawl_config = {
'headers': {
# "Host": "www.xiaohuasheng.cn:83",
"User-Agent": UserAgentNoxAndroid,
"Content-Type": "application/json",
"userId": UserId,
"Authorization": Authorization,
"timestamp": Timestamp,
"signature": Signature,
# "Connection": "keep-alive",
# "Cookie": "ASP.NET_SessionId=nryv24qhtbi2wlryi1rm5dea",
# "Cookie2": "$Version=1",
# "Accept-Encoding": "gzip",
},
}
def on_start(self):
offset = 0
limit = 10
jTemplate = '{\"userId\":\"%s\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":%d,\"limit\":%d}'
jcJsonDict = {
"J": jTemplate % (UserId, offset, limit),
"C": 0
}
print("jcJsonDict=%s" % jcJsonDict)
parentChildReadingParamDict = {
"offset": offset,
"limit": limit,
"jTemplate": jTemplate,
"jcJsonDict": jcJsonDict
}
self.crawl(ParentChildReadingUrl,
method="POST",
data=jcJsonDict,
callback=self.getParentChildReadingCallback,
save=parentChildReadingParamDict
)
结果PySpider中还是报错:
[E 190327 16:56:18 base_handler:203] HTTP 500: Internal Server Error Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_xiaohuasheng_app-zY4wnqo9/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_xiaohuasheng_app-zY4wnqo9/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 175, in _run_task response.raise_for_status() File "/Users/crifan/.local/share/virtualenvs/crawler_xiaohuasheng_app-zY4wnqo9/lib/python3.6/site-packages/pyspider/libs/response.py", line 184, in raise_for_status raise http_error requests.exceptions.HTTPError: HTTP 500: Internal Server Error
再去对比看看,难道是之前加了个cookie,实际上是生效的,用到了?
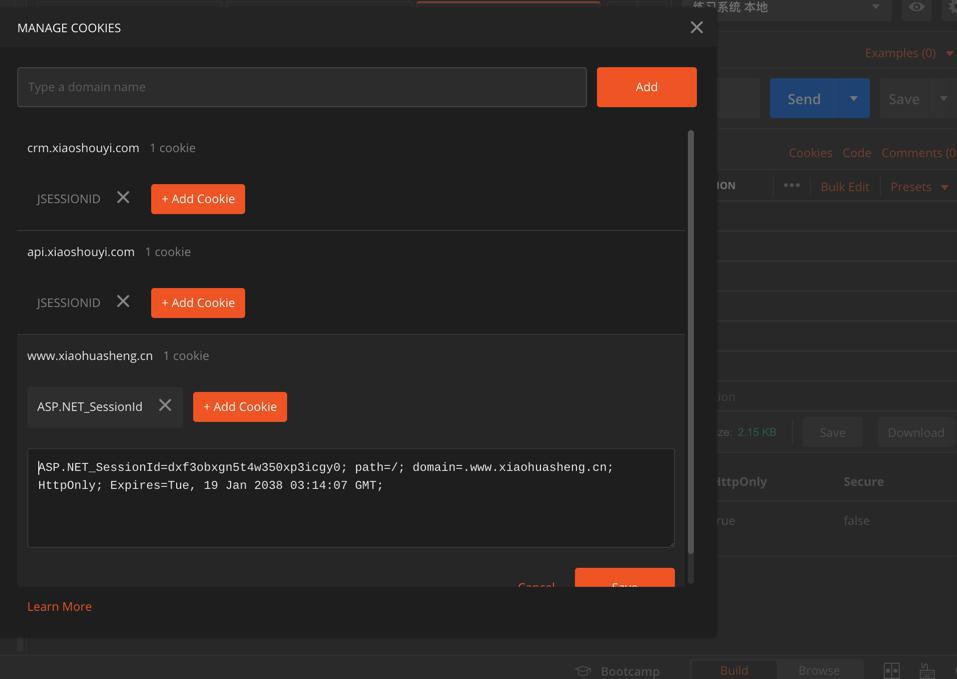
那也加上去试试
"Cookie": "ASP.NET_SessionId=nryv24qhtbi2wlryi1rm5dea", "Cookie2": "$Version=1",
结果:
不过同时去看看postman中发送的raw格式的数据是啥:
【已解决】Postman中如何查看http的请求和响应的原始内容
果然看到有 cookie(和其他一些自动加上去的参数)
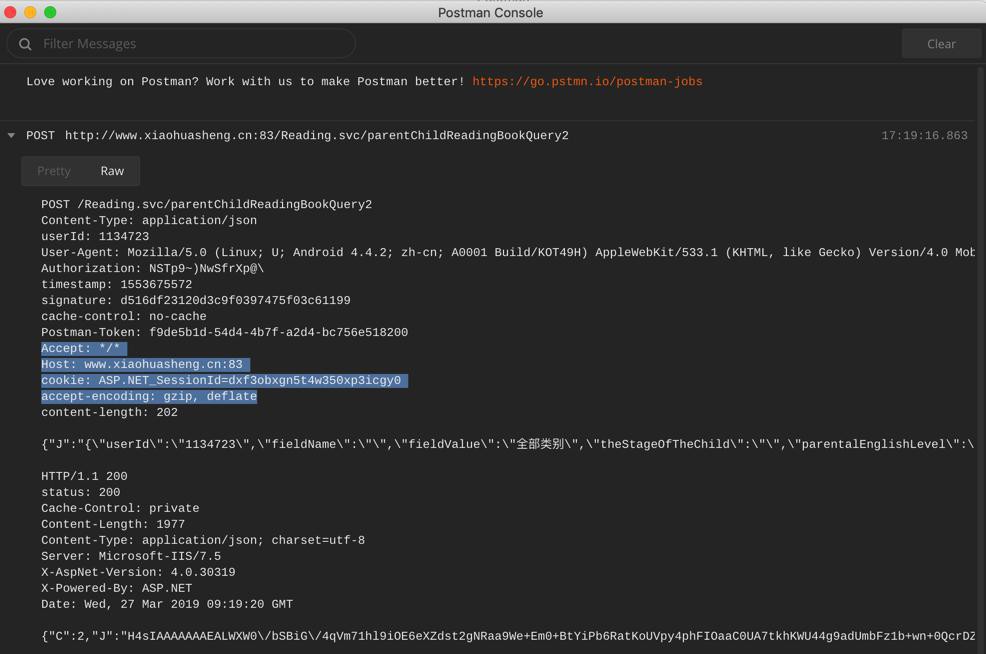
所以此处代码中,也是要去加上这些参数:
crawl_config = {
'headers': {
"Host": "www.xiaohuasheng.cn:83",
"User-Agent": UserAgentNoxAndroid,
"Content-Type": "application/json",
"userId": UserId,
"Authorization": Authorization,
"timestamp": Timestamp,
"signature": Signature,
"Cookie": "ASP.NET_SessionId=nryv24qhtbi2wlryi1rm5dea",
"Cookie2": "$Version=1",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "keep-alive",
},
}结果问题依旧,还是
HTTP 500: Internal Server Error
所以感觉很奇怪啊
继续调试,问题依旧。
难道是,默认使用了https?找找如何禁止https
还是headers根本没有传递?
然后:
然后:
然后继续去试试,还是500
从调试信息中注意到:
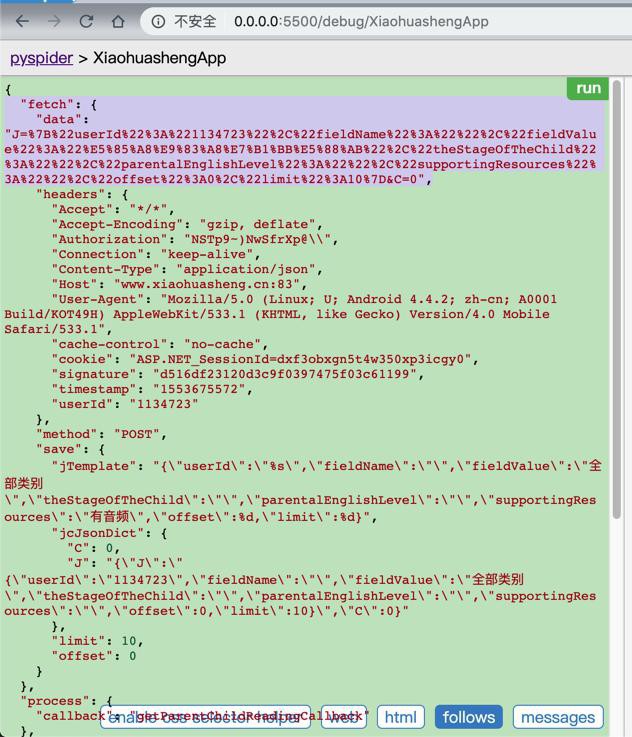
->怀疑此处是
传递的json字符串出错了?
Postman中是:
{"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}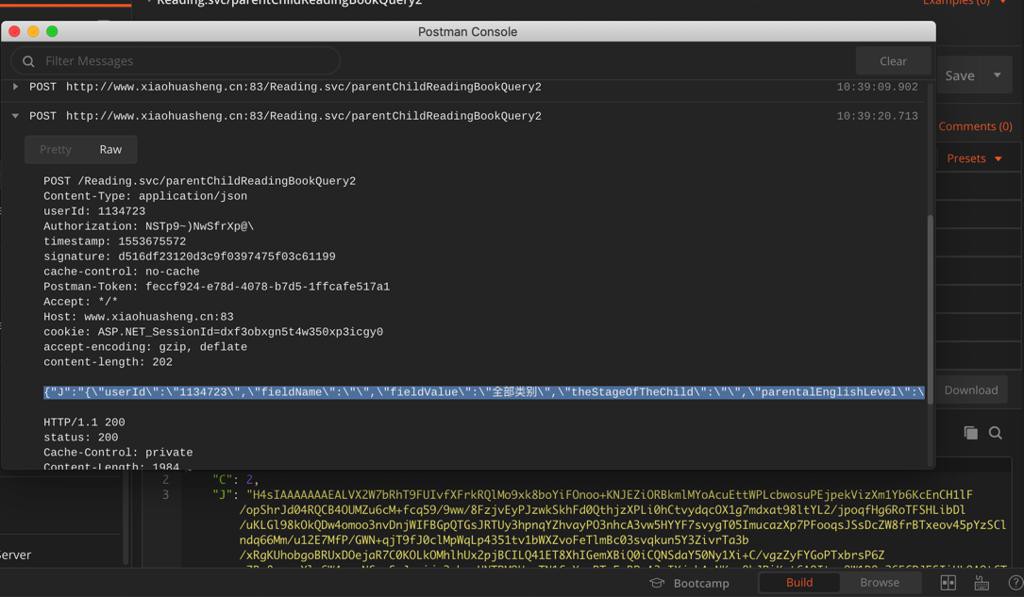
而此处是:
J=%7B%22userId%22%3A%221134723%22%2C%22fieldName%22%3A%22%22%2C%22fieldValue%22%3A%22%E5%85%A8%E9%83%A8%E7%B1%BB%E5%88%AB%22%2C%22theStageOfTheChild%22%3A%22%22%2C%22parentalEnglishLevel%22%3A%22%22%2C%22supportingResources%22%3A%22%22%2C%22offset%22%3A0%2C%22limit%22%3A10%7D&C=0"
那去想办法只传递正常的json字符串试试
去VSCode,把
\”
替换成
“
后:

再去掉{}的边上的多余的引号
再去试试:
jcJsonDict = {"J": {"userId":"1134723","fieldName":"","fieldValue":"全部类别","theStageOfTheChild":"","parentalEnglishLevel":"","supportingResources":"","offset":0,"limit":10},"C":0}结果:
错误依旧还是500
但是data变了:
"fetch": {
"data": "J=userId&J=fieldName&J=fieldValue&J=theStageOfTheChild&J=parentalEnglishLevel&J=supportingResources&J=offset&J=limit&C=0",试试:
jcJsonDict = {"J":'{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}',"C":0}结果
还是:
"fetch": {
"data": "J=%7B%22userId%22%3A%221134723%22%2C%22fieldName%22%3A%22%22%2C%22fieldValue%22%3A%22%E5%85%A8%E9%83%A8%E7%B1%BB%E5%88%AB%22%2C%22theStageOfTheChild%22%3A%22%22%2C%22parentalEnglishLevel%22%3A%22%22%2C%22supportingResources%22%3A%22%22%2C%22offset%22%3A0%2C%22limit%22%3A10%7D&C=0",问题依旧。
问题好像变成:
PySpider中self.crawl中,如何指定json格式的data,而保证data不被字符编码
然后即可解决问题。
【总结】
此处,已经在Postman中测试接口成功了:
http://www.xiaohuasheng.cn:83/Reading.svc/parentChildReadingBookQuery2
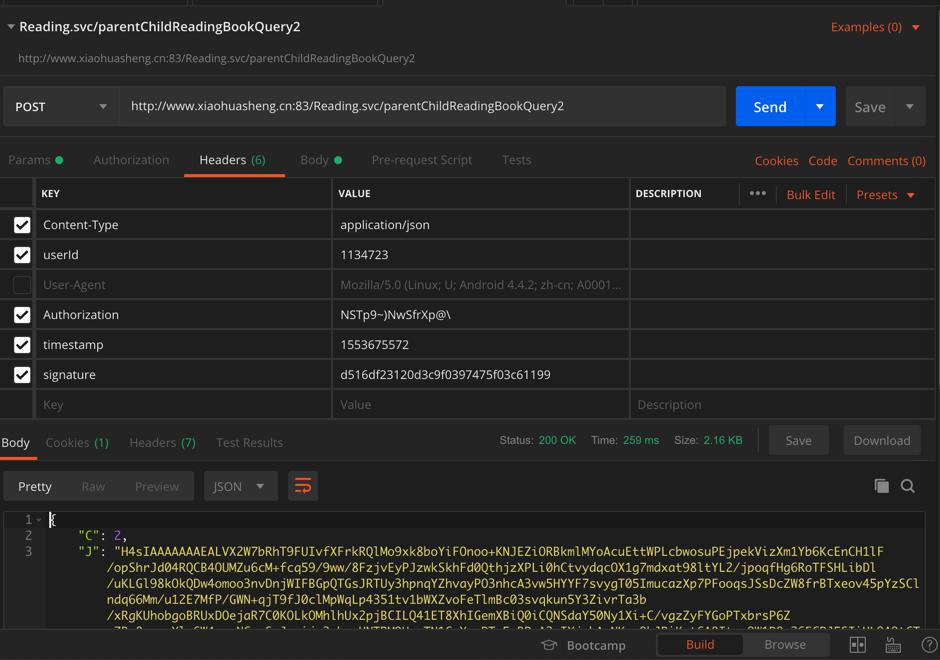
然后去PySpider中写同样的代码,包括加上了合适的header:
class Handler(BaseHandler):
crawl_config = {
'headers': {
"Host": "www.xiaohuasheng.cn:83",
"User-Agent": UserAgentNoxAndroid,
"Content-Type": "application/json",
"userId": UserId,
# "userId": "1134723",
"Authorization": Authorization,
"timestamp": Timestamp,
"signature": Signature,
"cookie": "ASP.NET_SessionId=dxf3obxgn5t4w350xp3icgy0",
# "Cookie2": "$Version=1",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"cache-control": "no-cache",
"Connection": "keep-alive",
# "content-length": "202",
},
}但是对于代码:
jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}
self.crawl(ParentChildReadingUrl,
method="POST",
data=jcJsonDict,
# data= json.dumps(jcJsonDict),
callback=self.getParentChildReadingCallback,
save=parentChildReadingParamDict
)始终都是报错:
requests.exceptions.HTTPError: HTTP 500: Internal Server Error
最后发现是:
被PySpider中的self.crawl的data参数内部,额外的encode编码为了:
"fetch": {
"data": "J=%7B%22userId%22%3A%221134723%22%2C%22fieldName%22%3A%22%22%2C%22fieldValue%22%3A%22%E5%85%A8%E9%83%A8%E7%B1%BB%E5%88%AB%22%2C%22theStageOfTheChild%22%3A%22%22%2C%22parentalEnglishLevel%22%3A%22%22%2C%22supportingResources%22%3A%22%22%2C%22offset%22%3A0%2C%22limit%22%3A10%7D&C=0"导致了此问题。
解决办法:
避免data参数传入json字典,而直接dumps成为字符串传入:
jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}
self.crawl(ParentChildReadingUrl,
method="POST",
# data=jcJsonDict,
data= json.dumps(jcJsonDict),
callback=self.getParentChildReadingCallback,
save=parentChildReadingParamDict
)即可看到data参数是,没有被encode编码的:
"fetch": {
"data": "{\"J\": \"{\\\"userId\\\":\\\"1134723\\\",\\\"fieldName\\\":\\\"\\\",\\\"fieldValue\\\":\\\"\\u5168\\u90e8\\u7c7b\\u522b\\\",\\\"theStageOfTheChild\\\":\\\"\\\",\\\"parentalEnglishLevel\\\":\\\"\\\",\\\"supportingResources\\\":\\\"\\\",\\\"offset\\\":0,\\\"limit\\\":10}\", \"C\": 0}",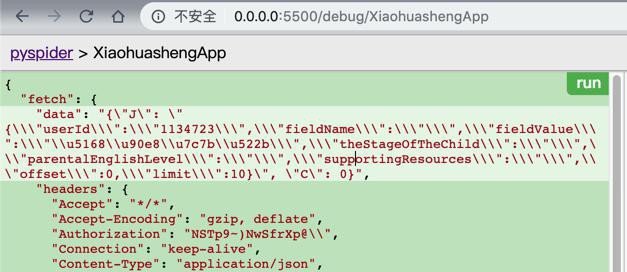
即可正常返回要的结果了:
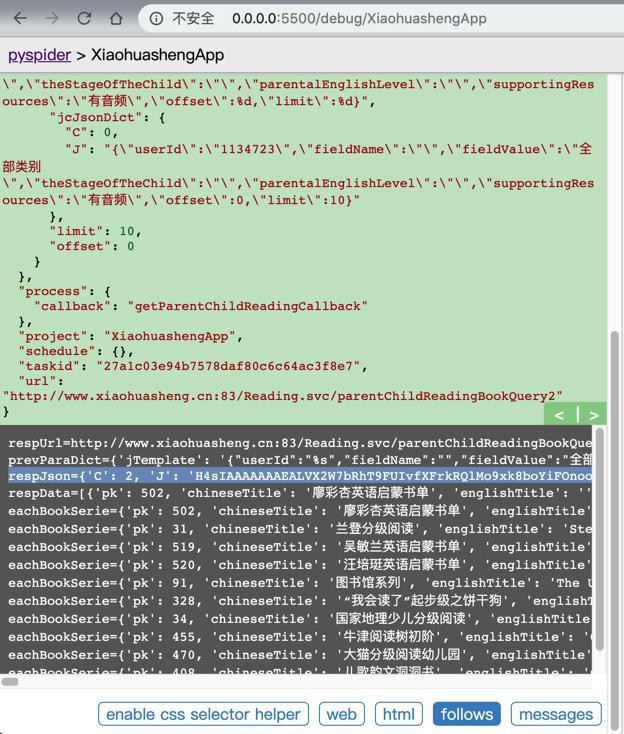
详见:
【已解决】PySpider中self.crawl的POST的json参数如何不被encode编码而保持json原始字符串格式
转载请注明:在路上 » 【已解决】PySpider模拟请求小花生api接口出错:requests.exceptions.HTTPError HTTP 500 Internal Server Error