折腾:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
期间,由于youtube网页本身需要翻墙才能打开。
而此处Mac中已有Shadowsocks-NG的ss代理了。
现在需要给Scrapy去添加代理。
scrapy add proxy
scrapy 添加 翻墙 代理
scrapy: 使用HTTP代理绕过网站反爬虫机制 | 藏经阁
Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法 – python修行路
python – Scrapy and proxies – Stack Overflow
Using Scrapy with Proxies | 草原上的狼
aivarsk/scrapy-proxies: Random proxy middleware for Scrapy
如何让你的scrapy爬虫不再被ban – 秋楓 – 博客园
scrapy-rotating-proxies 0.5 : Python Package Index
Make Scrapy work with socket proxy | Michael Yin’s Blog
Scrapy – Web Crawling with a Proxy Network | The Elancer
adding http proxy in Scrapy program – Google Groups
Integrate Scrapoxy to Scrapy — Scrapoxy 3.0.0 documentation
Downloader Middleware — Scrapy 1.5.0 documentation
“HttpProxyMiddleware
New in version 0.8.
class scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware
This middleware sets the HTTP proxy to use for requests, by setting the proxy meta value for Request objects.
Like the Python standard library modules urllib and urllib2, it obeys the following environment variables:
http_proxy
https_proxy
no_proxy
You can also set the meta key proxy per-request, to a value likehttp://some_proxy_server:port or http://username:password@some_proxy_server:port. Keep in mind this value will take precedence over http_proxy/https_proxy environment variables, and it will also ignore no_proxy environment variable.”
HttpProxyMiddleware这个插件可以用来设置代理
其使用和Python的标准库urllib和urllib2一样的规则:支持环境变量
http_proxy
https_proxy
no_proxy
-》如果设置了这些参数,则使用这些参数
-〉可以在Request中,设置proxy参数为你要的值:
http://username:password@some_proxy_server:port
如果设置了request.meta[‘proxy’]的话,则优先级高于上面的http_proxy和https_proxy,也会忽略掉no_proxy
在参考了一堆,尤其是:
和源码:
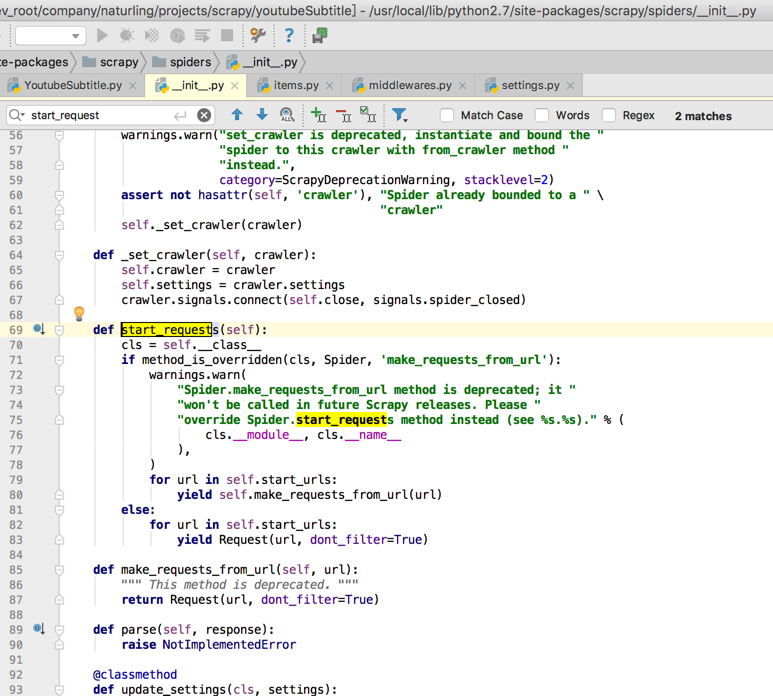
后,先去试试:
直接重写Spider的start_requests,其中添加proxy
简单,直接,方便
后面再去试试添加middlewares.py中用ProxyMiddleware的process_request中去添加proxy
虽然稍微复杂点,但是灵活度更高
去看看此处本地ss的代理的地址:
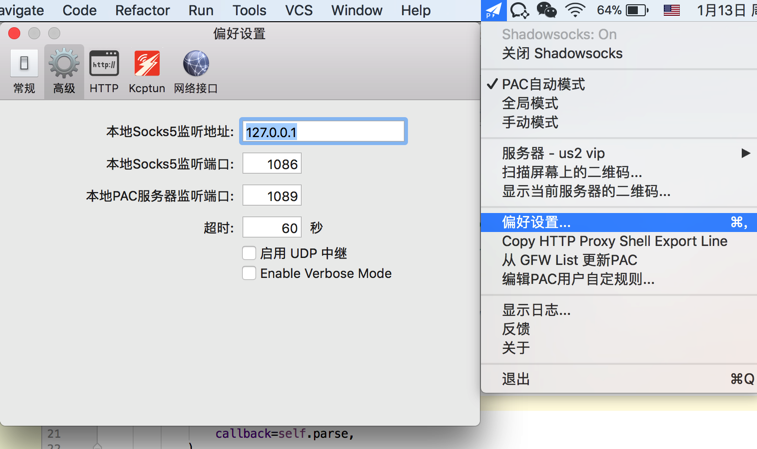
貌似是:
http://127.0.0.1:1086
?
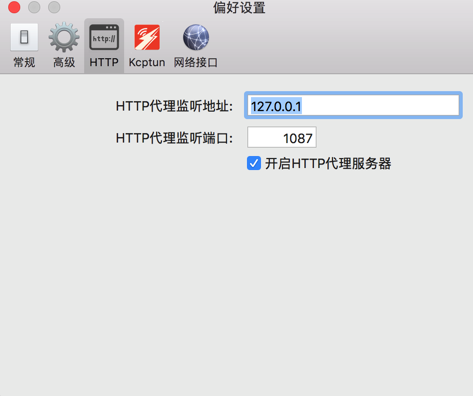
好像应该是:
http://127.0.0.1:1087
所以去试试
结果好像不行:
没有起效果。
scrapy start_requests proxy
How to setting proxy in Python Scrapy – Stack Overflow
Spiders — Scrapy 1.5.0 documentation
connection pooling do not work when using proxy · Issue #2743 · scrapy/scrapy
好像scrapy有bug?
ansenhuang/scrapy-zhihu-users: scrapy爬取知乎用户数据
def start_requests(self):
yield scrapy.Request(
url = self.domain,
headers = self.headers,
meta = {
‘proxy’: UsersConfig[‘proxy’],
‘cookiejar’: 1
},
callback = self.request_captcha
)
我这里也是类似写法,应该没问题啊
换成sock5代理:
def start_requests(self):
“””This is our first request to grab all the urls of the profiles.
“””
for url in self.start_urls:
yield scrapy.Request(
url=url,
meta={
“proxy”: “http://127.0.0.1:1086”
},
callback=self.parse,
)
试试
还是不行。
算了,去换ProxyMiddleware试试
python爬虫scrapy之downloader_middleware设置proxy代理 – Luckyboy_LHD – 博客园
最后是
class YoutubesubtitleSpider
中用
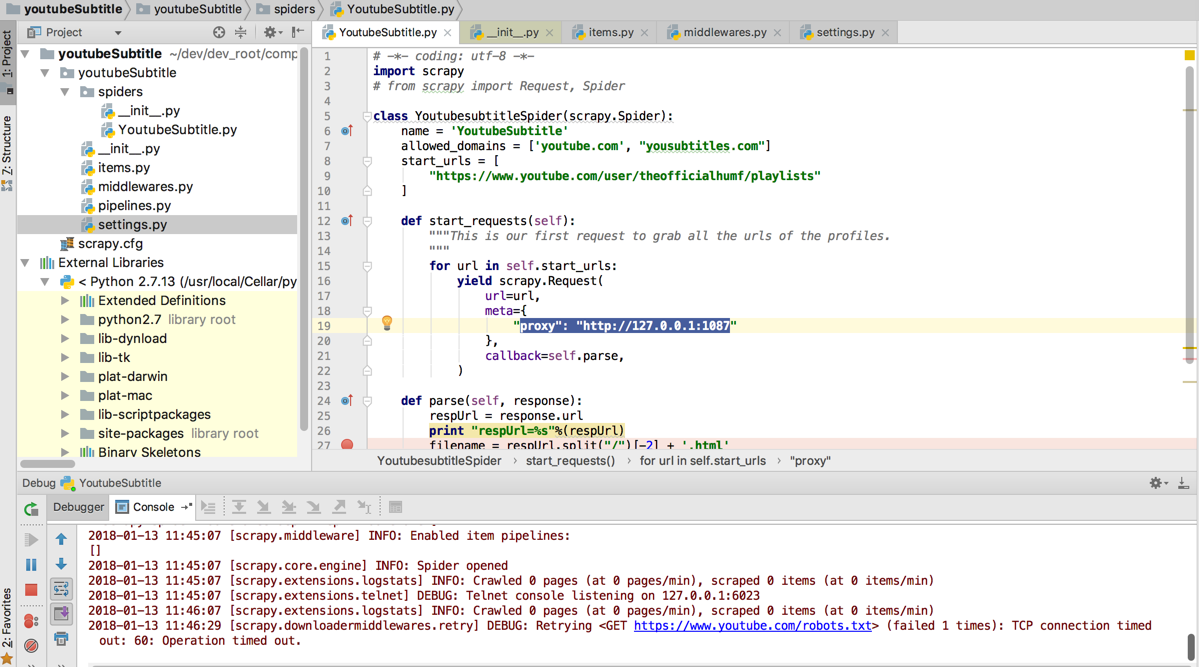
def start_requests(self):
“””This is our first request to grab all the urls of the profiles.
“””
for url in self.start_urls:
self.logger.info(“url=%s”, url)
yield scrapy.Request(
url=url,
meta={
“proxy”: “http://127.0.0.1:1087”
},
callback=self.parse,
)
是不起效果的:
感觉是scrapy的bug?
因为貌似别人同样设置好像是可以的。
【总结】
最终是:
通过
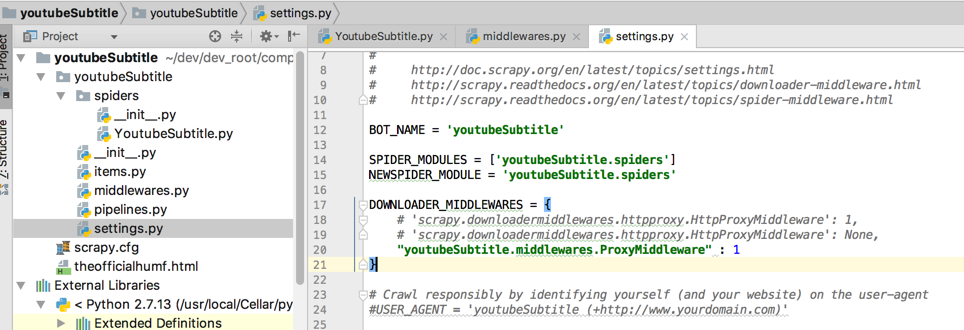
/Users/crifan/dev/dev_root/company/naturling/projects/scrapy/youtubeSubtitle/youtubeSubtitle/settings.py
中设置:
DOWNLOADER_MIDDLEWARES = {
# ‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware’: 1,
# ‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware’: None,
“youtubeSubtitle.middlewares.ProxyMiddleware” : 1
}
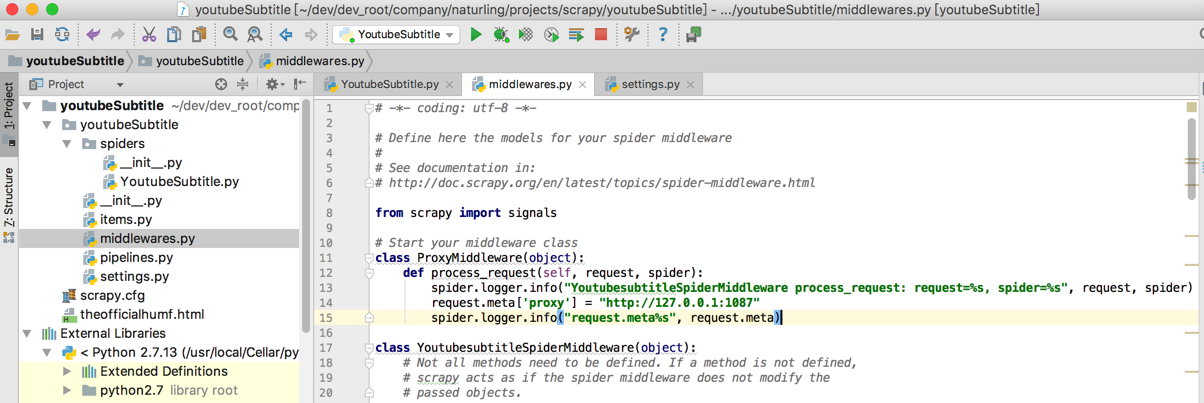
/Users/crifan/dev/dev_root/company/naturling/projects/scrapy/youtubeSubtitle/youtubeSubtitle/middlewares.py
# Start your middleware class
class ProxyMiddleware(object):
def process_request(self, request, spider):
spider.logger.info(“YoutubesubtitleSpiderMiddleware process_request: request=%s, spider=%s”, request, spider)
request.meta[‘proxy’] = “http://127.0.0.1:1087”
spider.logger.info(“request.meta%s”, request.meta)
然后就可以http的代理就生效了,就可以获取youtube内容了:
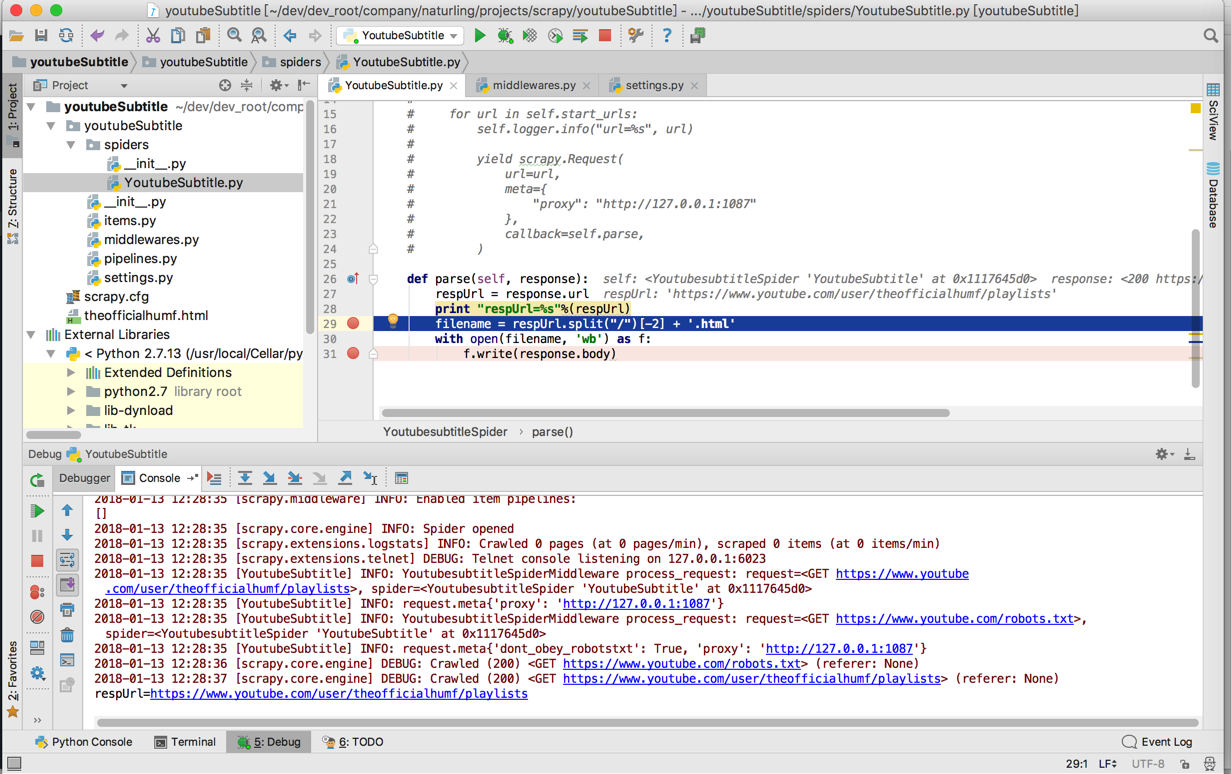
2018-01-13 12:28:35 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 12:28:35 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-01-13 12:28:35 [YoutubeSubtitle] INFO: YoutubesubtitleSpiderMiddleware process_request: request=<GET https://www.youtube.com/user/theofficialhumf/playlists>, spider=<YoutubesubtitleSpider ‘YoutubeSubtitle’ at 0x1117645d0>
2018-01-13 12:28:35 [YoutubeSubtitle] INFO: request.meta{‘proxy’: ‘http://127.0.0.1:1087’}
2018-01-13 12:28:35 [YoutubeSubtitle] INFO: YoutubesubtitleSpiderMiddleware process_request: request=<GET https://www.youtube.com/robots.txt>, spider=<YoutubesubtitleSpider ‘YoutubeSubtitle’ at 0x1117645d0>
2018-01-13 12:28:35 [YoutubeSubtitle] INFO: request.meta{‘dont_obey_robotstxt’: True, ‘proxy’: ‘http://127.0.0.1:1087’}
2018-01-13 12:28:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.youtube.com/robots.txt> (referer: None)
2018-01-13 12:28:37 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.youtube.com/user/theofficialhumf/playlists> (referer: None)
respUrl=https://www.youtube.com/user/theofficialhumf/playlists
保存出来的html用chrome打开: