
【解答】为什么bash可以写脚本 还要用python
crifan 13年前 (2013-06-03) 2834浏览
【背景】 别人的问题: 菜鸟弱弱的问下 为什么bash可以写脚本 还要用python 【解答】 这个问题,就像在问: 既然有了自行车可以骑了,为何还需要汽车? 答: 因为汽车,有自行车具体的基本功能之外的,N多种功能和好处。 ...
crifan 13年前 (2013-06-03) 2834浏览
【背景】 别人的问题: 菜鸟弱弱的问下 为什么bash可以写脚本 还要用python 【解答】 这个问题,就像在问: 既然有了自行车可以骑了,为何还需要汽车? 答: 因为汽车,有自行车具体的基本功能之外的,N多种功能和好处。 ...
crifan 13年前 (2013-05-27) 3974浏览
【问题】 每一种语言的数据类型的左右 中问: 其实对于我们刚刚进学校学习一门语言的时候,遇到数据类型有很多种,大家很多时候遇到一个问题。为什么要学那么多数据类型?每一种数据类型有什么用?在什么地方才需要用到相应的数据类型? ...
crifan 13年前 (2013-05-27) 6467浏览
【背景】 折腾: 【记录】Python中尝试用lxml去解析html 中,想要搞懂对于一个ElementTree的节点,如何获得该节点的完整的html,即类似于常见的InnerHtml的效果。 【解决过程】 1.参考: Equivalent to I...
crifan 13年前 (2013-05-27) 13109浏览
【背景】 Python中,之前一直用BeautifulSoup去解析html的: 【教程】Python中第三方的用于解析HTML的库:BeautifulSoup 后来听说BeautifulSoup很慢,而lxml解析html速度很快,所以打算去试试...
crifan 13年前 (2013-05-24) 13933浏览
【问题】 在折腾: 【记录】用Scrapy抓取manta.com 期间,运行scrapy项目,结果出错: E:\Dev_Root\python\Scrapy\manta\manta>scrapy crawl manta -o respB...
crifan 13年前 (2013-05-24) 4919浏览
【问题】 手上有个Scrapy的项目,是要抓取和 http://www.manta.com/ 相关的站点的内容。 已有源码为: bs.py: import requests from bs4 import BeautifulSoup ...
crifan 13年前 (2013-05-24) 9790浏览
【问题】 别人遇到的问题: 求正则表达式牛人 怎样获得截获了多次的组的所有子串 Match.group(i)方法说明里说 如果一个组被截获了多次 则 截获了多次的组返回最后一次截获的子串 比如&q...
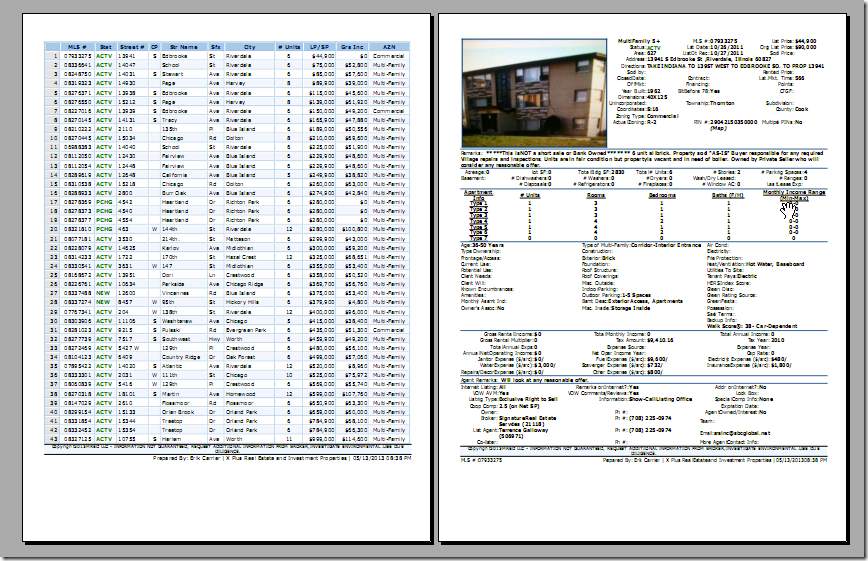
crifan 13年前 (2013-05-20) 6561浏览
【背景】 已有一个pdf文件,效果如下: 想要用python从中提取一些信息。 【折腾过程】 1.搜了下,找到个: pyPdf http://pybrary.net/pyPdf/ 其功能之一是: “extracting document infor...
crifan 13年前 (2013-05-15) 15821浏览
【背景】 看到: python将json转换成xml 所以先去试试,用python实现,将xml转为json。 【解决过程】 1.参考: python中将XML转换为JSON格式 所以先以: <student> ...
crifan 13年前 (2013-05-08) 4519浏览
待完成,最新更新:2013-05-08 把之前的: 【详解】Python中的文件操作,readline读取单行,readlines读取全部行,文件打开模式 中的部分内容整理过来,再加上更多的解释。 关于文件的基本知识 &...