用Selenium调试打开页面:
https://www.befrugal.com/home/
时,网页加载要好半天才能结束:
2017/11/26 12:36:51 LINE 115 INFO open befrugalHomeUrl=https://www.befrugal.com/home/
2017/11/26 12:37:16 LINE 121 INFO Found Login button
花了27秒,
但是实际上我此处需要的login的按钮,估计也需要就3,5秒,早就显示出来了:

但是(左下角)会显示
正在登录 d2z2x9m6jf98op.couldfront.net的响应
去Chrome调试发现很多都是:
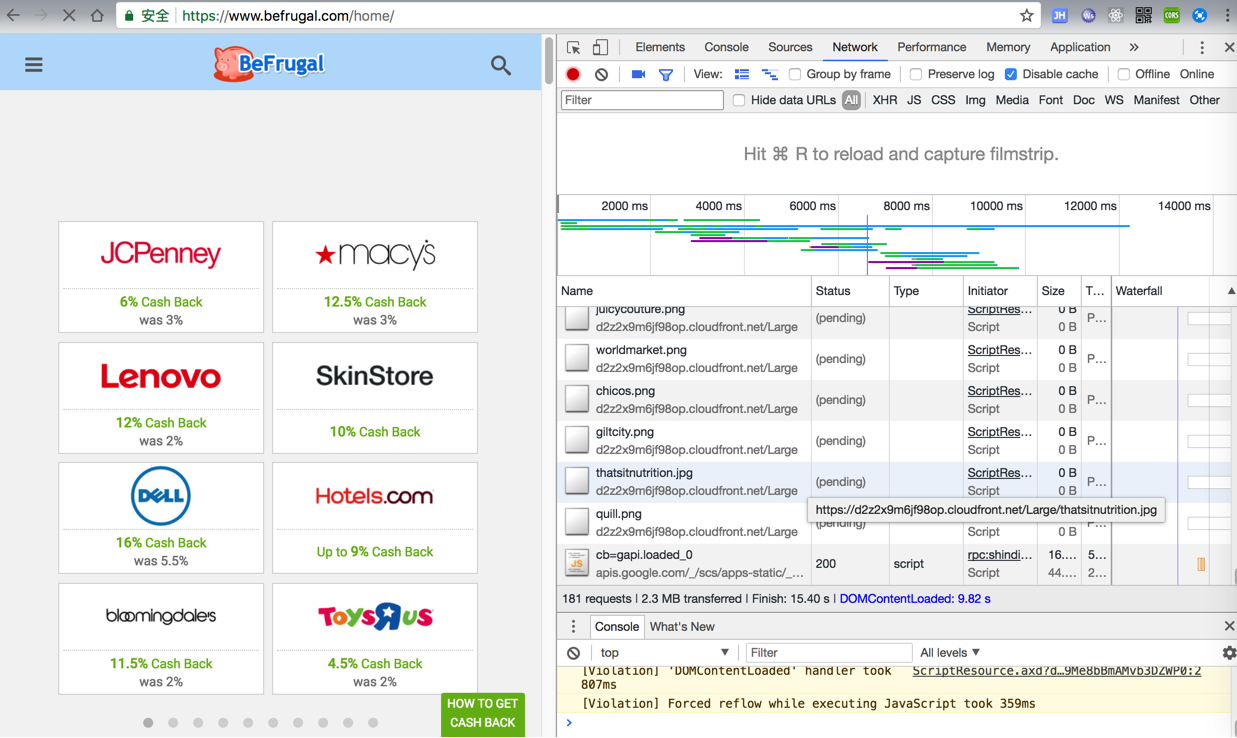
https://d2z2x9m6jf98op.cloudfront.net/Large/thatsitnutrition.jpg
{kind=link}
之类的图片。
此处希望:
在已经得到要显示的元素后,可以手动指定忽略加载某些url
比便于加速
或者是driver.get去加载url时,不用等待url完全加载完毕就进行后续处理
现在的逻辑貌似是:
url加载都是完全加载,然后才回去查找对应的元素
selenium get url omit some resource
selenium load url omit
Selenium WebDriver go to page without waiting for page load – Stack Overflow
仅限于firefox,感觉不容易保证准确性
Selenium Webdriver c# without waiting for page to load – Stack Overflow
IE和Firefox
感觉不容易控制准确性。
那看看是否可以忽略某些url比如上述的地址
URL Loading in Selenium Webdriver: All about get() and navigate() – Make Selenium Easy
试试:
driver.manage().timeouts().pageLoadTimeout(30, TimeUnit.SECONDS);
结果此处没有driver.manage或driver.timeout
只有:
driver.set_page_load_timeout()
但是此处还是不能去设置,否则超过了比如设置的20秒,实际上页面可以30秒后加载出来的,结果却异常,也不行。
How to load a URL in browser without using get() or navigate() method – Make Selenium Easy
How To Remove Third Party Resources
selenium load url omit some resource
java – Selenium Webdrivers: Load Page without any resources – Stack Overflow
说是可以用proxy去block这种url
去试试
java – prevent external content to be loaded in selenium webdriver test – Stack Overflow
selenium python black list
How To Remove Third Party Resources
7. WebDriver API — Selenium Python Bindings 2 documentation
好像只有firefox才有proxy?
Exclude Selenium WebDriver traffic from Google Analytics | Yi Zeng’s Blog
jarib/browsermob-proxy-rb: Ruby client for the BrowserMob Proxy
Proxy support · Issue #97 · mozilla/geckodriver
selenium python proxy
python – Running selenium behind a proxy server – Stack Overflow
Setting up proxy with selenium / python – Stack Overflow
AutomatedTester/browsermob-proxy-py: A python wrapper for Browsermob Proxy
但是好像还要单独起proxy的sever服务,还是很麻烦
How to Run Web Drivers with Proxies in Python – John Patrick Roach
可以用代理,但是没有blask list的功能。
selenium browsermob-proxy-py phantomjs
server.start() gives error · Issue #52 · AutomatedTester/browsermob-proxy-py
selenium+browsermob network网络爬取 – 色彩时光
Selenium Phantomjs Proxy – pythonexample.com
Welcome to BrowserMob Proxy’s documentation! — BrowserMob Proxy 0.6.0 documentation
再去看:
https://github.com/lightbody/browsermob-proxy
里面说了,可以作为 embed模式运行的
再去
看简介:
<code>BrowserMob Proxy A free utility to help web developers watch and manipulate network traffic from their AJAX applications. </code>
About BrowserMob Proxy (BMP)
BrowserMob proxy is based on technology developed in the Selenium open source project and a commercial load testing and monitoring service originally called BrowserMob and now part of Neustar.
The proxy is a free (Apache 2.0 license) utility that works well with Selenium or can be used independently.
It can capture performance data for web apps (via the HAR format), as well as manipulate browser behavior and traffic, such as whitelisting and blacklisting content, simulating network traffic and latency, and rewriting HTTP requests and responses.
先去:
或
https://github.com/lightbody/browsermob-proxy/releases
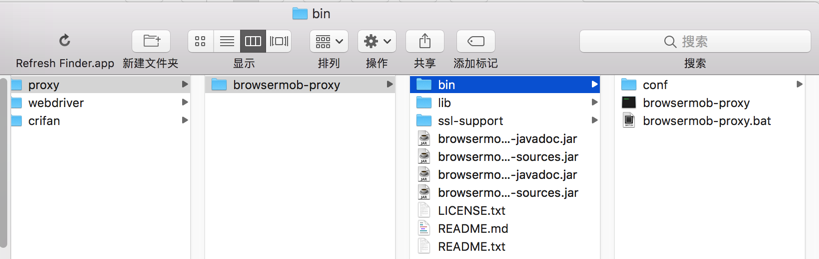
下载bin文件:
browsermob-proxy-2.1.4-bin.zip
解压得到:
再去参考:
官网示例
https://github.com/lightbody/browsermob-proxy#using-with-selenium
和别人代码:
https://zhuanlan.zhihu.com/p/26238280
https://pythonexample.com/code/selenium-phantomjs-proxy/
去试试
直接去安装:
<code>pip install browsermob-proxy </code>
结果安装了很多:
<code>➜ ms_store_auto_order git:(master) ✗ pip install browsermob-proxy Collecting browsermob-proxy Downloading browsermob_proxy-0.8.0-py2-none-any.whl Collecting requests>=2.9.1 (from browsermob-proxy) Downloading requests-2.18.4-py2.py3-none-any.whl (88kB) 100% |████████████████████████████████| 92kB 40kB/s Collecting certifi>=2017.4.17 (from requests>=2.9.1->browsermob-proxy) Downloading certifi-2017.11.5-py2.py3-none-any.whl (330kB) 100% |████████████████████████████████| 337kB 11kB/s Collecting chardet<3.1.0,>=3.0.2 (from requests>=2.9.1->browsermob-proxy) Downloading chardet-3.0.4-py2.py3-none-any.whl (133kB) 100% |████████████████████████████████| 143kB 12kB/s Collecting idna<2.7,>=2.5 (from requests>=2.9.1->browsermob-proxy) Downloading idna-2.6-py2.py3-none-any.whl (56kB) 100% |████████████████████████████████| 61kB 9.6kB/s Collecting urllib3<1.23,>=1.21.1 (from requests>=2.9.1->browsermob-proxy) Downloading urllib3-1.22-py2.py3-none-any.whl (132kB) 100% |████████████████████████████████| 133kB 24kB/s Installing collected packages: certifi, chardet, idna, urllib3, requests, browsermob-proxy Successfully installed browsermob-proxy-0.8.0 certifi-2017.11.5 chardet-3.0.4 idna-2.6 requests-2.18.4 urllib3-1.22 </code>
好像就用不到官网下载的二进制了。
结果代码:
<code>from browsermobproxy import Server </code>
proxy = None
if gCfg[“useProxy”]:
# use browsermob-proxy to black list some url/resource to speed up
proxyFullPath = os.path.join(os.getcwd(), “libs/proxy/browsermob-proxy”)
logging.debug(“proxyFullPath=%s”, proxyFullPath)
proxyServer = Server(proxyFullPath)
logging.debug(“proxyServer=%s”, proxyServer)
proxyServer.start()
proxy = proxyServer.create_proxy()
logging.debug(“proxy=%s”, proxy)
# proxy.blacklist([“http://.*/.*.css.*”,”http://.*/.*.jpg.*”,”http://.*/.*.png.*”,”http://.*/.*.gif.*”],200)
proxy.blacklist([“https?://\w+.cloudfront.net/.*“],200)
if gCfg[“webdriver”] == “chrome”:
# driver = webdriver.Chrome()
chromeOptions = webdriver.ChromeOptions()
logging.info(“chromeOptions=%s”, chromeOptions)
if gCfg[“useProxy”]:
chromeOptions.add_argument(‘–proxy-server={host}:{port}’.format(host=“localhost”, port=proxy.port))
driver = webdriver.Chrome(chrome_options=chromeOptions)
elif gCfg[“webdriver”] == “phantomjs”:
# driver = webdriver.PhantomJS()
desiredCapabilities = DesiredCapabilities.PHANTOMJS.copy()
logging.debug(“desiredCapabilities=%s”, desiredCapabilities)
desiredCapabilities[‘phantomjs.page.customHeaders.User-Agent’] = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) ‘ \
‘AppleWebKit/537.36 (KHTML, like Gecko) ‘ \
‘Chrome/39.0.2171.95 Safari/537.36’
logging.debug(“desiredCapabilities=%s”, desiredCapabilities)
driver = webdriver.PhantomJS(desired_capabilities=desiredCapabilities)
结果运行出错:
<code> proxyServer.start()
File "/usr/local/lib/python2.7/site-packages/browsermobproxy/server.py", line 127, in start
raise ProxyServerError("Can't connect to Browsermob-Proxy")
browsermobproxy.exceptions.ProxyServerError: Can't connect to Browsermob-Proxy
</code>无意间发现,多了个log文件:server.log
<code>Error: Unable to access jarfile ...libs/lib/browsermob-dist-2.1.4.jar </code>
好像是路径不对?
然后再去看看,是不是必须是jar包
看到:
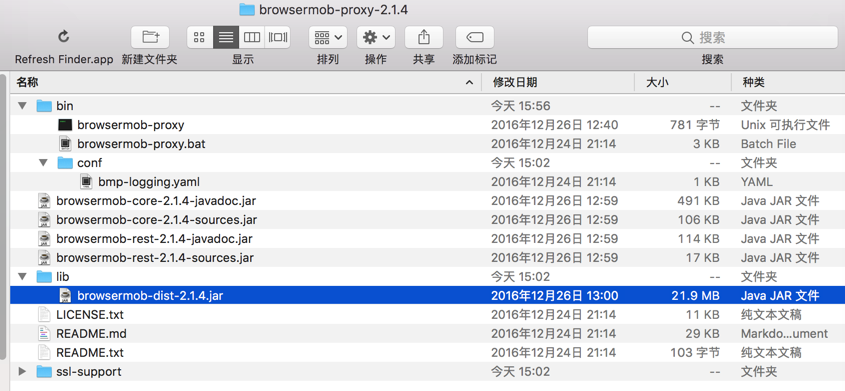
不是路径,而是找不到对应的jar包
所以整个解压缩后的文件都放进去
通过:
代码:
好像有显示等待代理

结果试了半天,还是不行:
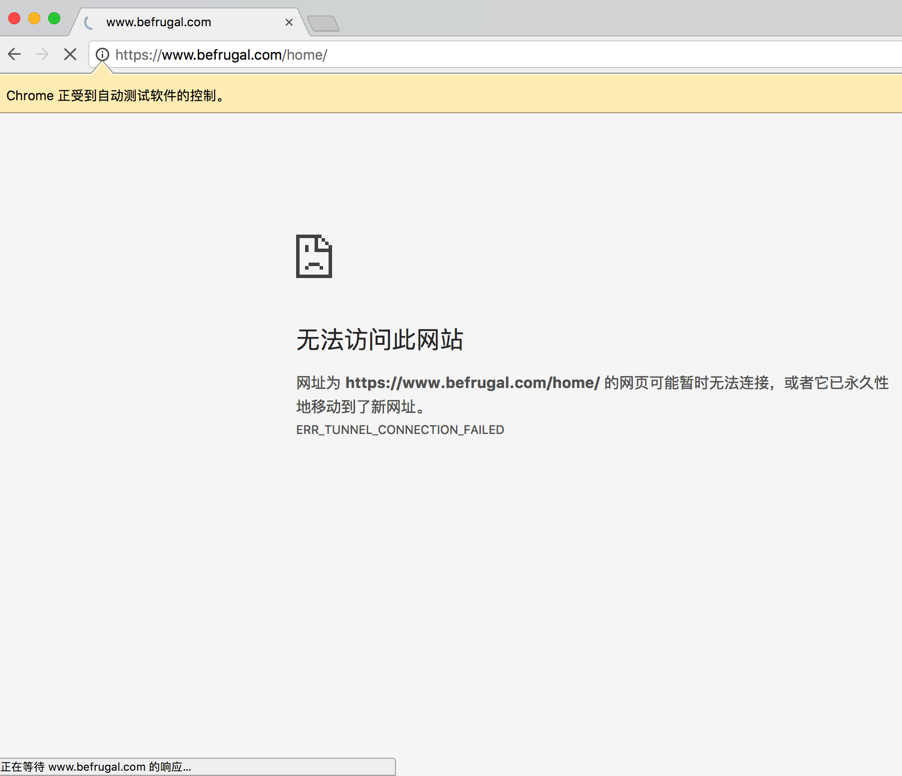
算了。放弃。
主要是:
本身很麻烦。
并且是Proxy Server启动的时间就很慢,10秒左右
create_proxy也很慢,也有5秒以上。
-》失去了加速的目的。
转载请注明:在路上 » 【未解决】Selenium中如何打开url后忽略加载部分资源