比如,我所遇到的,一个docbook的xml源文件,本身就有500多行,内容很多。
此时,编译生成pdf过程中,生成fo的时候出错:
javax.xml.transform.TransformerException: org.apache.fop.fo.ValidationException: "fo:table" is missing child elements. Required content model: (marker*,table-column*,table-header?,table-footer?,table-body+) (See position 27:127554)
at org.apache.fop.cli.InputHandler.transformTo(InputHandler.java:302)
at org.apache.fop.cli.InputHandler.renderTo(InputHandler.java:130)
at org.apache.fop.cli.Main.startFOP(Main.java:174)
at org.apache.fop.cli.Main.main(Main.java:205)
其中可以看出,已经明确指出了出错的具体位置:27:127554
即,错误行号linenumber是27,行内偏移量offset为127554
调试无缩进的(xml格式的)fo文件. 但是,当你去用Notepad++打开fo文件的话,所看到的内容是这样的:
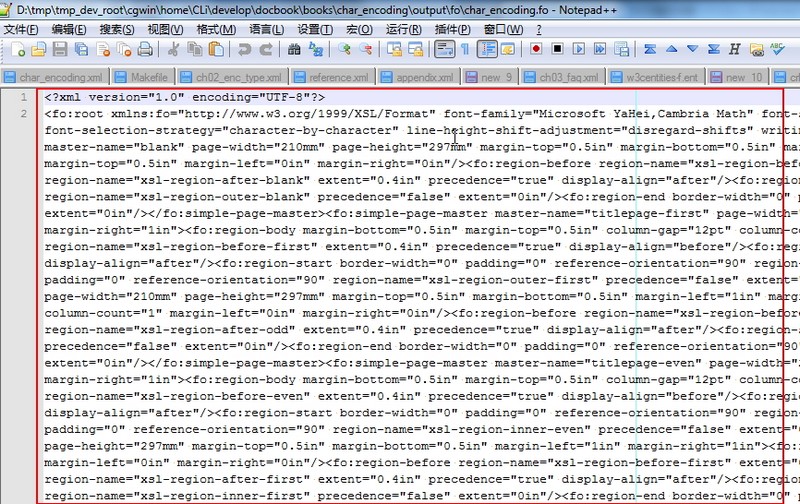 |
然后去通过选择:语言 → XML,进行语法高亮后,变成:
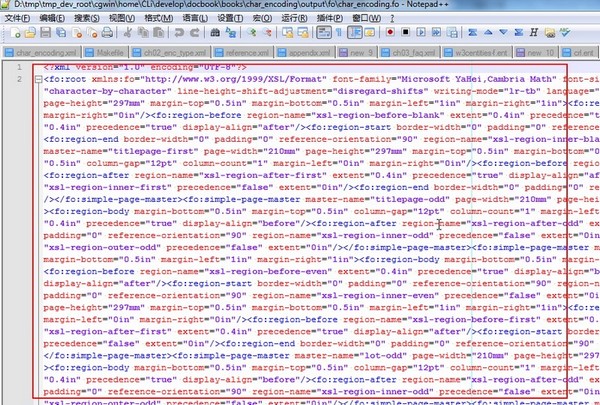 |
虽然容易看清代码了。但是很明显,代码整体上非常乱,因为没有缩进,很多内容都集中到同一行中显示了。这是因为之前对于fo所用的设置为:
<xsl:output method="xml"
encoding="UTF-8"
indent="no"/>
即,制定了输出的xml中,indent为no,即没有缩进,导致生成的(xml类型的)fo文件,内容都显示到一行中,显得很乱。在此种情况下,如果想要去调试的话,就只能是这样做:在Notepad++中,用搜索→行定位...(Ctrl+G),调出跳转对话框,选择“行”,然后输入错误行号,此处为27:
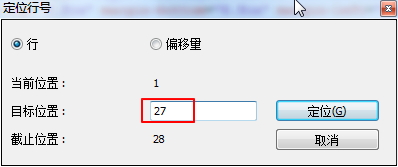 |
然后点击"定位"就可以跳转到27行了。
 |
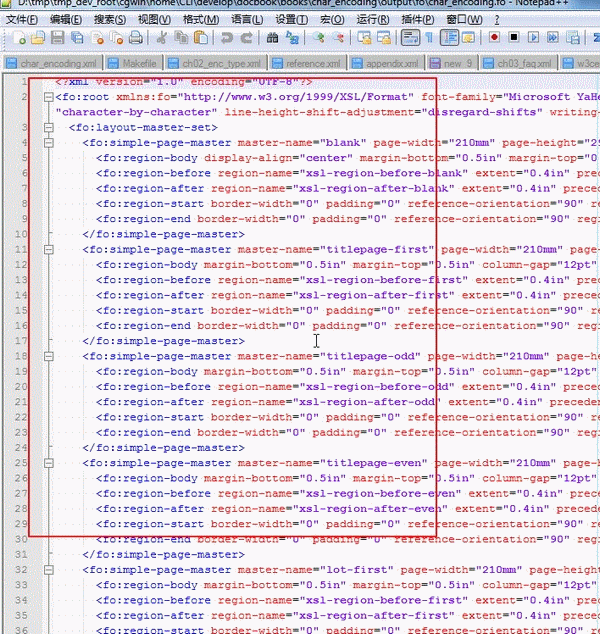
可以看出,仅仅是单一的27行,其内容已经太多了,多到鼠标也要拖动很多个屏幕,才能完全选中此行的内容。选中后,然后将此行的拷贝出来,放到新建的文件中去:
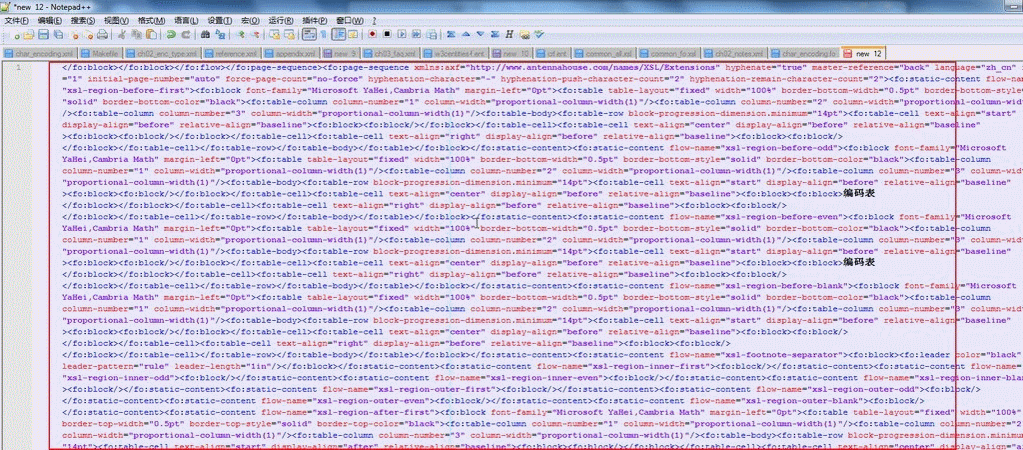 |
然后再去定位到行尾偏移量127554的位置:
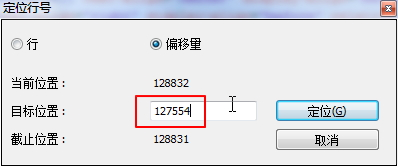 |
找到出错的位置:
 |
可以看出,此处即使找到了所指示的出错位置,也很难找到具体错在哪里。因为代码实在太多,很难找到是哪里错误的。
调试有缩进的(xml格式的)fo文件. 对于上述所面临的很难定位错误的问题,解决办法是,配置xml格式的fo的输出中,是带代码缩进的:
<xsl:output method="xml"
encoding="UTF-8"
indent="yes"/>
这样,生成的xml格式的fo文件,就变成这样了:
 |
对应的出错的提示中,行号和行内位置,也都变了:
javax.xml.transform.TransformerException: org.apache.fop.fo.ValidationException: "fo:table" is missing child elements. Required content model: (marker*,table-column*,table-header?,table-footer?,table-body+) (See position 7594:441)
at org.apache.fop.cli.InputHandler.transformTo(InputHandler.java:302)
at org.apache.fop.cli.InputHandler.renderTo(InputHandler.java:130)
at org.apache.fop.cli.Main.startFOP(Main.java:174)
at org.apache.fop.cli.Main.main(Main.java:205)
变成错误行号是7594,行内偏移量是441了。然后就去跳转到对应的行:
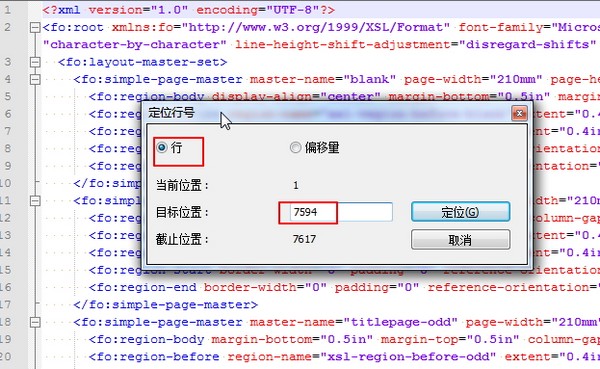 |
找到错误的位置:
 |
然后类似的,把整行内容拷贝出来,然后再去跳转到行内位置441:
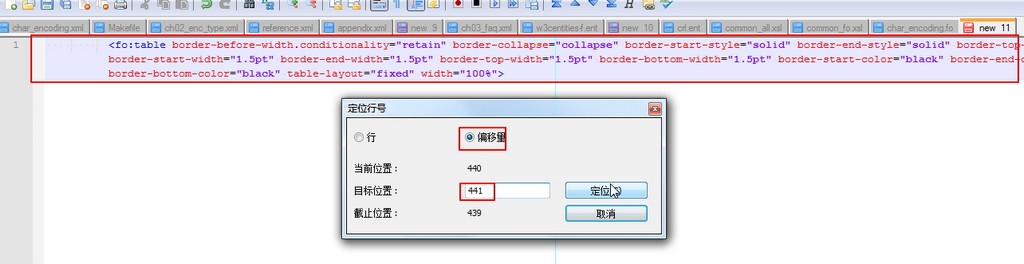 |
这样,在不是很多的一行内,就很容易找到对应错误位置,然后具体分析错误的原因了。
 |  |  |
| 2.6. Docbook开发过程中如何调试错误 |  | 2.7. Docbook开发过程中的一些感悟 |