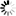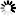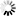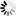decode函数,是str类型变量本身就有的函数,用于实现将某种编码的字符,解码为Unicode类型字符。
将某种编码的str字符解码为Unicode字符,通常做法为:
defCmtCharset = "GB18030";
dataJsonStrUni = dataJsonStr.decode(defCmtCharset);
不过,上述用法,是在你知道了字符编码的前提下,才能这么做的。
如果是对于输入的字符串,可能是多种不同的编码,即无法确定输入字符编码的前提下,想要对其解码的话,可以这么实现:
先利用chardet判断字符编码类型,然后再去解码:
possibleCharset = crifanLib.getStrPossibleCharset(dataJsonStr);
dataJsonStrUni = dataJsonStr.decode(possibleCharset);
其中getStrPossibleCharset是我自己写的函数
但是,有时候,你会发现,即使如此,也可能遇到decode失败的情况。
因为有时候所输入的字符串,本身不完全是某种单一的编码,而是2种或更多种不同的编码的混合体,此时,此处通过getStrPossibleCharset中的chardet所得到的值,就未必是0.99,而可能是某个很低的值,比如0.6,此时用此编码去解码,就可能遇到失败的情况了。
这种变态的,多种编码混合的字符串,我之前就在折腾给BlogsToWordpress添加QQ空间支持的过程中,处理QQ空间帖子的评论数据中,就遇到过。
当时很是郁闷,无法有效解决此问题,导致对于有些帖子的评论数据,无法继续处理。
直到后来,直到对于decode函数来说,还有个ignore参数,可以实现,在解码过程中,对于那些(用当前编码)无法解码的,不支持的字符,采取忽略的策略,而使得不会出现解码失败,然后最终可以成功解码整个字符串。
对应的函数详细解释,在Python的帮助文档中可以找到:
str.decode([encoding[, errors]]). Decodes the string using the codec registered for encoding. encoding defaults to the default string encoding. errors may be given to set a different error handling scheme. The default is 'strict', meaning that encoding errors raise UnicodeError. Other possible values are 'ignore', 'replace' and any other name registered via codecs.register_error(), see section Codec Base Classes.New in version 2.2.Changed in version 2.3: Support for other error handling schemes added.Changed in version 2.7: Support for keyword arguments added.
然后,上述的代码,改为:
defCmtCharset = "GB18030";
dataJsonStrUni = dataJsonStr.decode(defCmtCharset, 'ignore');
即可实现,对于绝大多数的GB18030的中文字符,都可以正确解码为Unicode字符了。
即使遇到一些变态的混合型编码的字符(比如其中一部分是ISO-8859-2编码,其他部分是其他的某种编码),也不会出现decode出错,而使得代码可以继续运行了。
当然,需要注意一点的是,我这里,其中被ignore的个别特殊字符,由于是在评论的数据中的个别特殊字符,所以不重要,忽略了也无所谓,所以才可以使用ignore参数的。要是你的代码中,不允许忽略任何内容,那你就得想其他办法了。
 |  |  |
| 2.1.2. 在处理中文简体和中文繁体的的时候,使用目标编码中不存在的中文字符,也会导致UnicodeEncodeError |  | 第 3 章 Python中常见的字符串和编码等相关的处理 |