折腾:
【未解决】Selenium中Python解析百度搜索结果第一页获取标题列表
期间,接着要去搞清楚:
如何用Selenium,去实现,查询定位到,百度搜索结果中每一条的title标题的元素。
【整理】用Chrome或Chromium查看百度首页中各元素的html源码
好了,可以去想办法写代码,获取每条结果的内容了。至少先获取到标题的文字。
先去看看此处,Selenium中,有何函数可用,用来获取元素内容。
看自己的教程
“* 属性
* id
* location
* parent
* rect
* screenshot_as_png
* size
* text
* tag_name”
是可以获取到text的
去看看
不过先要搞清楚,如何定位查找到这些搜索结果
对于想要找搜索标题,看起来是需要:
找到
<h3 class="t"> <h3 class="t c-title-en">
下面的a元素
然后才能获取到a的href链接地址
和内部的值:
<em>crifan</em> – 在路上 <em>crifan</em> (<em>Crifan</em> Li) · GitHub
看了下,感觉是用xpath更合适?
直接h3定位,要额外支持class中包含t才行,好像不好写语法
用xpath的话,class要支持contain写法
xpath contains text
试了试:
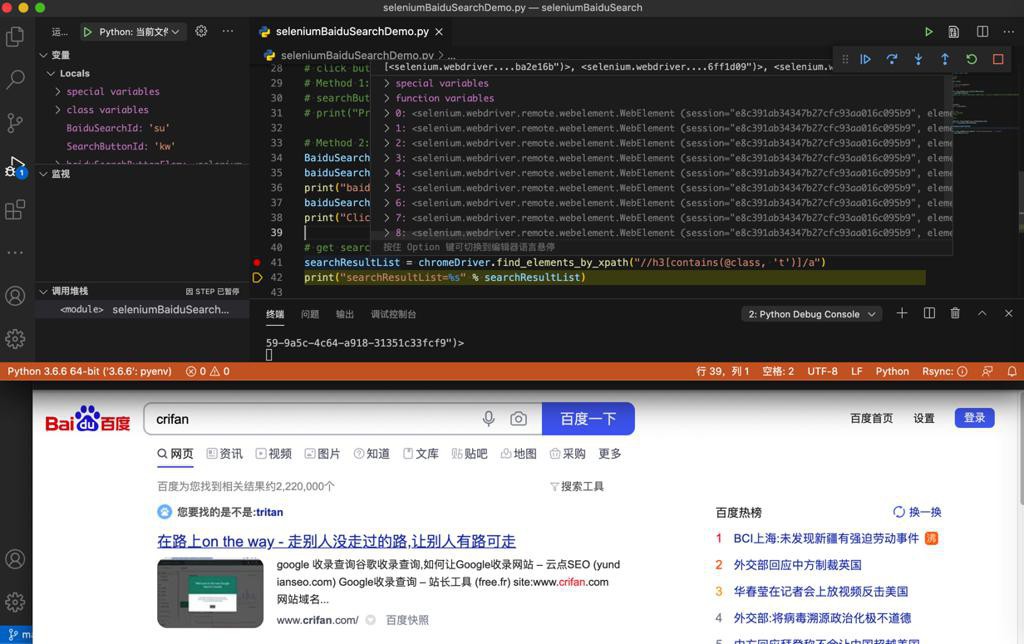
# get search result item list
searchResultList = chromeDriver.find_elements_by_xpath("//h3[contains(@class, 't')]/a")
print("searchResultList=%s" % searchResultList)真的可以搜到:
那继续写代码
继续获取a的href属性试试
lement = driver.find_element_by_name(self.locator)
return element.get_attribute("value")去试试:get_attribute
for curIdx, curSearchResultAElem in enumerate(searchResultAList):
print("%s [%d] %s" % ("-"*20, curIdx, "-"*20))
aHref = curSearchResultAElem.get_attribute("href")
print("aHref=%s" % aHref)
aText = curSearchResultAElem.text
print("aText=%s" % aText)即可。
期间遇到:
【已解决】Selenium调试时能搜到元素但是直接运行找不到
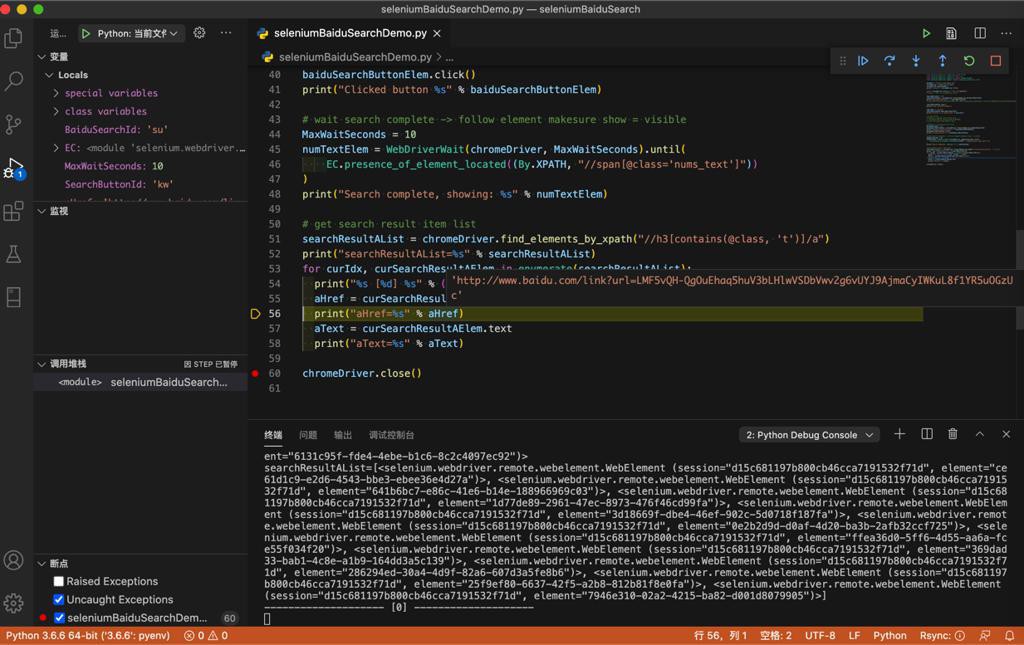
可以获取到href值:
aHref=http://www.baidu.com/link?url=LMF5vQH-QgOuEhaq5huV3bLHlwVSDbVwv2g6vUYJ9AjmaCyIWKuL8f1YR5uOGzUc
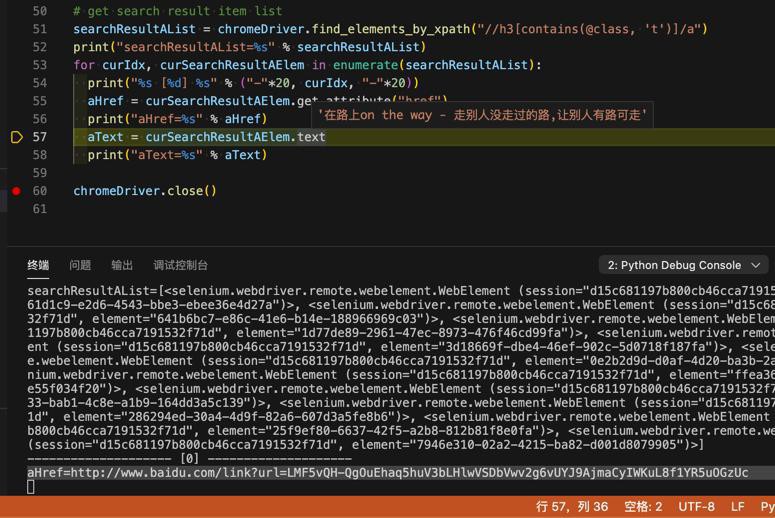
也能获取到 当前搜索结果的title的text:
aText=在路上on the way - 走别人没走过的路,让别人有路可走
所以是可以实现所需效果的:
获取到搜索结果的每一条的标题的文字(和链接地址)
【总结】
此处最终用:
# get search result item list
searchResultAList = chromeDriver.find_elements_by_xpath("//h3[contains(@class, 't')]/a")
print("searchResultAList=%s" % searchResultAList)
for curIdx, curSearchResultAElem in enumerate(searchResultAList):
print("%s [%d] %s" % ("-"*20, curIdx, "-"*20))
aHref = curSearchResultAElem.get_attribute("href")
print("aHref=%s" % aHref)
aText = curSearchResultAElem.text
print("aText=%s" % aText)定位到:
百度搜索结果中每一条的标题文字和链接地址。
转载请注明:在路上 » 【已解决】Selenium中如何实现百度搜索结果标题元素的定位