折腾:
【未解决】Mac中用Selenium自动操作浏览器实现百度搜索
期间,已经用Selenium实现了百度首页的输入并搜索,显示出搜索结果了:
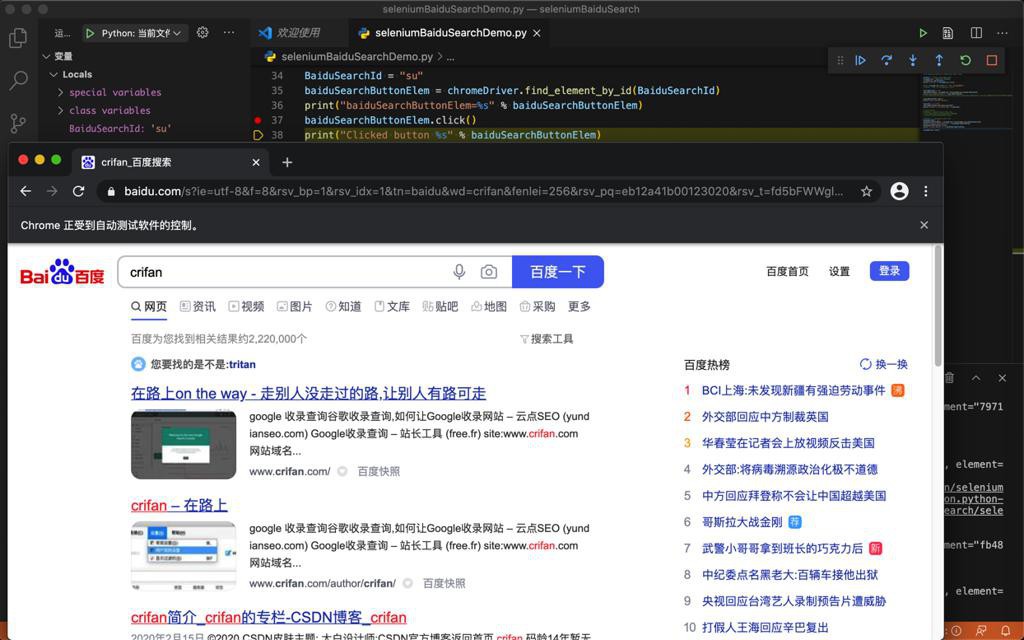
接下来,想办法实现,解析出搜索结果的标题的列表
此处尽量用多种方式去获取到最终结果,以演示如何写代码解析网页内容。
其中一种,和此处最相关的是,用Selenium自带的函数。
然后去:
【已解决】Selenium中如何实现百度搜索结果标题元素的定位
用Selenium的代码是:
# get search result item list
searchResultAList = chromeDriver.find_elements_by_xpath("//h3[contains(@class, 't')]/a")
print("searchResultAList=%s" % searchResultAList)
for curIdx, curSearchResultAElem in enumerate(searchResultAList):
print("%s [%d] %s" % ("-"*20, curIdx, "-"*20))
aHref = curSearchResultAElem.get_attribute("href")
print("aHref=%s" % aHref)
aText = curSearchResultAElem.text
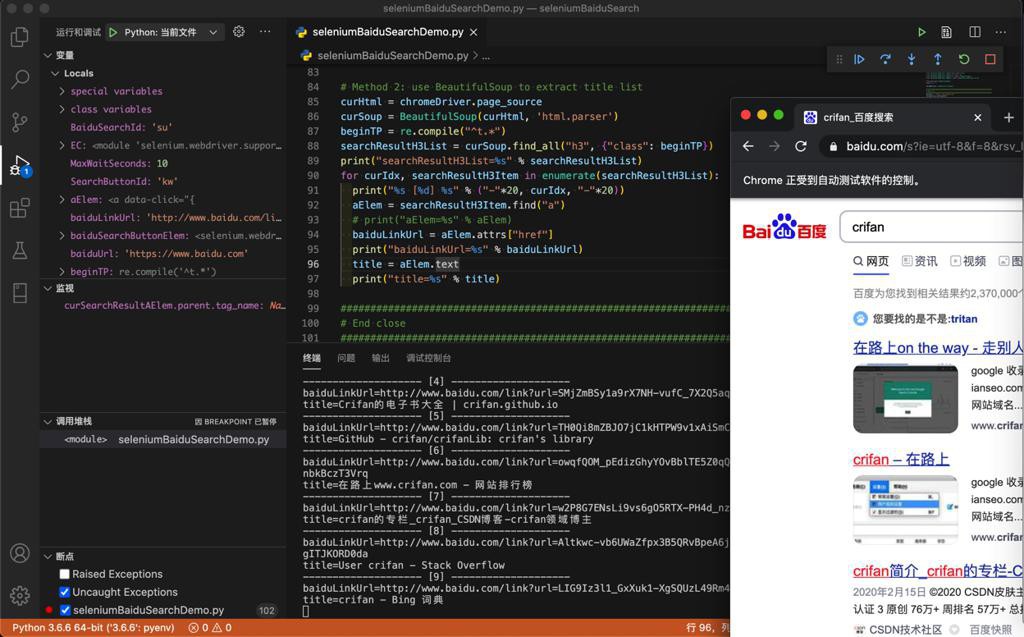
print("aText=%s" % aText)输出:
-------------------- [0] -------------------- aHref=http://www.baidu.com/link?url=LMF5vQH-QgOuEhaq5huV3bLHlwVSDbVwv2g6vUYJ9AjmaCyIWKuL8f1YR5uOGzUc aText=在路上on the way - 走别人没走过的路,让别人有路可走 -------------------- [1] -------------------- aHref=http://www.baidu.com/link?url=n4QoZVrJ5gncFIpJZhRcdmoA-oEmVewHEriXaLesj_wuypw3ZGebZ8sgC56-3ueD aText=crifan – 在路上 -------------------- [2] -------------------- aHref=https://www.baidu.com/link?url=N1OgXdaJPO9zLGVbKm5lrRD53sKIgPXnWg_4yMTtm0Do5kyKMHPNxMOHUXePGIgEuLTGc9LFgtxuHXZu1oTZba&wd=&eqid=eb6d0c370028fb9b00000004605df63e aText=crifan简介_crifan的专栏-CSDN博客_crifan -------------------- [3] -------------------- aHref=http://www.baidu.com/link?url=trh6Nvw5xKEgQIi5OMxz6Dpaol45mKCetSyFG6jspja4suH7tcgRrzFOvJTarNmW aText=crifan的微博_微博 -------------------- [4] -------------------- aHref=http://www.baidu.com/link?url=rj2E9lqd9iFHWNV-9O-CXLOSMAJLazrFdp0-ERlbbVZyqKK_DzA21oBIV42W1NfQ aText=Crifan的电子书大全 | crifan.github.io -------------------- [5] -------------------- aHref=http://www.baidu.com/link?url=LgitikJywqZ5Cp-kCVddlAalVnhpUn7oRC_PRJlU_SB2NKPDSr4zcGpgsKanlx9S aText=GitHub - crifan/crifanLib: crifan's library -------------------- [6] -------------------- aHref=http://www.baidu.com/link?url=ag8E9gi5fxiiAetDLFkyFcRt0JDpYeUzT2JkJ19j-WjEY6qpYKsXCxN14pkDS0fYFH6fkIeOS0wl3u1diuVBPK aText=在路上www.crifan.com - 网站排行榜 -------------------- [7] -------------------- aHref=http://www.baidu.com/link?url=sLYSlrlBaGvNq0iT1bAOFXWU1_owJB3Zpw35xI_esHFcHfToQ5J920ypHXOWBraj aText=crifan的专栏_crifan_CSDN博客-crifan领域博主 -------------------- [8] -------------------- aHref=http://www.baidu.com/link?url=naLo4Rd4SAqiJ6PPtU6KAWJ9p5wNXnMwejFMcPoHuHwUUrlx2a2PRibCeFrR1yO1hcsDwFUXVVNIBJI03mHBca aText=User crifan - Stack Overflow -------------------- [9] -------------------- aHref=http://www.baidu.com/link?url=wm4YOCeoG-84H2glTjRfwGZ1JY9slAu1MeUtuAQVE9yKSK-14IeyeY1b-BfxWKH3 aText=crifan - Bing 词典
效果:
另外
- get_attribute(name)
- get_property(name)
回头都试试
其中可见,对于,从复杂的html代码解析出所需要的值,往往比较费精力
对此,其实Python中有更专业的库干这个:BeautifulSoup
接着去想办法看看,能否获取Selenium的当前页面的html,然后在用BeautifulSoup去解析获取所需的值
那去搞清楚:
【已解决】Selenium中如何获取到当前页面的html源码
然后去写代码:
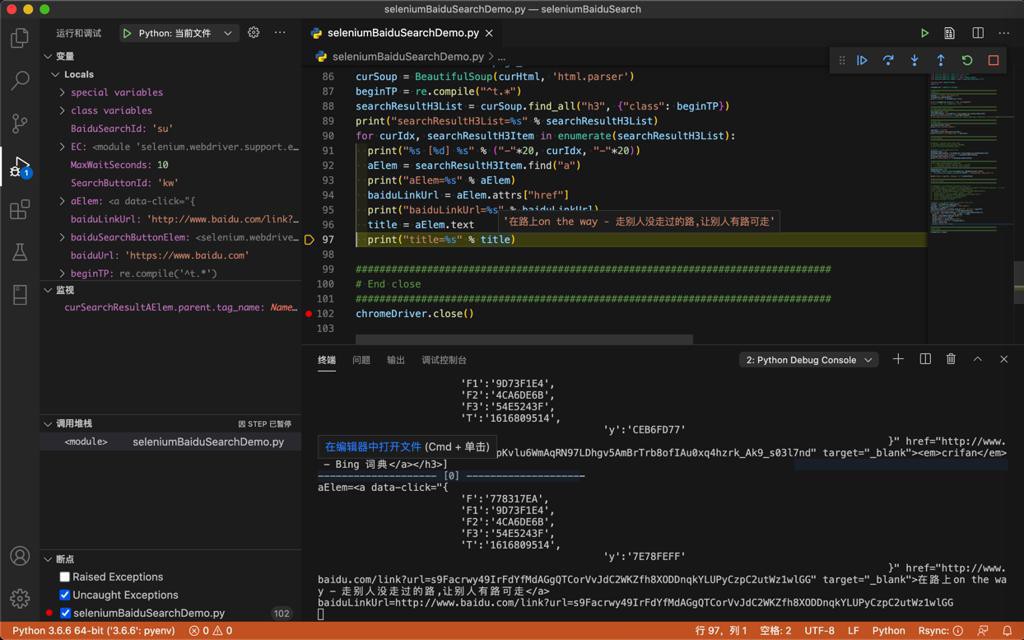
# Method 2: use BeautifulSoup to extract title list
curHtml = chromeDriver.page_source
curSoup = BeautifulSoup(curHtml, 'html.parser')
beginTP = re.compile("^t.*")
searchResultH3List = curSoup.find_all("h3", {"class": beginTP})
print("searchResultH3List=%s" % searchResultH3List)经过调试,是可以找到H3的元素的:
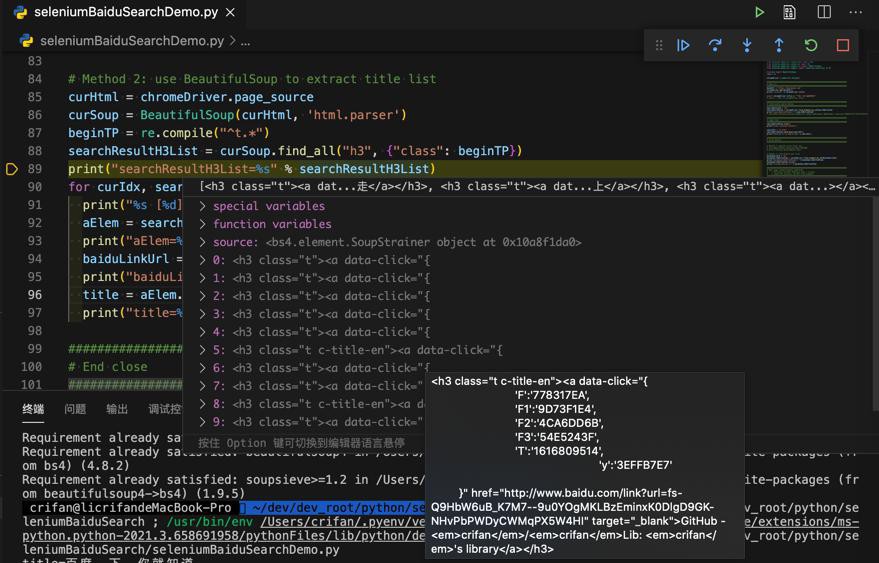
继续调试:
for curIdx, searchResultH3Item in enumerate(searchResultH3List):
print("%s [%d] %s" % ("-"*20, curIdx, "-"*20))
aElem = searchResultH3Item.find("a")
print("aElem=%s" % aElem)
baiduLinkUrl = aElem.attrs["href"]
print("baiduLinkUrl=%s" % baiduLinkUrl)
title = aElem.text
print("title=%s" % title)是可以的:
【总结】
至此,用BeautifulSoup的代码去解析出百度搜索结果的列表:
# Method 2: use BeautifulSoup to extract title list
curHtml = chromeDriver.page_source
curSoup = BeautifulSoup(curHtml, 'html.parser')
beginTP = re.compile("^t.*")
searchResultH3List = curSoup.find_all("h3", {"class": beginTP})
print("searchResultH3List=%s" % searchResultH3List)
for curIdx, searchResultH3Item in enumerate(searchResultH3List):
print("%s [%d] %s" % ("-"*20, curIdx, "-"*20))
aElem = searchResultH3Item.find("a")
# print("aElem=%s" % aElem)
baiduLinkUrl = aElem.attrs["href"]
print("baiduLinkUrl=%s" % baiduLinkUrl)
title = aElem.text
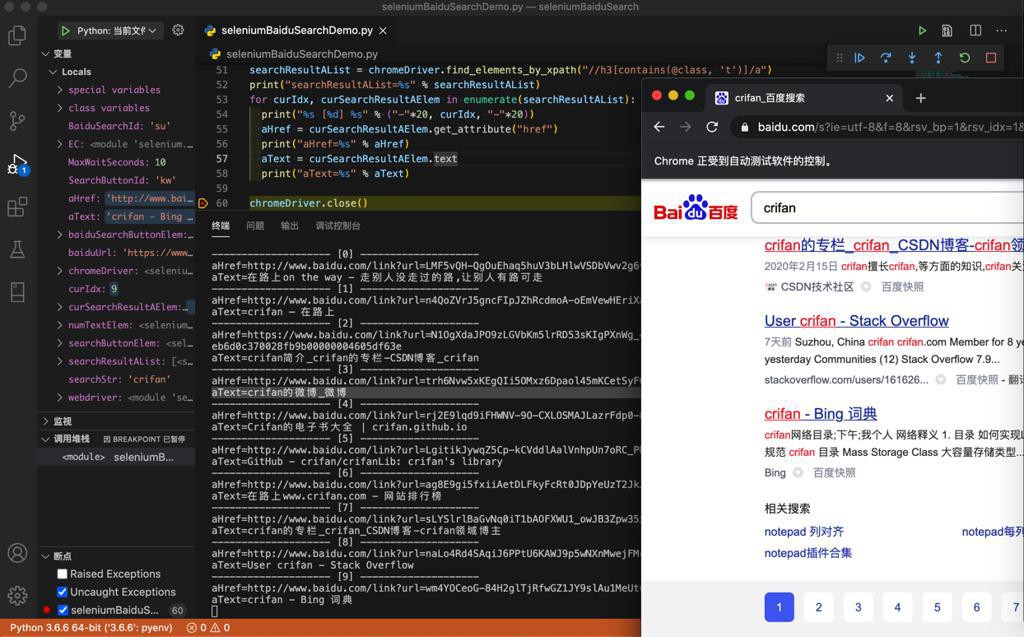
print("title=%s" % title)输出:
-------------------- [0] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=DVUbOETLyMZLC5c_V7RJReScFExnTjXjyTsO_QO_0rOL0vSE4mMNIPaZLH7iIaHI title=在路上on the way - 走别人没走过的路,让别人有路可走 -------------------- [1] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=xA8mzlRBwfRb_I-PgUMj9_COWGmdEr-GcNo-DlxCqYzTKYsjqpLrmQImHO5X41Qy title=crifan – 在路上 -------------------- [2] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=v8Doo53CgO-cFNYo-Wp2FKL8zfOxvuzhOmwSeTLzCqGA_AOjbYcjYdovqikkMmJifiQhJ6dLSMC_UW0VERBRma title=crifan简介_crifan的专栏-CSDN博客_crifan -------------------- [3] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=69wfHGVLYJIn71DQl_6aD9bf2LAthOALzmUxqZLgYKL_v44CcN7JPV0fZdsgDQnw title=crifan的微博_微博 -------------------- [4] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=SMjZmBSy1a9rX7NH-vufC_7X2Q5aqYT1dZQKHpttphLiMkTfr6ZgRFeUT3K8PNW7 title=Crifan的电子书大全 | crifan.github.io -------------------- [5] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=TH0Qi8mZBJO7jC1kHTPW9v1xAiSmC2TgDwWA2di1cX0Eph8cJr6wRQFDES61P_DN title=GitHub - crifan/crifanLib: crifan's library -------------------- [6] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=owqfQOM_pEdizGhyYOvBblTE5Z0qQTr3D23ndhxxoIS0K28x4f2xVYMJdb6jwRb30vZHpm1MQDunbkBczT3Vrq title=在路上www.crifan.com - 网站排行榜 -------------------- [7] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=w2P8G7ENsLi9vs6gO5RTX-PH4d_nzPud16wY1Er2ouGTQ4caZODnyj4PY2dTh1rI title=crifan的专栏_crifan_CSDN博客-crifan领域博主 -------------------- [8] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=Altkwc-vb6UWaZfpx3B5QRvBpeA6jvcvlmasdkl5-31FY8QmvI1YQaYlQwrrRT2h0QxoI4QCfGFgITJKORD0da title=User crifan - Stack Overflow -------------------- [9] -------------------- baiduLinkUrl=http://www.baidu.com/link?url=LIG9Iz3l1_GxXuk1-XgSQUzL49Rm4q7pTCekyI_ehU4yrSKCWsEc-c6ya598vsml title=crifan - Bing 词典
效果: