折腾:
期间,本地调试可以正常下载文件的,比如:
https://img.xiaohuasheng.cn/Audio/2022/20180912141716840.mp3
但是去PySpider中开始RUN
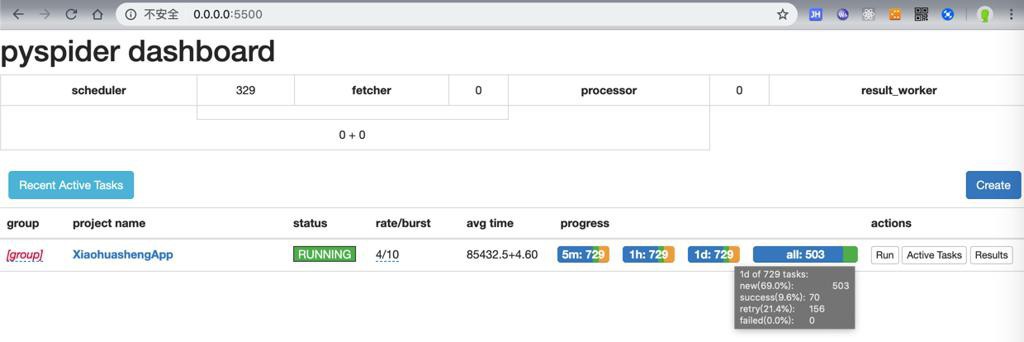
开始批量下载时,结果报错:
[E 190411 14:27:32 tornado_fetcher:212] [599] XiaohuashengApp:b35ca6788da24132245924cb4ec084c7
, HTTP 599: Operation timed out after 120000 milliseconds with 1723300 out of 2343850 bytes received 120.00s
[E 190411 14:27:32 processor:202] process XiaohuashengApp:b35ca6788da24132245924cb4ec084c7
-> [599] len:0 -> result:None fol:0 msg:0 err:Exception('HTTP 599: Operation timed out after 120000 milliseconds with 1723300 out of 2343850 bytes received',)
[I 190411 14:27:32 scheduler:959] task retry 0/3 XiaohuashengApp:b35ca6788da24132245924cb4ec084c7
https://img.xiaohuasheng.cn/Audio/2022/20180912141716840.mp3如图:
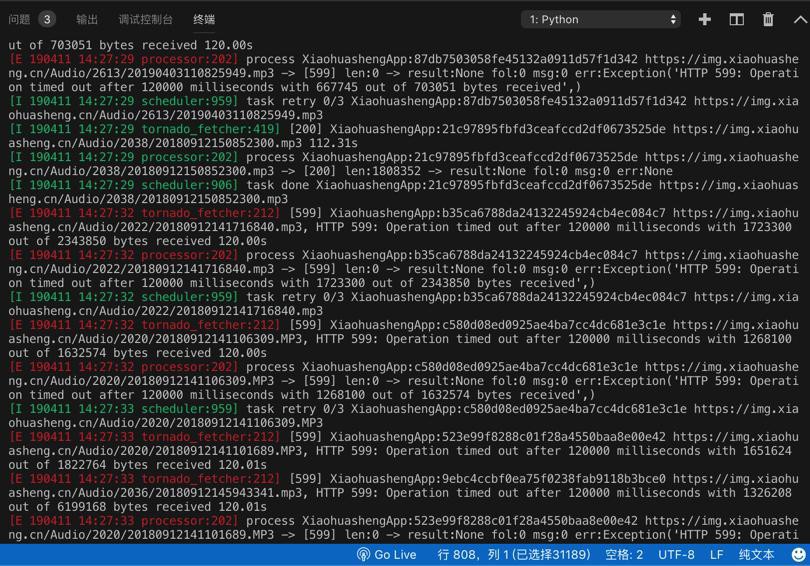
很是奇怪。
PySpider HTTP 599 Operation timed out after milliseconds with out of bytes received
“百度 谷歌了N久都没找到解决方案,有的说DNS的,然而我这边校园网改了DNS就上不了网了,有说禁用IPV6的,同样没效果,绝望之际,打开QQ找了个pyspider的群,问老司机得知,加个代理就好… 遂顺手加了个翻墙代理(跟墙没关,只是刚好有翻墙的),马上可以
crawl_config = {
‘proxy’: ‘127.0.0.1:1080’
“
如果真是这个原因,那真是诡异了。。。
不对,估计是:
此处需要加上UA等参数?
去试试
加上:
connect_timeout = 50,
timeout = 200
参考自己的:
【记录】用PySpider去爬取scholastic的绘本书籍数据
和:
“connect_timeout
timeout for initial connection in seconds. default: 20
timeout
maximum time in seconds to fetch the page. default: 120
retries
retry times while failed. default: 3”
用,都增加了5倍:
class Handler(BaseHandler):
crawl_config = {
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
}结果
还没试之前,注意到:
after 120000 milliseconds with 1723300 out of 2343850 bytes
感觉是:
120秒,下载了 1723300/2343850=70%多,没下载完毕
所以报告超时了
所以估计此处增加时间,应该是有效果,至少是部分效果的。
所以去试试
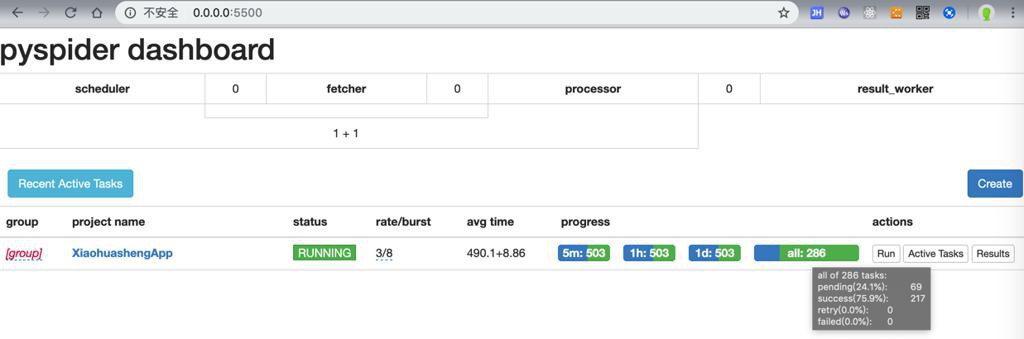
貌似就可以正常继续下载了:
log可以输出正常,无错误:
下载到的文件:
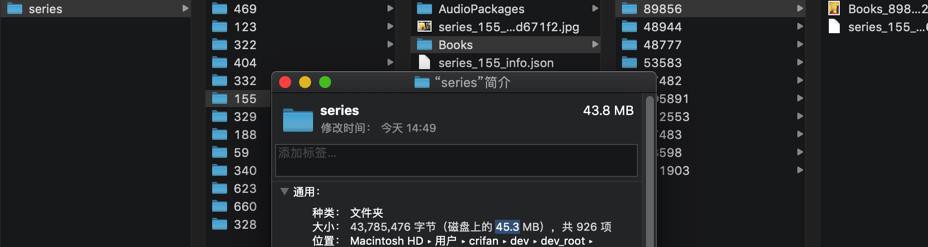
没过几分钟又报错了:
[E 190411 14:53:25 tornado_fetcher:212] [599] XiaohuashengApp:3f10a6bafc41ed6c7ac067f93d04be4b https://img.xiaohuasheng.cn/Audio/1965/20180912111556087.mp3, HTTP 599: Operation timed out after 120000 milliseconds with 2251491 out of 17047152 bytes received 120.01s
[E 190411 14:53:25 tornado_fetcher:212] [599] XiaohuashengApp:a9bd9d1cea268b90c377814027835ca6 https://img.xiaohuasheng.cn/Audio/1965/20180912111438398.mp3, HTTP 599: Operation timed out after 120003 milliseconds with 2221888 out of 18504144 bytes received 120.01s
[E 190411 14:53:25 processor:202] process XiaohuashengApp:3f10a6bafc41ed6c7ac067f93d04be4b https://img.xiaohuasheng.cn/Audio/1965/20180912111556087.mp3 -> [599] len:0 -> result:None fol:0 msg:0 err:Exception('HTTP 599: Operation timed out after 120000 milliseconds with 2251491 out of 17047152 bytes received',)
[E 190411 14:53:25 processor:202] process XiaohuashengApp:a9bd9d1cea268b90c377814027835ca6 https://img.xiaohuasheng.cn/Audio/1965/20180912111438398.mp3 -> [599] len:0 -> result:None fol:0 msg:0 err:Exception('HTTP 599: Operation timed out after 120003 milliseconds with 2221888 out of 18504144 bytes received',)
[I 190411 14:53:25 scheduler:959] task retry 0/3 XiaohuashengApp:3f10a6bafc41ed6c7ac067f93d04be4b https://img.xiaohuasheng.cn/Audio/1965/20180912111556087.mp3
[I 190411 14:53:25 scheduler:959] task retry 0/3 XiaohuashengApp:a9bd9d1cea268b90c377814027835ca6 https://img.xiaohuasheng.cn/Audio/1965/20180912111438398.mp3
[E 190411 14:53:26 tornado_fetcher:212] [599] XiaohuashengApp:bf03ff6a32cb9fd5e62ef03dd20c1936 https://img.xiaohuasheng.cn/Audio/1965/20180912111337798.mp3, HTTP 599: Operation timed out after 120000 milliseconds with 2023342 out of 14151680 bytes received 120.01s
[E 190411 14:53:26 processor:202] process XiaohuashengApp:bf03ff6a32cb9fd5e62ef03dd20c1936 https://img.xiaohuasheng.cn/Audio/1965/20180912111337798.mp3 -> [599] len:0 -> result:None fol:0 msg:0 err:Exception('HTTP 599: Operation timed out after 120000 milliseconds with 2023342 out of 14151680 bytes received',)
[I 190411 14:53:26 scheduler:959] task retry 0/3 XiaohuashengApp:bf03ff6a32cb9fd5e62ef03dd20c1936 https://img.xiaohuasheng.cn/Audio/1965/20180912111337798.mp3
[E 190411 14:53:26 tornado_fetcher:212] [599] XiaohuashengApp:4de7a1f26d3a6132b9ac597db476d30c https://img.xiaohuasheng.cn/Audio/1965/20180912111240009.mp3, HTTP 599: Operation timed out after 120001 milliseconds with 2082548 out of 14578560 bytes received 120.01s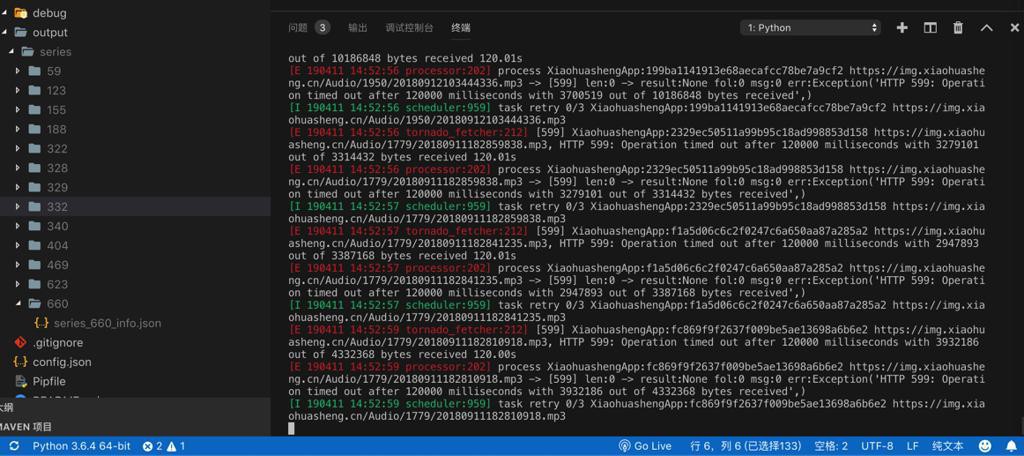
不过从错误日志中看,还是没有下载完毕
->看来是网络速度太慢了
-》发起的下载请求太多了,网络慢,处理不过来,导致超时
-》那回头(用自家的Wifi)更快的100M的网络,试试,估计就可以正常下载了。
而此处由于下载错误太多,都暂停下载了:
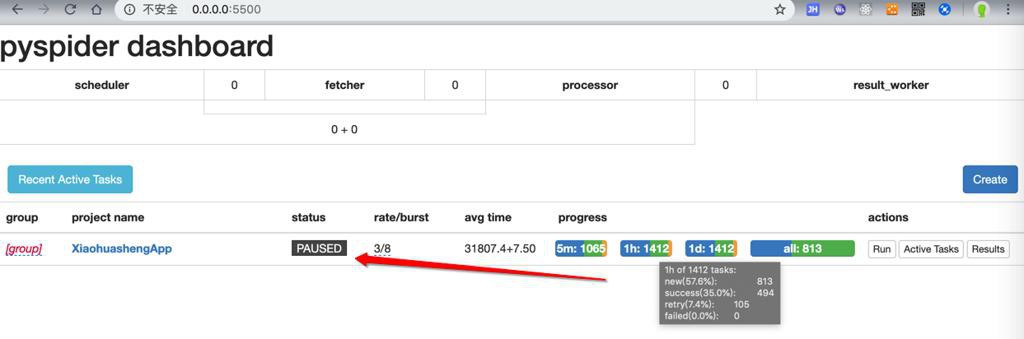
此处感觉只是网络速度问题,而幸好不是之前的:
【未解决】PySpider批量爬取时出现各种出错:UnboundLocalError+HTTP 599+Operation timed out+IndexError
这种错误,否则就郁闷,就不好解决了。
此处刚发现,上面改了代码,但是更新上去了。
现在重新加上,试试效果,共爬取数据:
- 50多MB:目前没出错
- 70多MB:没出错,但是像卡住不继续了
- 100MB:没出错,不够速度是很慢
- 600多MB:很慢。
算了,还是暂停,回家用家里快的网络下载吧。
这个下载的太慢了。
回到家,用10MB/s的网络下载:
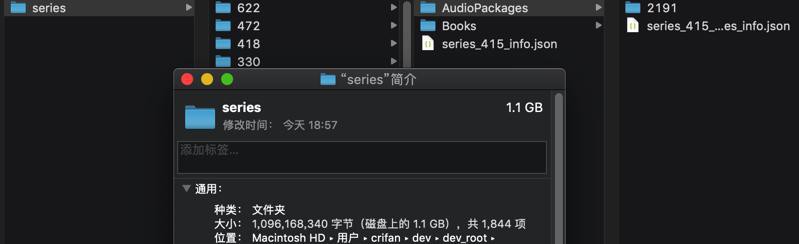
速度不错:
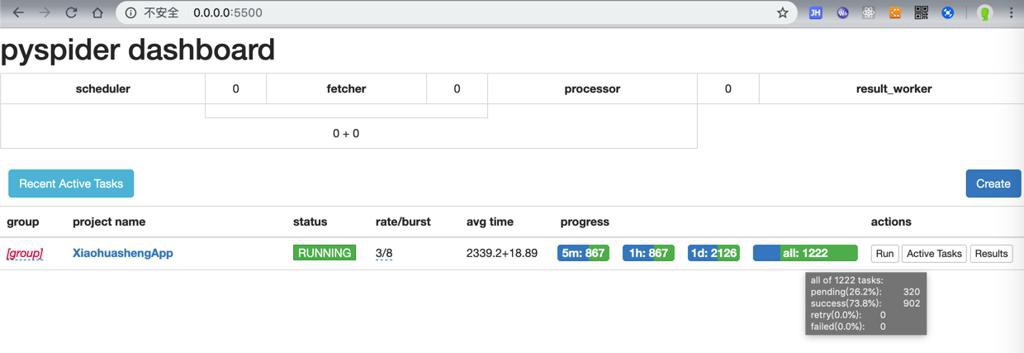
继续下载看看吧。
不错,一直没出错:
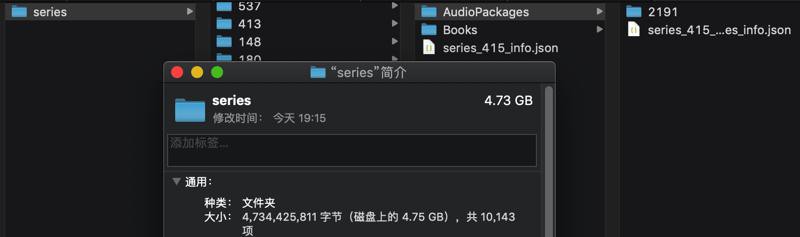
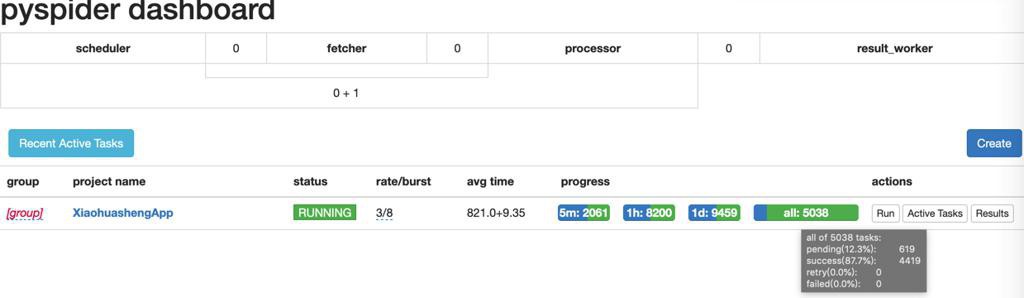
然后知道最后,就下载好了。
不过后续发现有些缺失:
【未解决】PySpider看似下载完成但是部分图片资源没有下载
转载请注明:在路上 » 【已解决】PySpider运行批量下载时报错:HTTP 599 Operation timed out after milliseconds with out of bytes received