折腾:
【记录】用PySpider去爬取scholastic的绘本书籍数据
期间,现在对于:
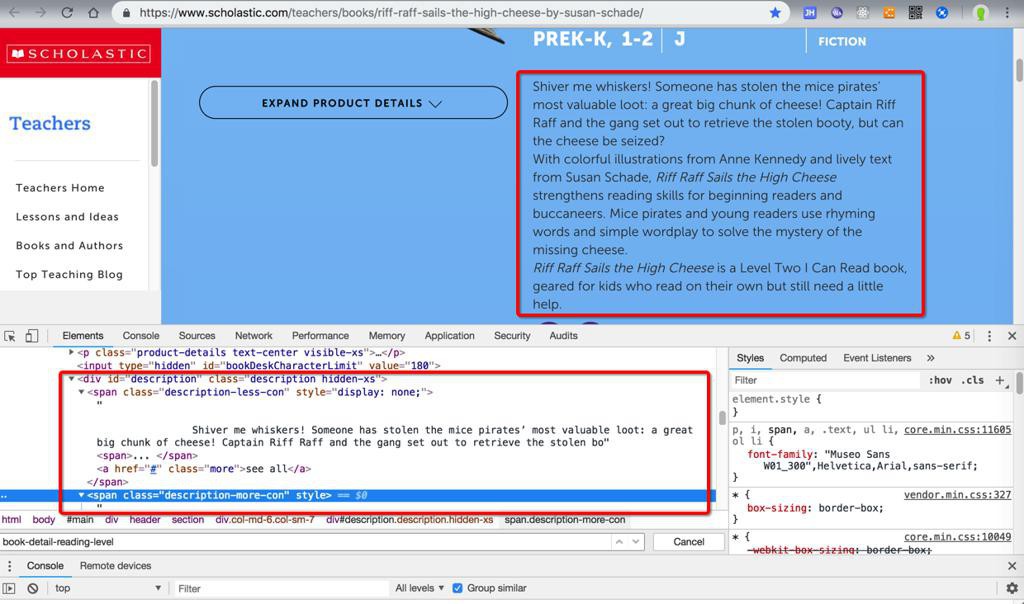
已经用代码:
(注意 html的节点,在PySpider爬取出来的 和 浏览器中的 略有不同)
description = ""
descriptionElement = response.doc('div[id="description"]')
print("descriptionElement=%s" % descriptionElement)
# descLessElement = descriptionElement.find('span[class="description-less-con"]')
# print("descLessElement=%s" % descLessElement)
# descLessText = descLessElement.text()
# print("descLessText=%s" % descLessText)
# descMoreLement = descriptionElement.find('span[class="description-more-con"]')
# print("descMoreLement=%s" % descMoreLement)
# if descMoreLement:
# descMoreText = descMoreLement.text()
# print("descMoreText=%s" % descMoreText)
descriptionText = descriptionElement.text()
print("descriptionText=%s" % descriptionText)已经得到了:
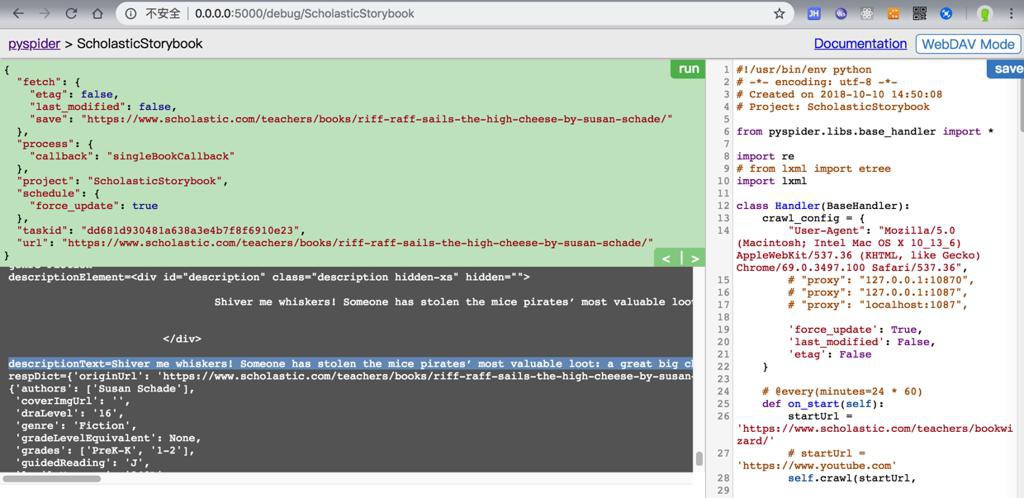
descriptionText=Shiver me whiskers! Someone has stolen the mice pirates’ most valuable loot: a great big chunk of cheese! Captain Riff Raff and the gang set out to retrieve the stolen booty, but can the cheese be seized?<br />With colorful illustrations from Anne Kennedy and lively text from Susan Schade, <i>Riff Raff Sails the High Cheese</i> strengthens reading skills for beginning readers and buccaneers. Mice pirates and young readers use rhyming words and simple wordplay to solve the mystery of the missing cheese.<br /><i>Riff Raff Sails the High Cheese</i> is a Level Two I Can Read book, geared for kids who read on their own but still need a little help.
现在希望对于此处的,带br,带i的html的内容,转换为字符串,纯文本
-》去掉i,把br变成回车之类的
-》虽然可以手动替换,但是不严谨
所以要去找到更好的办法
看了一堆,貌似没什么好办法。
不过看到一个lxml.etree.tostring,所以去:
lxml.etree.tostring html to string
pyspider html remove tag to string
用re正则:不方便,还是手动自己替换
用bs:太重了
去试试:
def remove_tags(text): return ''.join(xml.etree.ElementTree.fromstring(text).itertext())
【已解决】Python中xml.etree.ElementTree出错:AttributeError: module ‘xml’ has no attribute ‘etree’
参考:
>>> from lxml import etree, html
>>> element = etree.fromstring('<p>Hel-lo World</p>')去改为lxml
import lxml # import xml def htmlToString(htmlText): # return ''.join(xml.etree.ElementTree.fromstring(htmlText).itertext()) return ''.join(lxml.etree.ElementTree.fromstring(htmlText).itertext())
结果:
出错:
[E 181011 11:55:58 base_handler:203] 'cython_function_or_method' object has no attribute 'fromstring' Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 176, in _run_task return self._run_func(function, response, task) File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 155, in _run_func ret = function(*arguments[:len(args) - 1]) File "<ScholasticStorybook>", line 227, in singleBookCallback File "<ScholasticStorybook>", line 19, in htmlToString AttributeError: 'cython_function_or_method' object has no attribute 'fromstring'
不过另外又报错:
[E 181011 13:33:22 base_handler:203] syntax error: line 1, column 0 Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 176, in _run_task return self._run_func(function, response, task) File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 155, in _run_func ret = function(*arguments[:len(args) - 1]) File "<ScholasticStorybook>", line 232, in singleBookCallback File "<ScholasticStorybook>", line 23, in htmlToString File "/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/xml/etree/ElementTree.py", line 1314, in XML parser.feed(text) File "<string>", line None xml.etree.ElementTree.ParseError: syntax error: line 1, column 0
python html to string
好像python有内置的html的库,和相关的HTMLParser
还是用的bs
其推荐用:html2text
算了,还是用bs吧,毕竟效果够好
默认安装BeautifulSoup会去安装BeautifulSoup 3,所以此处报错,不给安装:
➜ crawler_scholastic_storybook git:(master) ✗ pipenv install BeautifulSoup Installing BeautifulSoup... Looking in indexes: https://mirrors.ustc.edu.cn/pypi/web/simple Collecting BeautifulSoup Downloading https://mirrors.ustc.edu.cn/pypi/web/packages/1e/ee/295988deca1a5a7accd783d0dfe14524867e31abb05b6c0eeceee49c759d/BeautifulSoup-3.2.1.tar.gz Complete output from command python setup.py egg_info: Traceback (most recent call last): File "<string>", line 1, in <module> File "/private/var/folders/46/2hjxz38n22n3ypp_5f6_p__00000gn/T/pip-install-dxfdripk/BeautifulSoup/setup.py", line 22 print "Unit tests have failed!" ^ SyntaxError: Missing parentheses in call to 'print'. Did you mean print(int "Unit tests have failed!")? ---------------------------------------- Error: An error occurred while installing BeautifulSoup! Command "python setup.py egg_info" failed with error code 1 in /private/var/folders/46/2hjxz38n22n3ypp_5f6_p__00000gn/T/pip-install-dxfdripk/BeautifulSoup/ You are using pip version 18.0, however version 18.1 is available. You should consider upgrading via the 'pip install --upgrade pip' command. This is likely caused by a bug in BeautifulSoup. Report this to its maintainers.
所以去直接换成bs4:
➜ crawler_scholastic_storybook git:(master) ✗ pipenv install bs4 Installing bs4... Looking in indexes: https://mirrors.ustc.edu.cn/pypi/web/simple Collecting bs4 Downloading https://mirrors.ustc.edu.cn/pypi/web/packages/10/ed/7e8b97591f6f456174139ec089c769f89a94a1a4025fe967691de971f314/bs4-0.0.1.tar.gz Collecting beautifulsoup4 (from bs4) Downloading https://mirrors.ustc.edu.cn/pypi/web/packages/21/0a/47fdf541c97fd9b6a610cb5fd518175308a7cc60569962e776ac52420387/beautifulsoup4-4.6.3-py3-none-any.whl (90kB) Building wheels for collected packages: bs4 Running setup.py bdist_wheel for bs4: started Running setup.py bdist_wheel for bs4: finished with status 'done' Stored in directory: /Users/crifan/Library/Caches/pipenv/wheels/d8/e6/2f/a8e9e4058de6bf1a3d0cd64e23ba5fba27e75dc282e47a5077 Successfully built bs4 Installing collected packages: beautifulsoup4, bs4 Successfully installed beautifulsoup4-4.6.3 bs4-0.0.1 Adding bs4 to Pipfile's [packages]... Pipfile.lock (225a5b) out of date, updating to (4a06ee)... Locking [dev-packages] dependencies... Locking [packages] dependencies... Updated Pipfile.lock (4a06ee)! Installing dependencies from Pipfile.lock (4a06ee)... 🐍 ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 27/27 — 00:00
然后去用试试
from bs4 import BeautifulSoup
def htmlToString(htmlText):
soup = BeautifulSoup(htmlText)
print("soup=%s" % soup)
pureText = soup.text
print("pureText=%s" % pureText)
return pureText输出:
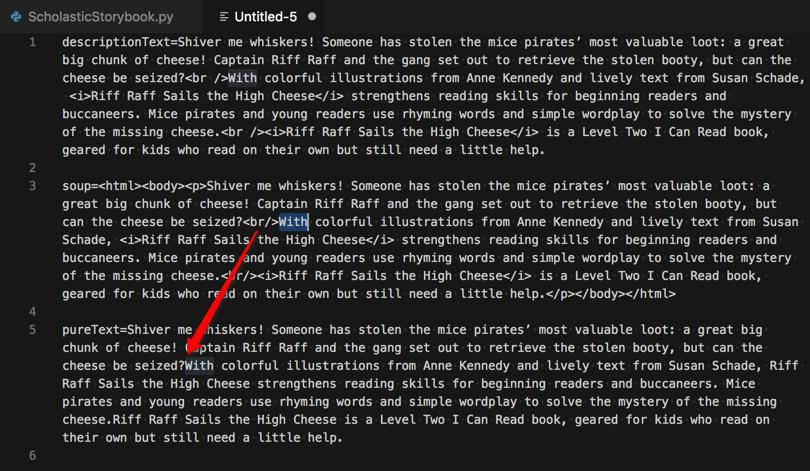
其中:
的确是可以得到text,但是缺少了:
把br替换为 换行
python html to text with new line
是我要问的,但是没有合适的解
python html to text br
python – Using beautifulsoup to extract text between line breaks (e.g. <br /> tags) – Stack Overflow
先去试试把
<br>
<br/>
<br />
换成\n试试看
代码:
from bs4 import BeautifulSoup
def htmlToString(htmlText, retainNewLine=True):
if retainNewLine:
htmlText = htmlText.replace("<br>", '\n')
htmlText = htmlText.replace("<br/>", '\n')
htmlText = htmlText.replace("<br />", '\n')
print("htmlText=%s" % htmlText)
soup = BeautifulSoup(htmlText)
print("soup=%s" % soup)
pureText = soup.text
print("pureText=%s" % pureText)
return pureText是可以到达到我要的效果的:
descriptionText=Shiver me whiskers! Someone has stolen the mice pirates’ most valuable loot: a great big chunk of cheese! Captain Riff Raff and the gang set out to retrieve the stolen booty, but can the cheese be seized?<br />With colorful illustrations from Anne Kennedy and lively text from Susan Schade, <i>Riff Raff Sails the High Cheese</i> strengthens reading skills for beginning readers and buccaneers. Mice pirates and young readers use rhyming words and simple wordplay to solve the mystery of the missing cheese.<br /><i>Riff Raff Sails the High Cheese</i> is a Level Two I Can Read book, geared for kids who read on their own but still need a little help. htmlText=Shiver me whiskers! Someone has stolen the mice pirates’ most valuable loot: a great big chunk of cheese! Captain Riff Raff and the gang set out to retrieve the stolen booty, but can the cheese be seized? With colorful illustrations from Anne Kennedy and lively text from Susan Schade, <i>Riff Raff Sails the High Cheese</i> strengthens reading skills for beginning readers and buccaneers. Mice pirates and young readers use rhyming words and simple wordplay to solve the mystery of the missing cheese. <i>Riff Raff Sails the High Cheese</i> is a Level Two I Can Read book, geared for kids who read on their own but still need a little help. soup=<html><body><p>Shiver me whiskers! Someone has stolen the mice pirates’ most valuable loot: a great big chunk of cheese! Captain Riff Raff and the gang set out to retrieve the stolen booty, but can the cheese be seized? With colorful illustrations from Anne Kennedy and lively text from Susan Schade, <i>Riff Raff Sails the High Cheese</i> strengthens reading skills for beginning readers and buccaneers. Mice pirates and young readers use rhyming words and simple wordplay to solve the mystery of the missing cheese. <i>Riff Raff Sails the High Cheese</i> is a Level Two I Can Read book, geared for kids who read on their own but still need a little help.</p></body></html> pureText=Shiver me whiskers! Someone has stolen the mice pirates’ most valuable loot: a great big chunk of cheese! Captain Riff Raff and the gang set out to retrieve the stolen booty, but can the cheese be seized? With colorful illustrations from Anne Kennedy and lively text from Susan Schade, Riff Raff Sails the High Cheese strengthens reading skills for beginning readers and buccaneers. Mice pirates and young readers use rhyming words and simple wordplay to solve the mystery of the missing cheese. Riff Raff Sails the High Cheese is a Level Two I Can Read book, geared for kids who read on their own but still need a little help.
【总结】
此处最终还是选择了(之前觉得有点重量级)的BeautifulSoup,去从:
带<br>和<i>等tag的html的字符串:
Shiver me whiskers! Someone has stolen the mice pirates’ most valuable loot: a great big chunk of cheese! Captain Riff Raff and the gang set out to retrieve the stolen booty, but can the cheese be seized?<br />With colorful illustrations from Anne Kennedy and lively text from Susan Schade, <i>Riff Raff Sails the High Cheese</i> strengthens reading skills for beginning readers and buccaneers. Mice pirates and young readers use rhyming words and simple wordplay to solve the mystery of the missing cheese.<br /><i>Riff Raff Sails the High Cheese</i> is a Level Two I Can Read book, geared for kids who read on their own but still need a little help.
在安装bs
pipenv install bs4
后,去用代码:
from bs4 import BeautifulSoup
def htmlToString(htmlText, retainNewLine=True):
if retainNewLine:
htmlText = htmlText.replace("
", '\n')
htmlText = htmlText.replace("<br/>", '\n')
htmlText = htmlText.replace("<br />", '\n')
print("htmlText=%s" % htmlText)
soup = BeautifulSoup(htmlText)
print("soup=%s" % soup)
pureText = soup.text
print("pureText=%s" % pureText)
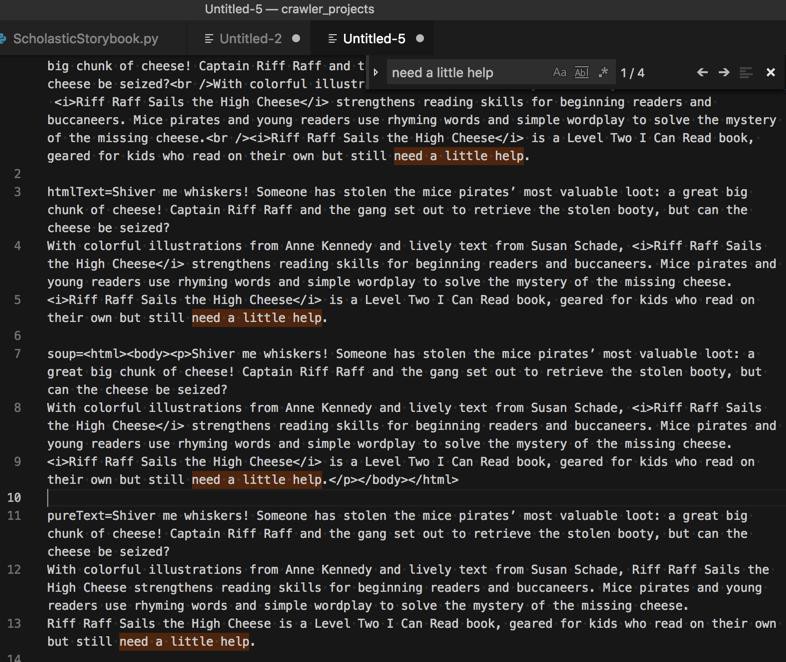
return pureText得到我们要的,带换行的字符串:
Shiver me whiskers! Someone has stolen the mice pirates’ most valuable loot: a great big chunk of cheese! Captain Riff Raff and the gang set out to retrieve the stolen booty, but can the cheese be seized? With colorful illustrations from Anne Kennedy and lively text from Susan Schade, Riff Raff Sails the High Cheese strengthens reading skills for beginning readers and buccaneers. Mice pirates and young readers use rhyming words and simple wordplay to solve the mystery of the missing cheese. Riff Raff Sails the High Cheese is a Level Two I Can Read book, geared for kids who read on their own but still need a little help.
【后记】
看到:
“from bs4 import Beautifulsoup
soup = Beautifulsoup(text)
print(soup.get_text(‘\n’))”
但是有人评论:
“In also places newlines in the middle of sentences if you have e.g. “<p>That’s <strong>not</strong> what I want</p>””
还是自己去看看官网文档:
自己去试试get_text()
果然如前面所说的:
- 直接用get_text():pureText = soup.get_text()
- -》只能得到文本,但是没有br变成换行
- 用get_text(‘\n’):pureText = soup.get_text(‘\n’)
- -》会把所有的tag标签前后都换行
- 导致<i>Riff Raff Sails the High Cheese</i>,也会变成单独的一行
- 不是我们希望看到的
所以算了,还是用之前的办法吧。
【后记2】
后来注意到此处有警告:
<ScholasticStorybook>:23: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 23 of the file <ScholasticStorybook>. To get rid of this warning, pass the additional argument 'features="lxml"' to the BeautifulSoup constructor.所以参考:
指定解析器为lxml:
soup = BeautifulSoup(htmlText, "lxml")
即可消除警告。
转载请注明:在路上 » 【已解决】PySpider中PyQuery中把得到的html的text转换为带换行的纯文本字符串