PySpider中,通过一个函数,实现了根据当前页面号码,递归获取下一个页面:
相关部分代码是:
<code>
# @every(minutes=24 * 60)
def on_start(self):
self.crawl(
'http://xxxa=audition&act_id=3',
callback=self.index_page)
# @config(age=10 * 24 * 60 * 60)
def index_page(self, response):
# <ul class="list-user list-user-1" id="list-user-1">
for each in response.doc('ul[id^="list-user"] li a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.showVideoCallback)
curPageNum = 1
self.getNextPageShowParentChild(response, curPageNum)
self.getNextPageShowFriend(response, curPageNum)
def getNextPageShowParentChild(self, response, curPageNum):
"""
for 亲子组: recursively get next page shows until fail
"""
# <ul class="list-user list-user-1" id="list-user-1">
self.getNextPageShow(response, curPageNum, 1)
def getNextPageShowFriend(self, response, curPageNum):
"""
for 好友组: recursively get next page shows until fail
"""
# <ul class="list-user list-user-2" id="list-user-2">
self.getNextPageShow(response, curPageNum, 2)
def getNextPageShow(self, response, curPageNum, order):
"""
recursively get next page shows until fail
"""
print("getNextPageShow: curPageNum=%s, order=%s" % (curPageNum, order))
getShowsUrl = "http://xxxc=match_new&a=get_shows"
headerDict = {
"Content-Type": "application/x-www-form-urlencoded"
}
dataDict = {
"counter": curPageNum,
"order": order,
"match_type": 2,
"match_name": "",
"act_id": 3
}
curPageDict = {
"curPageNum": curPageNum,
"order": order
}
self.crawl(
getShowsUrl,
method="POST",
headers=headerDict,
data=dataDict,
cookies=response.cookies,
callback=self.parseGetShowsCallback,
save=curPageDict
)
def parseGetShowsCallback(self, response):
print("parseGetShowsCallback: self=%s, response=%s"%(self, response))
respJson = response.json
prevPageDict = response.save
print("prevPageDict=%s, respJson=%s" % (prevPageDict, respJson))
if respJson["status"] == 1:
respData = respJson["data"]
# recursively try get next page shows
curPageNum = prevPageDict["curPageNum"] + 1
self.getNextPageShow(response, curPageNum, prevPageDict["order"])
for eachData in respData:
# print("type(eachData)=" % type(eachData))
showId = eachData["show_id"]
href = eachData["href"]
fullUrl = QupeiyinUrlRoot + href
print("[%s] fullUrl=%s" % (showId, fullUrl))
curShowInfoDict = eachData
self.crawl(
fullUrl,
callback=self.showVideoCallback,
save=curShowInfoDict)
else:
print("!!! Fail to get shows json from %s" % response.url)
</code>但是后来发现:
getNextPageShow
parseGetShowsCallback
在调试期间可以继续执行到:
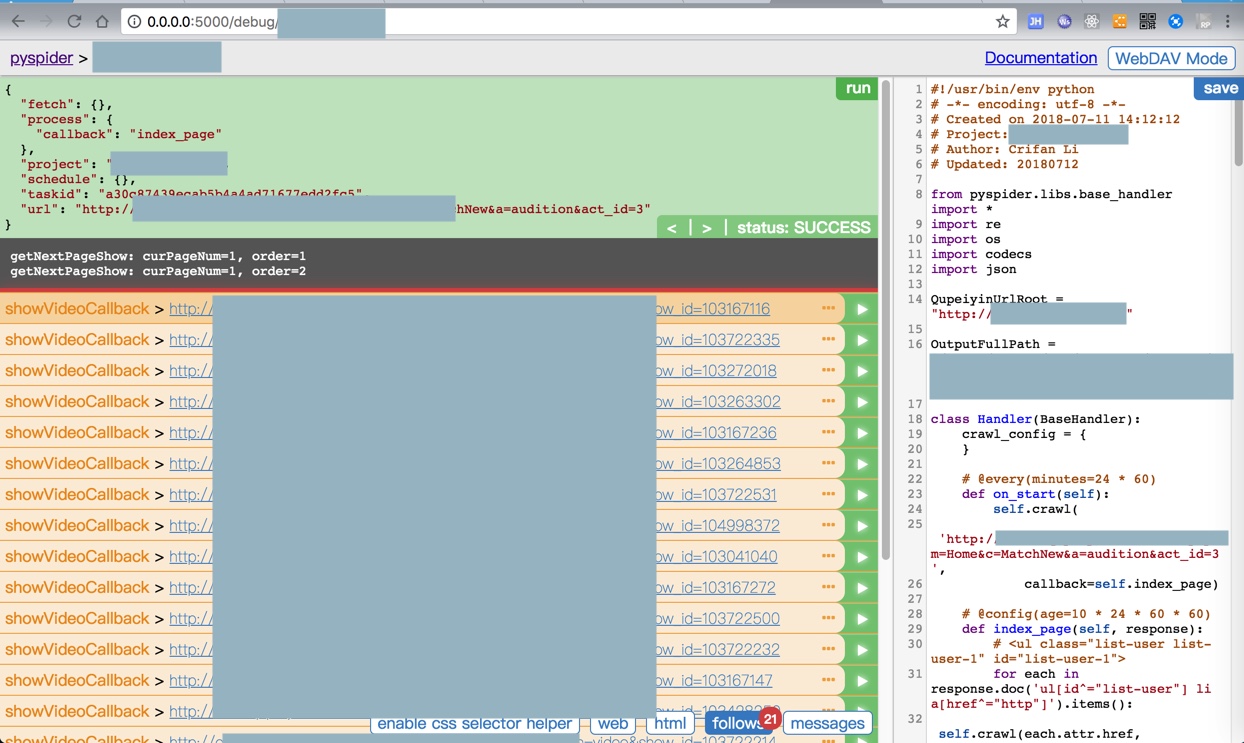
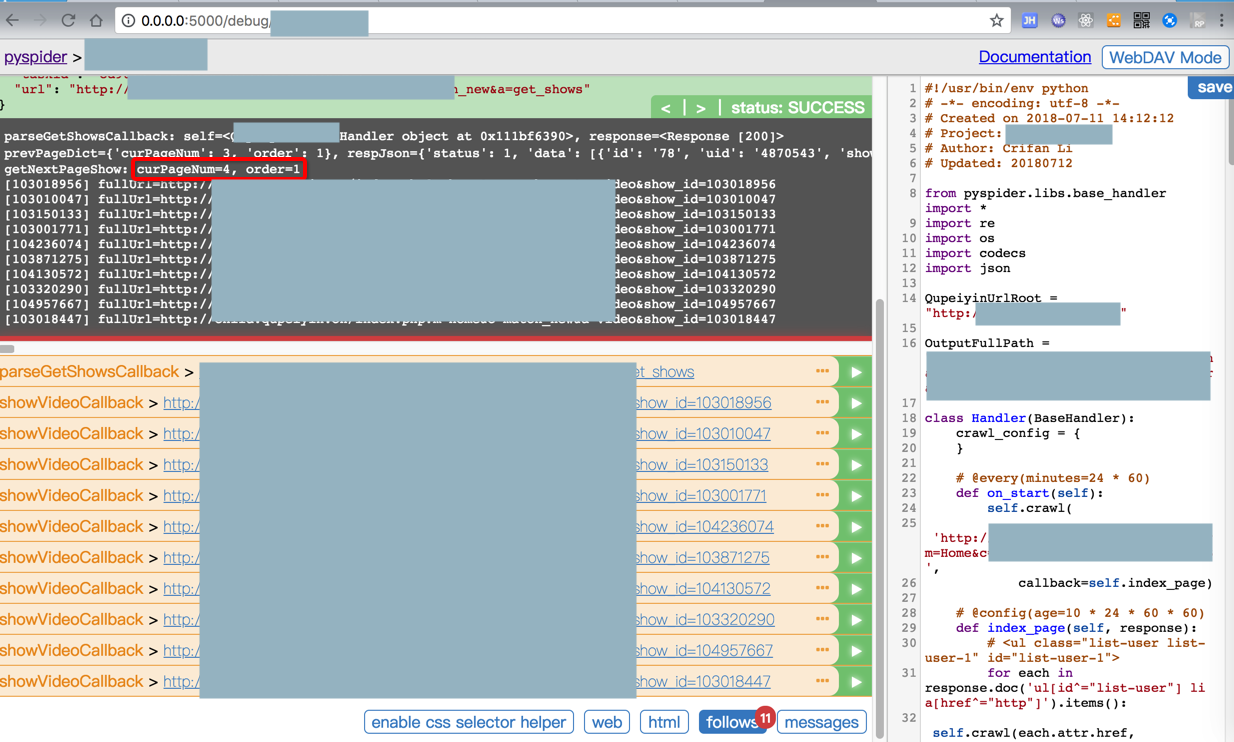
但是RUN运行时,就无法执行到了
最终只保存出2页的60个result:
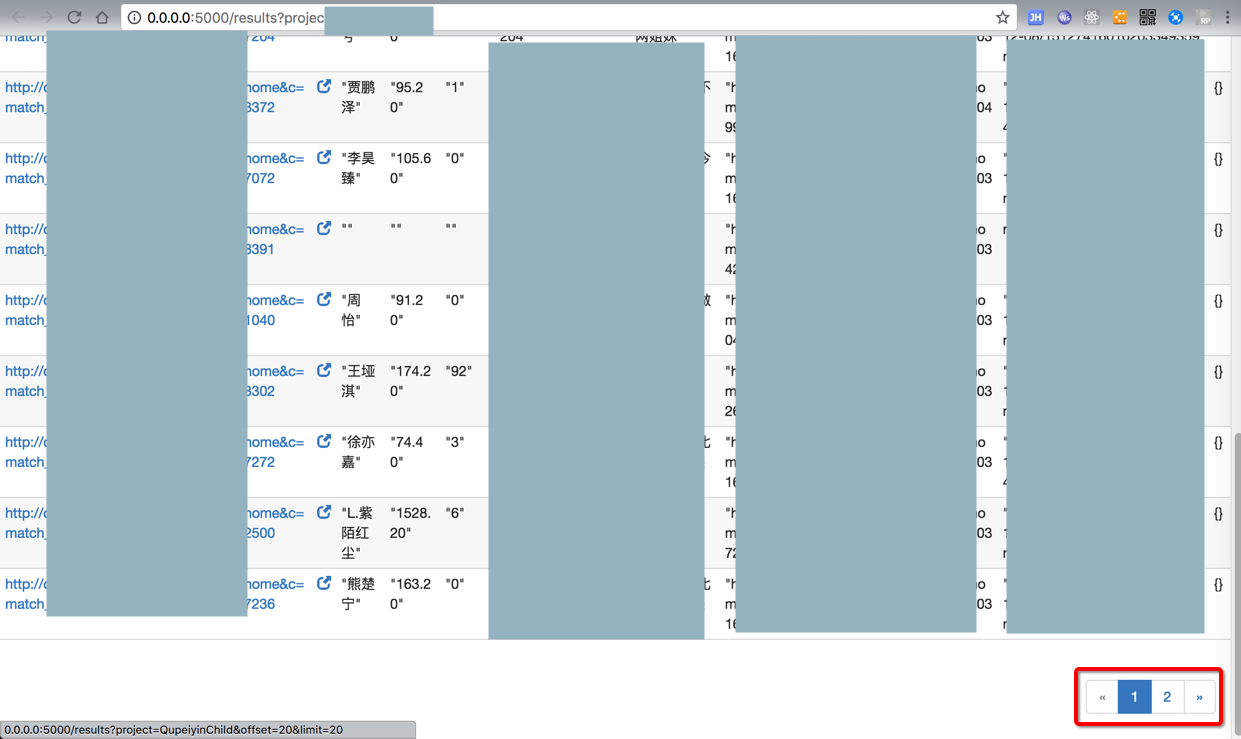
而实际上希望是,几十几百个才对。
然后也去注释掉了:
<code># @every(minutes=24 * 60) # @config(age=10 * 24 * 60 * 60) </code>
也还是无法执行到。
然后才想到,估计是代码中此处是递归调用,函数和url没有变化:
getNextPageShow
中的:
http:/xxxc=match_new&a=get_shows
始终是一样的,虽然调用时POST参数不同
估计就是这个原因导致无法继续运行的。
所以要去想办法强制执行
pyspider 函数 不继续执行
pyspider 重复不继续执行
Pyspider 函数不执行 – 足兆叉虫的回答 – SegmentFault 思否
pyspider run状态下result没有数据,而且没有继续向下执行,为什么? – 足兆叉虫的回答 – SegmentFault 思否
那么抽空去加上随机的hash试试
关于重复爬取出现问题 · Issue #598 · binux/pyspider
找官网文档看看是否有关重复url的强制执行的设置
self.crawl – pyspider中文文档 – pyspider中文网
“age
本参数用来指定任务的有效期,在有效期内不会重复抓取.默认值是-1(永远不过期,意思是只抓一次)”
或许可以设置极低的age实现继续重复抓取?
“itag
任务标记值,此标记会在抓取时对比,如果这个值发生改变,不管有效期有没有到都会重新抓取新内容.多数用来动态判断内容是否修改或强制重爬.默认值是:None.”
貌似用itag实现强制重复抓取。
<code>
def getNextPageShow(self, response, curPageNum, order):
"""
recursively get next page shows until fail
"""
print("getNextPageShow: curPageNum=%s, order=%s" % (curPageNum, order))
getShowsUrl = "http://xxxmatch_new&a=get_shows"
headerDict = {
"Content-Type": "application/x-www-form-urlencoded"
}
dataDict = {
"counter": curPageNum,
"order": order,
"match_type": 2,
"match_name": "",
"act_id": 3
}
curPageDict = {
"curPageNum": curPageNum,
"order": order
}
fakeItagForceRecrawl = "%s_%s" % (curPageNum, order)
self.crawl(
getShowsUrl,
itag=fakeItagForceRecrawl, # To force re-crawl for next page
method="POST",
headers=headerDict,
data=dataDict,
cookies=response.cookies,
callback=self.parseGetShowsCallback,
save=curPageDict
)
</code>试试效果
调试期间,可以看到itag值是每次都不同了:
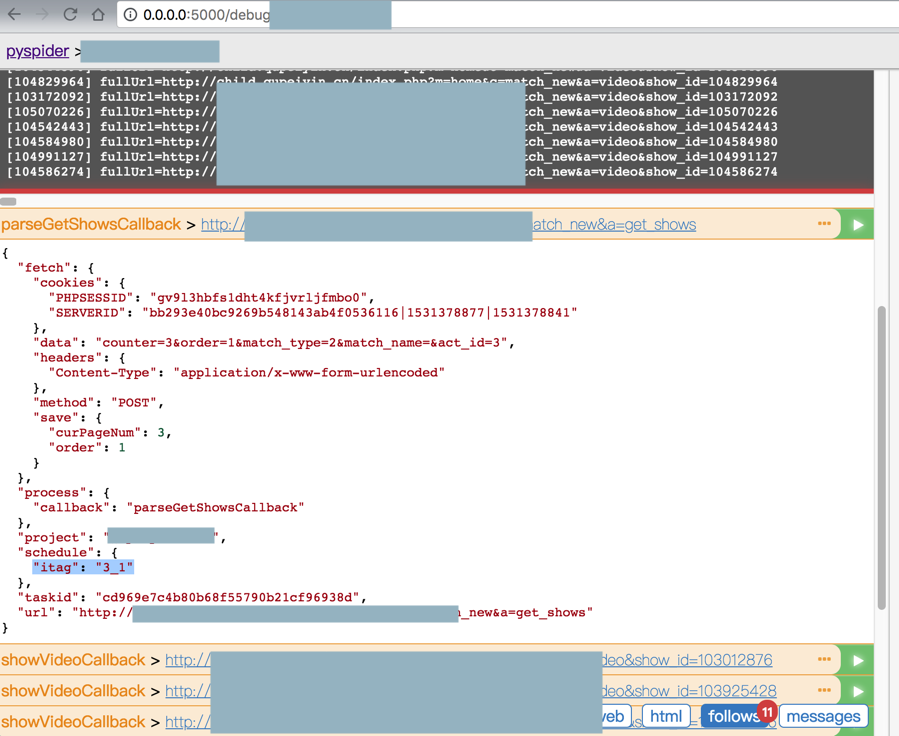
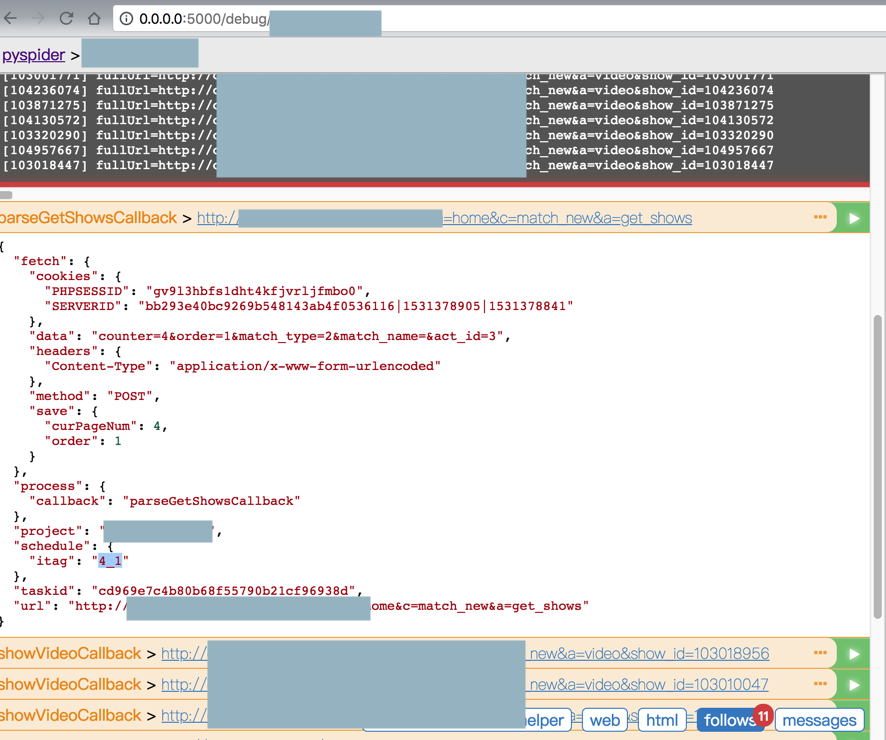
还是60个结果,没反应啊
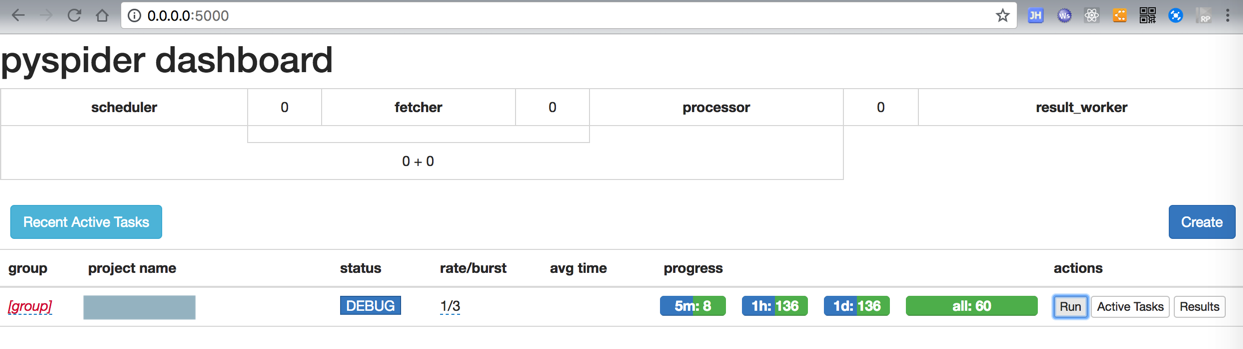
算了,清空之前数据,重新运行试试
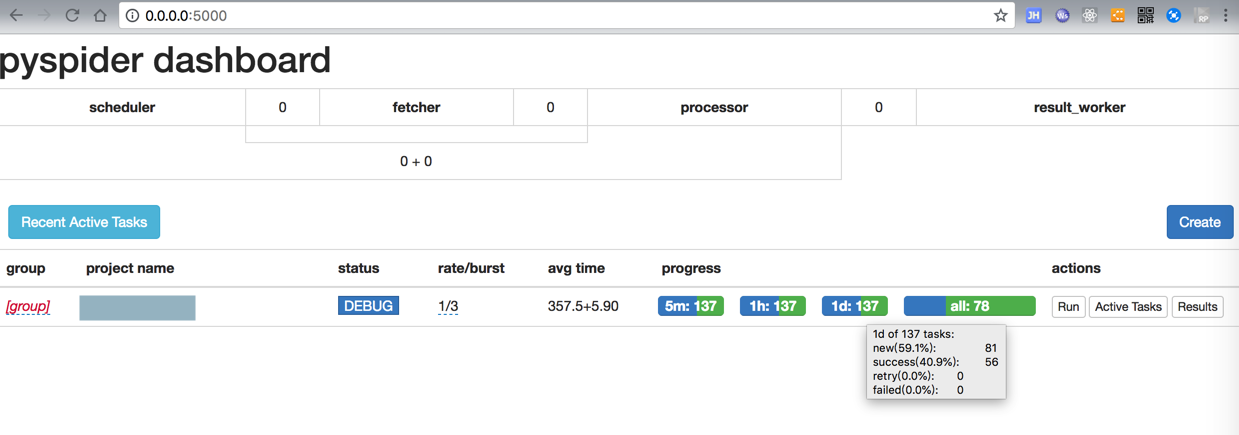
貌似可以了,至少超过60个了,就是等待继续爬取了:
【总结】
PySpider中,如果后续要爬取crawl的url,有重复,默认是不会重新爬取的。
想要强制重新爬取的话,做法有:
给URL后面加上无关紧要的hash值,比如:
http://xxx?m=home&c=match_new&a=get_shows#123
http://xxx?m=home&c=match_new&a=get_shows#456
当然hash值的选取,也可以选取时间戳(带毫秒的,不容易重复)
设置itag值
默认为None,所以默认不强制抓取
每次设置不同itag值,比如此处每次调用
getNextPageShow,要爬取的url是:
http://xxx?m=home&c=match_new&a=get_shows
设置itag可以选择:random的值,或者此处和实际逻辑有关系的,比如此处的每次爬取的页面数curPageNum和order值,则使用:2_1,3_1,4_1等等
参考代码:
<code>
def getNextPageShow(self, response, curPageNum, order):
"""
recursively get next page shows until fail
"""
print("getNextPageShow: curPageNum=%s, order=%s" % (curPageNum, order))
getShowsUrl = "http://xxxmatch_new&a=get_shows"
...
fakeItagForceRecrawl = "%s_%s" % (curPageNum, order)
self.crawl(
getShowsUrl,
itag=fakeItagForceRecrawl, # To force re-crawl for next page
method="POST",
headers=headerDict,
data=dataDict,
cookies=response.cookies,
callback=self.parseGetShowsCallback,
save=curPageDict
)
</code>【后记】
但是结果也不错,只有137个结果:
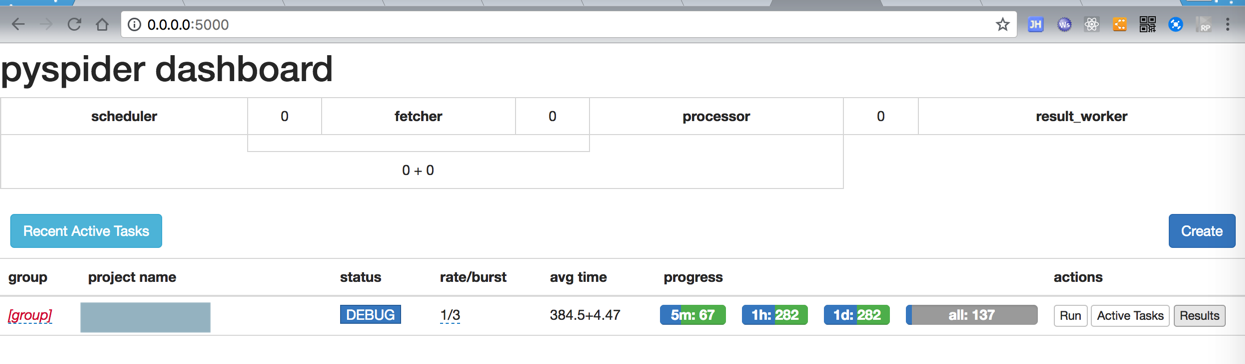
应该是好几百,上千个才对
pyspider 重复 不爬取
算了,去加上#hash值试试
<code>from datetime import datetime,timedelta
import time
timestampStr = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
fakeItagForceRecrawl = "%s_%s_%s" % (timestampStr, curPageNum, order)
getShowsUrlWithHash = getShowsUrl + "#" + timestampStr
self.crawl(
getShowsUrlWithHash,
itag=fakeItagForceRecrawl, # To force re-crawl for next page
method="POST",
headers=headerDict,
data=dataDict,
cookies=response.cookies,
callback=self.parseGetShowsCallback,
save=curPageDict
)
</code>既把itag更加复杂,不会重复了,又加了hash了。
看看结果:
调试时可以看到itag不同:
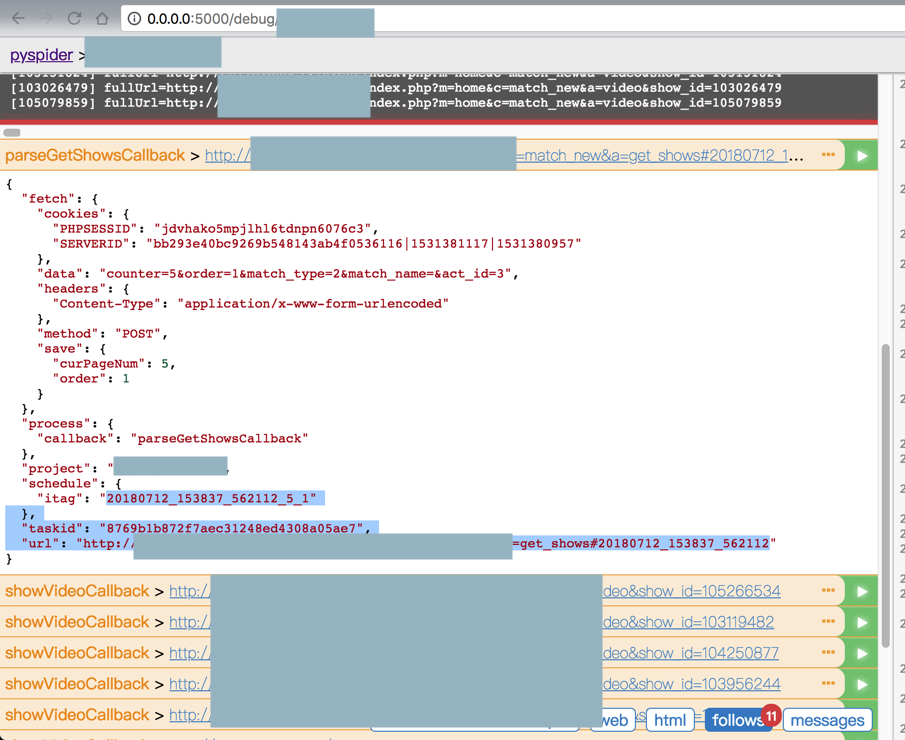
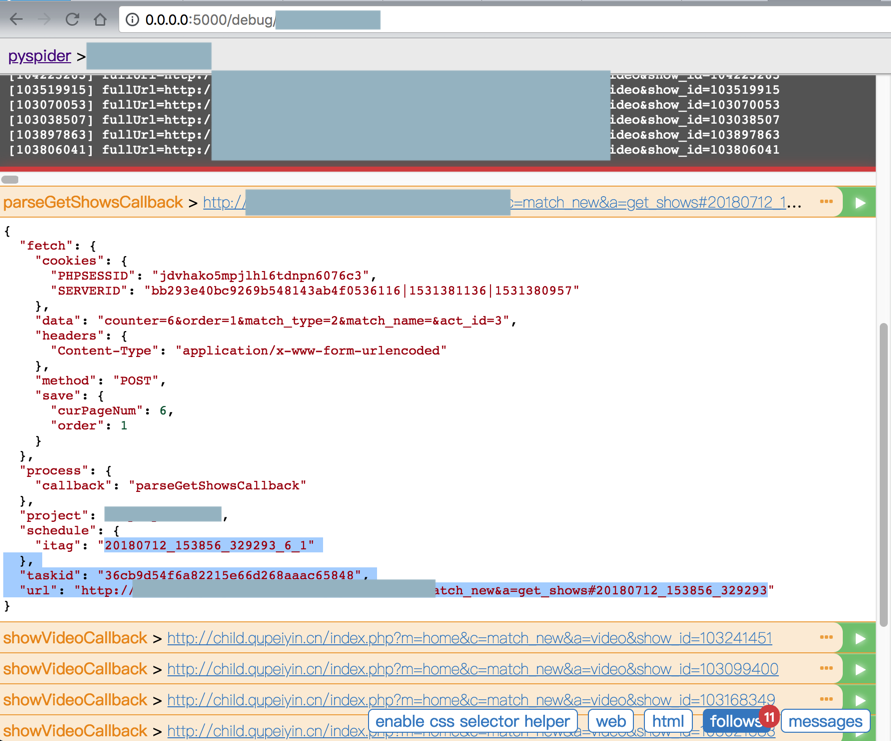
<code> "project": "xxx",
"schedule": {
"itag": "20180712_153856_329293_6_1"
},
"taskid": "36cb9d54f6a82215e66d268aaac65848",
"url": "http://xxxa=get_shows#20180712_153856_329293"
}
</code>然后重新清空项目数据,重新运行,看看是否能强制执行所有的代码
首次执行,就对了,生成2个url:
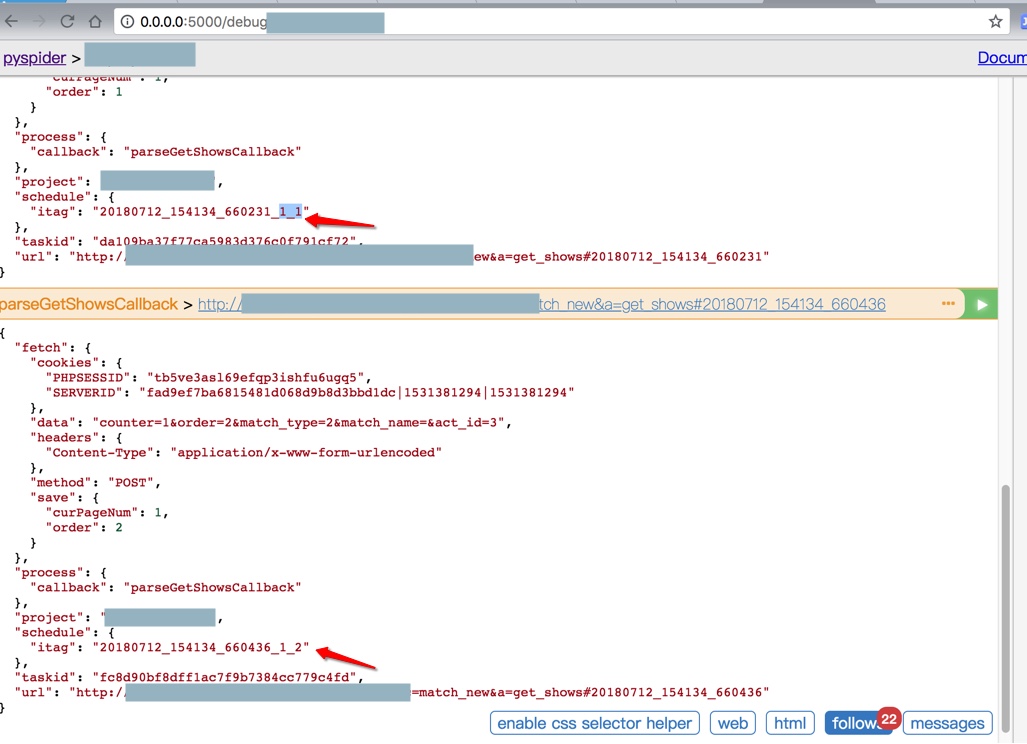
<code> "project": "xx",
"schedule": {
"itag": "20180712_154134_660231_1_1"
},
"taskid": "da109ba37f77ca5983d376c0f791cf72",
"url": "http://xxxa=get_shows#20180712_154134_660231"
}
"project": "xx",
"schedule": {
"itag": "20180712_154134_660436_1_2"
},
"taskid": "fc8d90bf8dff1ac7f9b7384cc779c4fd",
"url": "http://xxxa=get_shows#20180712_154134_660436"
}
</code>然后后续再去调试看看
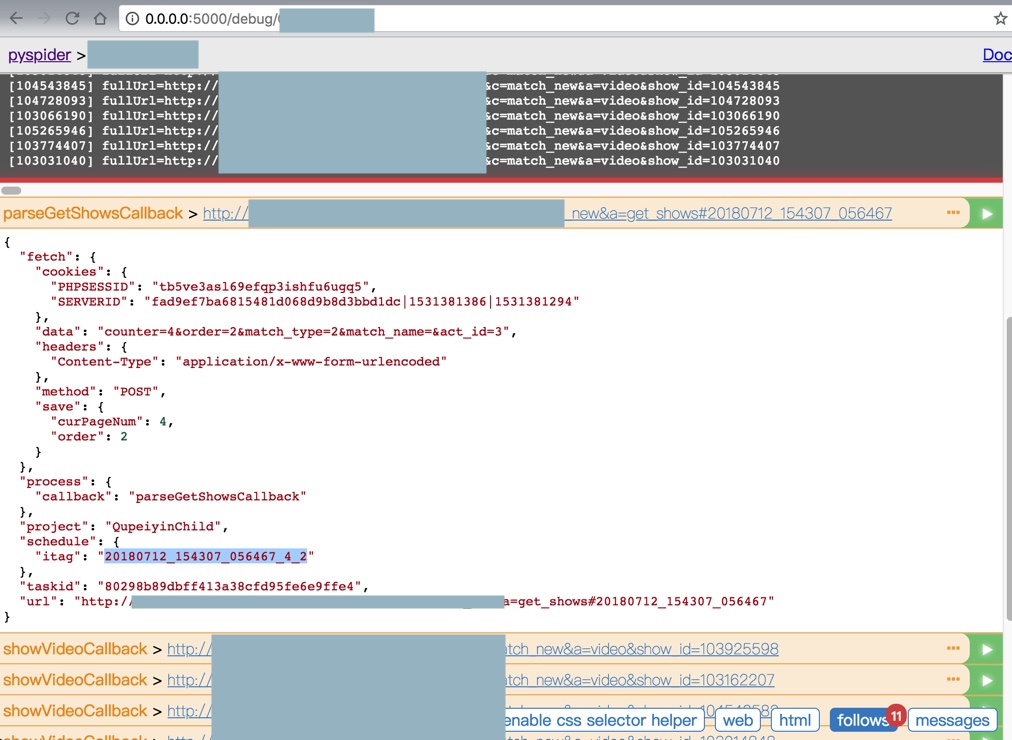
调试看起来都是对的。
再去DEBUG或RUN看看结果:
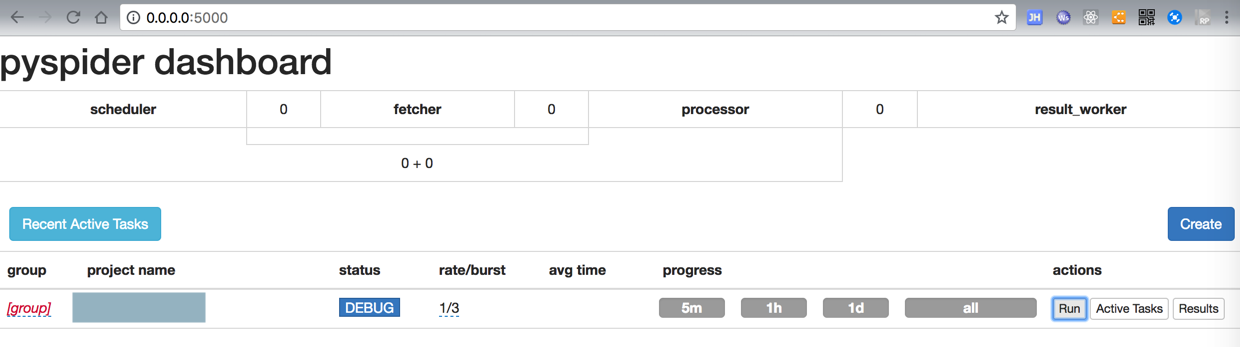
目前有1000多个了,这才是对的:
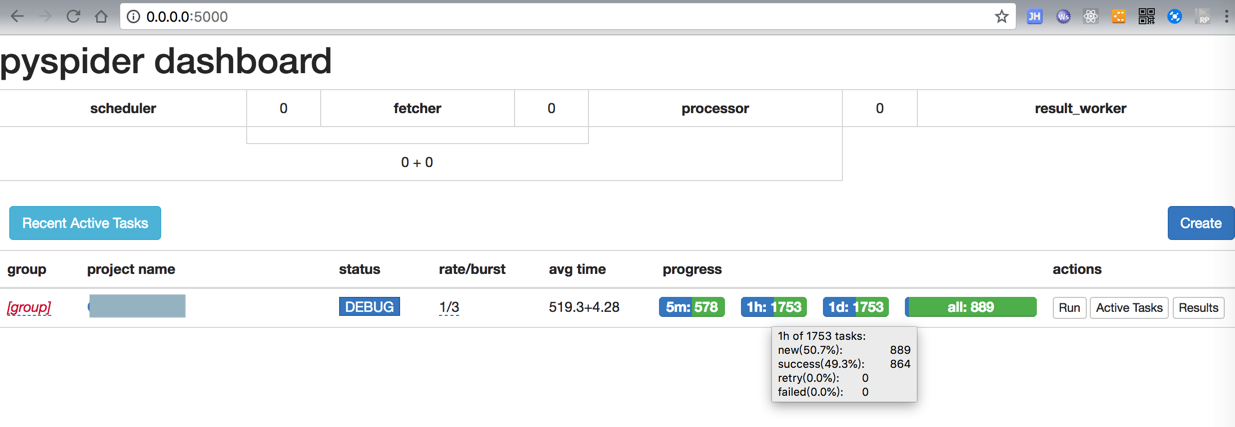
目前结果也有了24页了:
是正常的。
【总结2】
此处,不仅要加上itag值,也要加上#hash值:
<code>
from pyspider.libs.base_handler import *
import re
import os
import codecs
import json
from datetime import datetime,timedelta
import time
QupeiyinUrlRoot = "http://xxx"
OutputFullPath = "/Users/crifan/dev/dev_root/xxx/output"
class Handler(BaseHandler):
crawl_config = {
}
# @every(minutes=24 * 60)
def on_start(self):
self.crawl(
'http://xxxaudition&act_id=3',
callback=self.index_page)
# @config(age=10 * 24 * 60 * 60)
def index_page(self, response):
# <ul class="list-user list-user-1" id="list-user-1">
for each in response.doc('ul[id^="list-user"] li a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.showVideoCallback)
curPageNum = 1
self.getNextPageShowParentChild(response, curPageNum)
self.getNextPageShowFriend(response, curPageNum)
def getNextPageShowParentChild(self, response, curPageNum):
"""
for 亲子组: recursively get next page shows until fail
"""
# <ul class="list-user list-user-1" id="list-user-1">
self.getNextPageShow(response, curPageNum, 1)
def getNextPageShowFriend(self, response, curPageNum):
"""
for 好友组: recursively get next page shows until fail
"""
# <ul class="list-user list-user-2" id="list-user-2">
self.getNextPageShow(response, curPageNum, 2)
def getNextPageShow(self, response, curPageNum, order):
"""
recursively get next page shows until fail
"""
print("getNextPageShow: curPageNum=%s, order=%s" % (curPageNum, order))
getShowsUrl = "http://xxxa=get_shows"
headerDict = {
"Content-Type": "application/x-www-form-urlencoded"
}
dataDict = {
"counter": curPageNum,
"order": order,
"match_type": 2,
"match_name": "",
"act_id": 3
}
curPageDict = {
"curPageNum": curPageNum,
"order": order
}
timestampStr = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
fakeItagForceRecrawl = "%s_%s_%s" % (timestampStr, curPageNum, order)
getShowsUrlWithHash = getShowsUrl + "#" + timestampStr
self.crawl(
getShowsUrlWithHash,
itag=fakeItagForceRecrawl, # To force re-crawl for next page
method="POST",
headers=headerDict,
data=dataDict,
cookies=response.cookies,
callback=self.parseGetShowsCallback,
save=curPageDict
)
</code>才可以,实现url不重复,使得实现强制重新抓取的效果。
itag值和带hash的url是这种:
<code> "project": "xxx",
"schedule": {
"itag": "20180712_154134_660436_1_2"
},
"taskid": "fc8d90bf8dff1ac7f9b7384cc779c4fd",
"url": "http://xxxget_shows#20180712_154134_660436"
}
</code>转载请注明:在路上 » 【已解决】PySpider中如何强制让重复的url地址继续爬取