折腾:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
期间,已经可以用scrapy去post某个url得到返回的部分的html的字符串了:
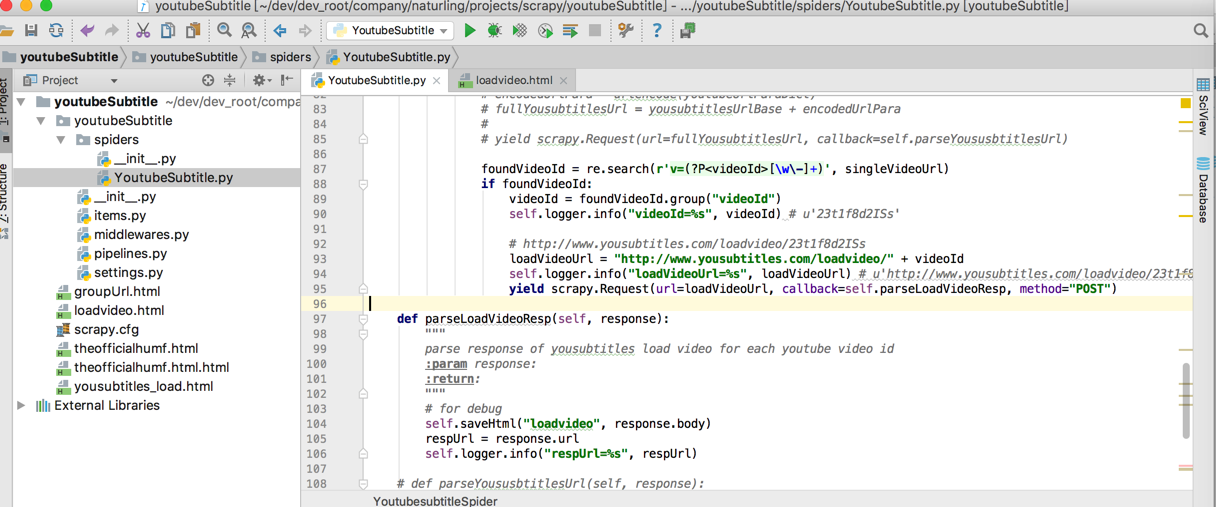
{“id”:1637788,”title”:”Humf – 23 Humf Bakes Biscuits (full episode)”,”links”:”<h4>Subtitles in .srt format:<\/h4>\n<p><a href=\”\/download\/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fasr_langs%3Dja%252Cnl%252Ces%252Cfr%252Cit%252Cde%252Cpt%252Cru%252Cko%252Cen%26caps%3Dasr%26key%3Dyttt1%26expire%3D1520243523%26v%3DUhO0bkdC4pQ%26hl%3Den_US%26signature%3D083C0E258E65F4026AAADB8F0B7F810E2E90417B.AE7CBDBDBDA8501C0964F60606F41B48936D1430%26xorp%3DTrue%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cxorp%252Cexpire%26kind%3Dasr%26lang%3Den&title=Humf+-+23+Humf+Bakes+Biscuits+%28full+episode%29\”><b>Download<\/b><\/a> English (auto-generated)<br\/><\/p>\n<br\/><h4>Translated Subtitles:<\/h4>\n<p><a href=\”\/download\/?url=http%3A%2F%2Fwww.youtube
…
o\”><\/a> <a href=\”http:\/\/www.playlist-to-mp3.com\/?youtube=UhO0bkdC4pQ\” target=\”_blank\”><input type=\”button\” value=\”Download Audio\”><\/a>”}
然后需要想办法去解析json中links的内容
属于html的编码后的内容,部分的html的内容
需要解码后,再去想办法转换为html,然后才能方便的提取其中的所需要的内容
之前印象中可以用到beautifulsoup去实现格式化html,包裹成完整的html,然后再去用bs去解析html,提取所需内容的。
python parse part html
python 解析部分html
crifan python 解析部分html
【教程】Python中第三方的用于解析HTML的库:BeautifulSoup – 在路上
【总结】Python的第三方库BeautifulSoup的使用心得 – 在路上
【整理】关于Python中的html处理库函数BeautifulSoup使用注意事项 – 在路上
crifan python 不完整html
python parse partial html
算了,继续去试试bs,尤其是最新的bs4吧:
Beautiful Soup 4.2.0 文档 — Beautiful Soup 4.2.0 documentation
看了看自己现在的是
<code>➜ ~ python --version Python 2.7.13 </code>
然后去安装bs4:
<code>➜ ~ pip install beautifulsoup4 Collecting beautifulsoup4 Downloading beautifulsoup4-4.6.0-py2-none-any.whl (86kB) 100% |████████████████████████████████| 92kB 168kB/s Installing collected packages: beautifulsoup4 Successfully installed beautifulsoup4-4.6.0 </code>
然后去试试bs4
【已解决】Beautifulsoup 4中搜索html的p的value包含特定值和p中的a的href
然后就可以正常使用bs4去解析部分的html了。
【总结】
对于不是完整的html的值(根结点是html的,下面是body的那种):
<code><h4>Subtitles in .srt format:</h4> <p> <a href="/download/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fsignature%3D28DC9DEF32E87382F97D0A1EA5C18C598FBBF791.5BE63BA820226EC354042E43654F6F35308A1D49%26hl%3Den_US%26expire%3D1520328653%26caps%3Dasr%26v%3DUhO0bkdC4pQ%26asr_langs%3Dru%252Cko%252Cde%252Cpt%252Cja%252Cnl%252Cen%252Cit%252Ces%252Cfr%26key%3Dyttt1%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cexpire%26kind%3Dasr%26lang%3Den&title=Humf+-+23+Humf+Bakes+Biscuits+%28full+episode%29"> <b>Download</b> </a>&nbsp;&nbsp;English (auto-generated) <br/> </p> <br/> <h4>Translated Subtitles:</h4> <p> <a href="/download/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fsignature%3D28DC9DEF32E87382F97D0A1EA5C18C598FBBF791.5BE63BA820226EC354042E43654F6F35308A1D49%26hl%3Den_US%26expire%3D1520328653%26caps%3Dasr%26v%3DUhO0bkdC4pQ%26asr_langs%3Dru%252Cko%252Cde%252Cpt%252Cja%252Cnl%252Cen%252Cit%252Ces%252Cfr%26key%3Dyttt1%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cexpire%26kind%3Dasr%26lang%3Den%26tlang%3Daf&title=Humf+-+23+Humf+Bakes+Biscuits+%28full+episode%29"> <b>Download</b> </a>&nbsp;&nbsp;Afrikaans <br/> </p> ... </code>
则也是可以直接使用bs4去解析的。
写法举例:
<code>decodedLinksDict = json.loads(response.body)
self.logger.info("decodedLinksDict=%s", decodedLinksDict)
linksHtml = decodedLinksDict["links"]
# self.logger.info("linksHtml=%s", linksHtml)
linksSoup = BeautifulSoup(linksHtml)
englishNode = linksSoup.find(lambda tag : tag.name == "p" and "English" in tag.get_text())
if englishNode:
# self.logger.info("englishNode.contents=%s", englishNode.contents)
self.logger.info("englishNode.text=%s", englishNode.text)
# self.logger.info("englishNode=%s", englishNode)
downloadHref = englishNode.a["href"]
self.logger.info("downloadHref=%s", downloadHref) # /download/?url=….&title=Humf+-+Compilation+%28episodes+16+to+22%29
downloadUrl = "http://www.yousubtitles.com" + downloadHref # http://www.yousubtitles.com/download/?url=http%3A%2F%2F...n&title=Humf+-+Compilation+%28episodes+16+to+22%29
self.logger.info("downloadUrl=%s", downloadUrl)
</code>