折腾:
【已解决】Scrapy的Python中如何解析部分的html字符串并格式化为html网页源码
期间,
对于:
<code><h4>Subtitles in .srt format:</h4> <p> <a href="/download/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fsignature%3D28DC9DEF32E87382F97D0A1EA5C18C598FBBF791.5BE63BA820226EC354042E43654F6F35308A1D49%26hl%3Den_US%26expire%3D1520328653%26caps%3Dasr%26v%3DUhO0bkdC4pQ%26asr_langs%3Dru%252Cko%252Cde%252Cpt%252Cja%252Cnl%252Cen%252Cit%252Ces%252Cfr%26key%3Dyttt1%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cexpire%26kind%3Dasr%26lang%3Den&title=Humf+-+23+Humf+Bakes+Biscuits+%28full+episode%29"> <b>Download</b> </a>&nbsp;&nbsp;English (auto-generated) <br/> </p> <br/> <h4>Translated Subtitles:</h4> <p> <a href="/download/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fsignature%3D28DC9DEF32E87382F97D0A1EA5C18C598FBBF791.5BE63BA820226EC354042E43654F6F35308A1D49%26hl%3Den_US%26expire%3D1520328653%26caps%3Dasr%26v%3DUhO0bkdC4pQ%26asr_langs%3Dru%252Cko%252Cde%252Cpt%252Cja%252Cnl%252Cen%252Cit%252Ces%252Cfr%26key%3Dyttt1%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cexpire%26kind%3Dasr%26lang%3Den%26tlang%3Daf&title=Humf+-+23+Humf+Bakes+Biscuits+%28full+episode%29"> <b>Download</b> </a>&nbsp;&nbsp;Afrikaans <br/> </p> ... </code>
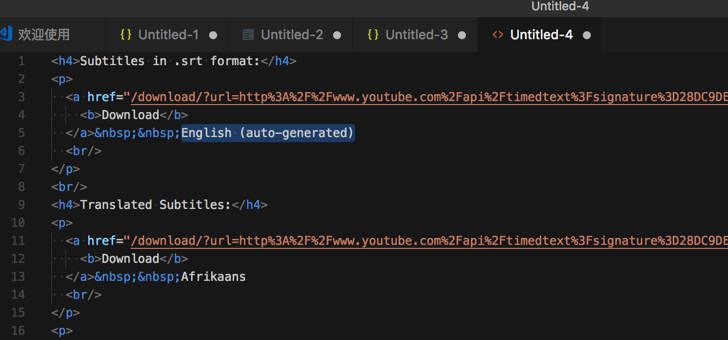
想要提取对应的
判断p下面的内容是English (auto-generated)
然后再去找p下面的a的href
参考:
Beautiful Soup 4.2.0 文档 — Beautiful Soup 4.2.0 documentation
结果用:
<code># englishNode = linksSoup.find("p", text=re.compile(r"English \(auto-generated\)"))
# englishNode = linksSoup.find("p", text=re.compile("English"))
# englishNode = linksSoup.find("p", text=re.compile("English \(auto\-generated\)"))
</code>都搜不到
去搜p:
<code>englishNode = linksSoup.find("p")
</code>搜到了,但是是:
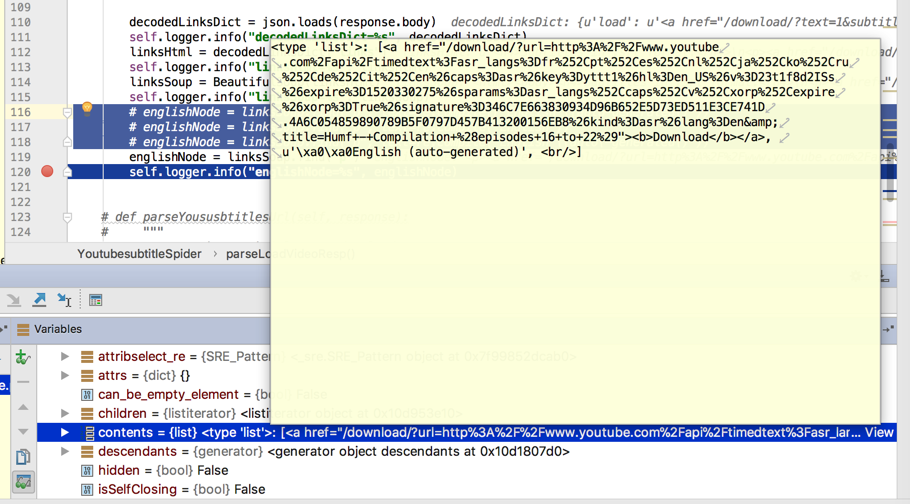
p下面变成list了,而不是嵌套的html的元素
正愁如何用soup去find这个p的[1]中才包含字符串呢
发现:
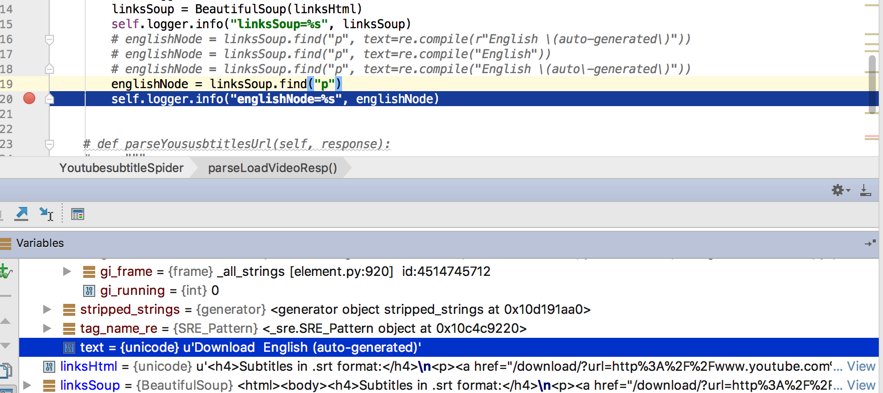
其实是text的值是:
u’Download English (auto-generated)’
所以应该还是可以去搜索的。
此处好像有点怪,已经调试发现:
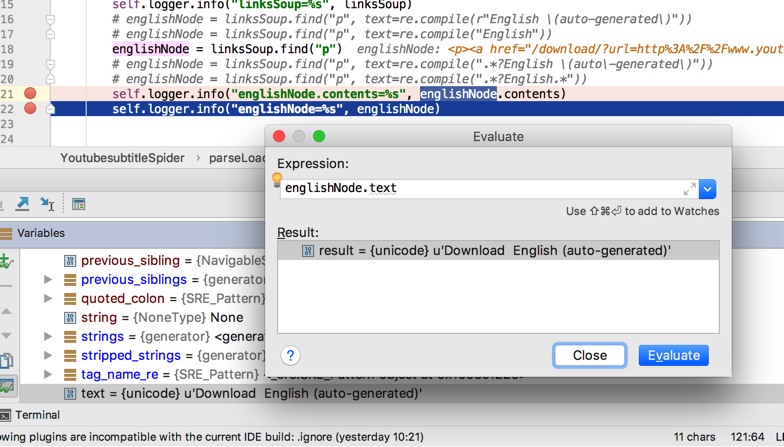
englishNode.text
是我们要的:u’Download English (auto-generated)’
但是为何:
# englishNode = linksSoup.find(“p”, text=re.compile(“.*?English.*”))
搜不到呢?
又试了试半天:
<code># englishNode = linksSoup.find("p", text=re.compile(r"English \(auto-generated\)"))
# englishNode = linksSoup.find("p", text=re.compile("English"))
# englishNode = linksSoup.find("p")
# englishNode = linksSoup.find("p", text=re.compile(".*?English \(auto\-generated\)"))
# englishNode = linksSoup.find("p", text=re.compile(".*?English.*"))
# englishNode = linksSoup.find("p", text=re.compile(r".*English.*"))
# englishNode = linksSoup.find("p", text="Download English (auto-generated)")
# englishNode = linksSoup.find_all("p", text=re.compile(r".*English.*"))
# englishNode = linksSoup.find("p", text=re.compile("^Download"))
englishNode = linksSoup.find("p", text=re.compile("^Download"))
self.logger.info("englishNode.contents=%s", englishNode.contents)
self.logger.info("englishNode.text=%s", englishNode.text)
self.logger.info("englishNode=%s", englishNode)
</code>还是不行。
bs4 re.compile not work
python – regex not working in bs4 – Stack Overflow
试试
果然是:
<code>englishNode = linksSoup.find(lambda tag : tag.name == "p" and "English" in tag.get_text()) </code>
找到了要的节点:
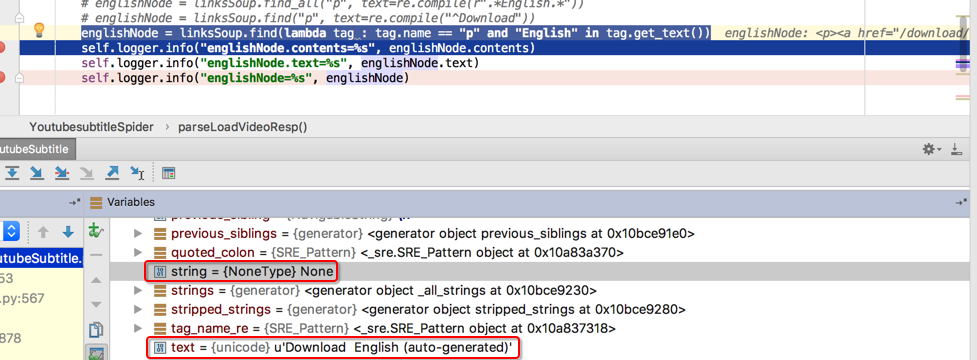
对应着:
此处p节点,有三个字元素:
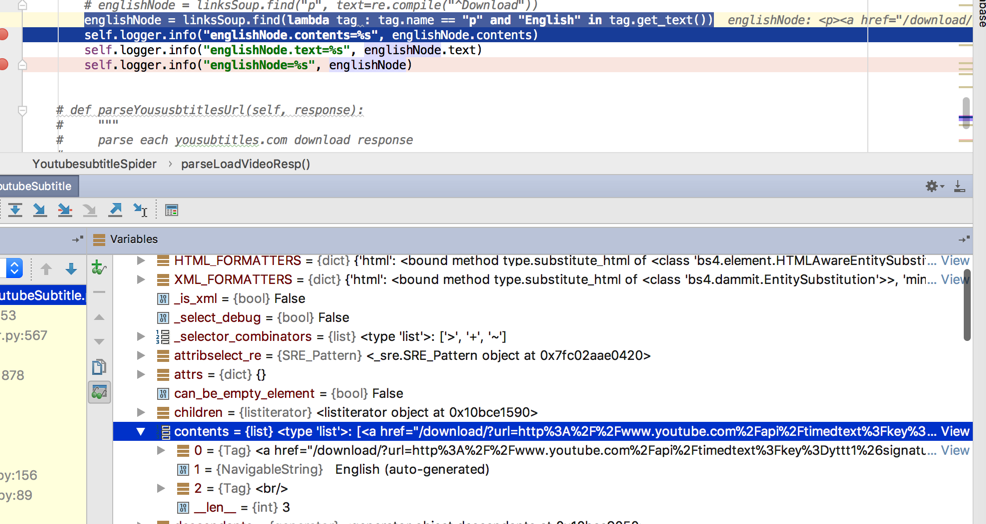
a
字符串
br
所以,此处的p的string是None
但是text是有值的
所以才能搜到要的值
【总结】
此处用bs4的re.compile:
<code>englishNode = linksSoup.find("p", text=re.compile(".*?English.*"))
</code>之所以找不到节点是因为:
bs4中,string的定义发生变化:
当节点中有多个子节点,比如此处的:
<code><p> <a href="/download/?url=http%3A%2F%2Fwww.youtube.com…..."> <b>Download</b> </a>&nbsp;&nbsp;English (auto-generated) <br/> </p> </code>
则对应的string是不知道具体指哪一个,所以默认为None
只有是单个节点,才有值。
所以此处是多个节点,用text=re.compile,内部是用string去搜索,所以搜不到。
办法是:
利用text
写法:
<code>englishNode = linksSoup.find(lambda tag : tag.name == "p" and "English" in tag.get_text()) </code>
就可以搜索到了。
转载请注明:在路上 » 【已解决】Beautifulsoup 4中搜索html的p的value包含特定值和p中的a的href