折腾:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
期间,对于scrapy的response的xpath得到的Selector,如何获取其中的a中href的值
Scrapy 1.5 documentation — Scrapy 1.5.0 documentation
选择器(Selectors) — Scrapy 1.0.5 文档
好像就是
定位到对应节点,extract即可?
通过继续在Scrapy shell中调试,找到了获取a的href值的方式了:
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]/@href’)[0]
<Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]/@href’ data=u’/watch?v=23t1f8d2ISs&list=PLHOR8x-IicVJD’>
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]/@href’)[0].extract()
u’/watch?v=23t1f8d2ISs&list=PLHOR8x-IicVJDAmJWZmJ-IMu1x3lTAld5′
继续去参考:
所以可以去写代码了:
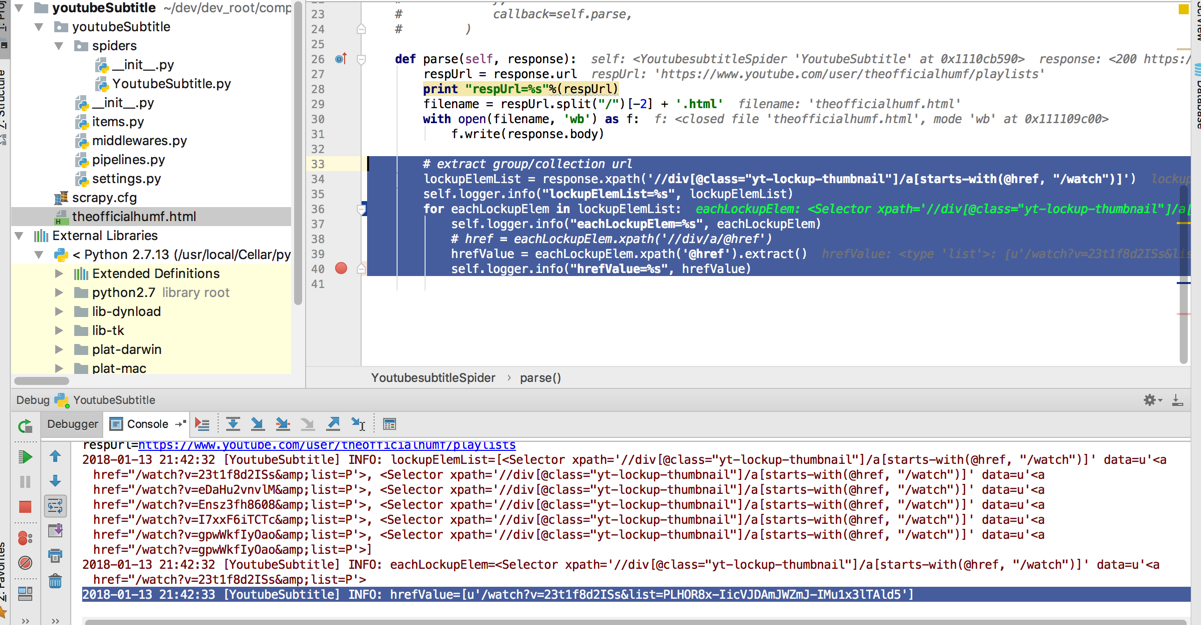
# extract group/collection url
lockupElemList = response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’)
self.logger.info(“lockupElemList=%s”, lockupElemList)
for eachLockupElem in lockupElemList:
self.logger.info(“eachLockupElem=%s”, eachLockupElem)
# href = eachLockupElem.xpath(‘//div/a/@href’)
hrefValue = eachLockupElem.xpath(‘@href’).extract()
self.logger.info(“hrefValue=%s”, hrefValue)
得到:
2018-01-13 21:42:33 [YoutubeSubtitle] INFO: hrefValue=[u’/watch?v=23t1f8d2ISs&list=PLHOR8x-IicVJDAmJWZmJ-IMu1x3lTAld5′]