【总结】
- 大数据概况
- 背景
- 普通文件系统
- 单机的
- 不能跨不同的机器
- 现状
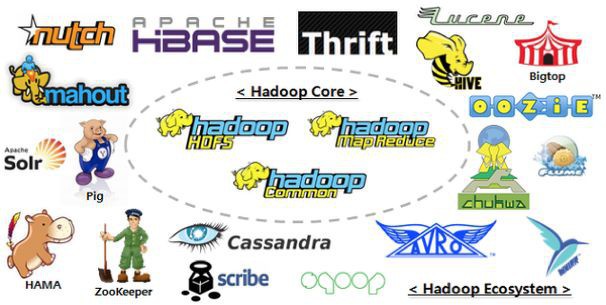
- Hadoop生态圈
- 别称:Hadoop泛生态圈
- 目的:处理超过单机尺度的数据处理
- 图解
- HDFS
- Hadoop Distributed FileSystem
- 目标:能存得下大量的数据
- 并管理好,处理好数据
- 目的:支持大量的数据能横跨成百上千台机器
- 效果:看到的是一个文件系统
- 而不是很多文件系统
- 举例
- 要获取/hdfs/tmp/file1的数据
- 引用的是一个文件路径
- 实际的数据存放在很多不同的机器上
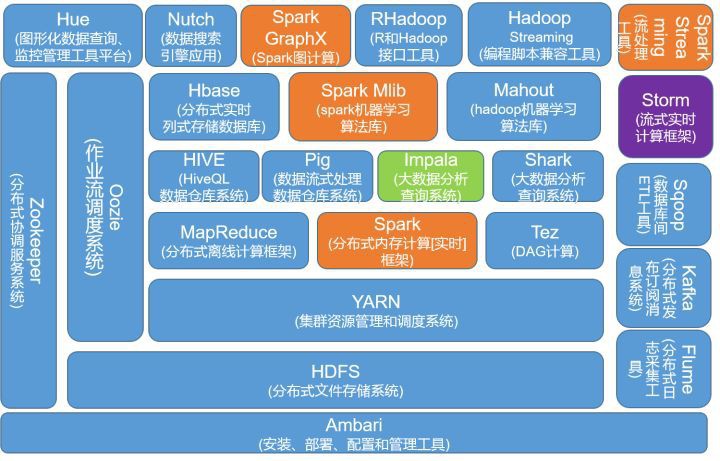
- 大数据发展历史
- 计算引擎:管理好大的数据
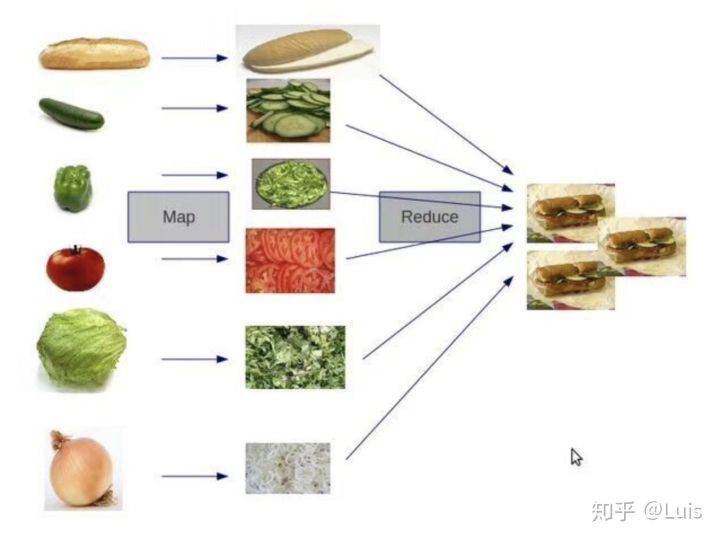
- 第一代:MapReduce
- 简化的计算模型
- 只有Map和Reduce两个计算过程
- 中间用Shuffle串联
- 图解
- 效果
- 可以处理大数据领域很大一部分问题
- 缺点
- 虽然好用,但很笨重
- 第二代:Tez和Spark
- 特点
- 支持内存Cache
- 目的
- 让Map/Reduce模型更通用,让Map和Reduce之间的界限更模糊
- 数据交换更灵活,更少的磁盘读写
- 更方便地描述复杂算法,取得更高的吞吐量
- 高层抽象:Pig和Hive
- 背景
- MapReduce就像汇编语言
- 虽然什么都能干,但是写起来复杂繁琐
- 所以需要更高层更抽象的语言层
- 描述算法和数据处理流程
- 出现Pig和Hive
- Pig和Hive
- 上层
- Pig
- 接近脚本方式去描述MapReduce
- Hive
- 用SQL去描述MapReduce
- 底层
- 把脚本和SQL语言翻译成MapReduce程序
- 丢给计算引擎去计算
- 效果
- 写起来方便多了
- 数据分析人员,不用去求软件工程师写Java
- 可以自己写SQL去数据统计了
- 举例
- 词频统计
- MapReduce:大约要几十上百行
- Hive的SQL:只有一两行
- 提升速度:Impala、Presto、Drill
- 背景:
- Hive在MapReduce上跑,非常慢
- 交互SQL引擎:Impala、Presto、Drill等
- 核心理念:
- MapReduce引擎太慢,因为它太通用,太强壮,太保守
- SQL需要更轻量,更激进地获取资源,更专门地对SQL做优化
- 不需要那么多容错性保证
- 因为系统出错了大不了重新启动任务,如果整个处理时间更短的话,比如几分钟之内
- 效果:
- 更快速地处理SQL任务
- 牺牲了通用性稳定性等特性
- 类比:
- MapReduce:大砍刀,啥都能砍
- Impala、Presto、Drill:3个剔骨刀,灵巧锋利
- 但是不能搞太大太硬的东西
- 其他异类:Hive on Tez / Spark、SparkSQL
- 背景
- Impala、Presto、Drill等,没有达到预期效果,不是很流行
- Hive on Tez / Spark和SparkSQL
- 设计理念
- MapReduce慢
- 我用新一代通用计算引擎Tez或者Spark来跑SQL,那我就能跑的更快
- 好处
- 不需要维护两套系统
- 效果
- 基本的数据仓库的构架
- 作用:中低速数据处理
- 举例
- 3层
- 再上面跑Hive,Pig
- 上面跑MapReduce/Tez/Spark
- 底层HDFS
- 2层
- 上面直接跑Impala,Drill,Presto
- 底层HDFS
- 更高速的处理
- 背景
- 前面系统和架构只能处理中低速度
- 针对高速处理:
- 出现新计算模型:Streaming(流)计算
- 最流行的流计算平台:Storm
- 流计算
- 思路
- 在数据流进来的时候就处理,达到更实时的更新
- 举例
- 词频统计
- 数据流是一个一个的词
- 让他们一边流过我就一边开始统计
- 特点
- 优点
- 实时计算,无延迟
- 缺点
- 不够灵活
- 想要统计的东西必须预先知道
- 毕竟数据流过就没了,你没算的东西就无法补算
- 结论
- 是个很好的东西
- 但是无法替代上面数据仓库和批处理系统
- 其他独立模块和细分领域
- KV Store=键值对
- 核心特点
- 给定key键,可以快速获取到value值
- 举例
- 用身份证号key,能取到你的身份数据value
- MapReduce:也能完成, 但是要扫描整个数据集,速度很慢
- KV Store对此操作的存和取都专门优化,速度很快
- 几个P的数据中查找一个身份证号,也许只要零点几秒
- 理念和特点
- 虽然
- 基本无法处理复杂的计算
- 大多没法JOIN
- 也许没法聚合
- 没有强一致性保证
- 不同数据分布在不同机器上,你每次读取也许会读到不同的结果,也无法处理类似银行转账那样的强一致性要求的操作
- 但是
- 速度就是快,非常快,极快
- 注:
- 每个不同的KV Store设计都有不同取舍
- 有些更快
- 有些容量更高
- 有些可以支持更复杂的操作
- 典型系统
- Cassandra
- HBase
- MongoDB
- 更特制的系统/组件
- 分布式机器学习库
- Mahout
- 数据交换的编码和库
- Protobuf
- 高一致性的分布存取协同系统
- ZooKeeper
转载请注明:在路上 » 【整理】大数据 相关术语概念