折腾:
【未解决】在线环境中用gunicorn部署的产品demo无法正常初始化运行
期间,基本上能运行产品demo的Flask的app了。
但是发现之前正常工作的ms的tts,获取token,从文字生成语音文件
现在返回401,无法正常工作了。
log中显示ms的tts的返回401,感觉是token失效了:
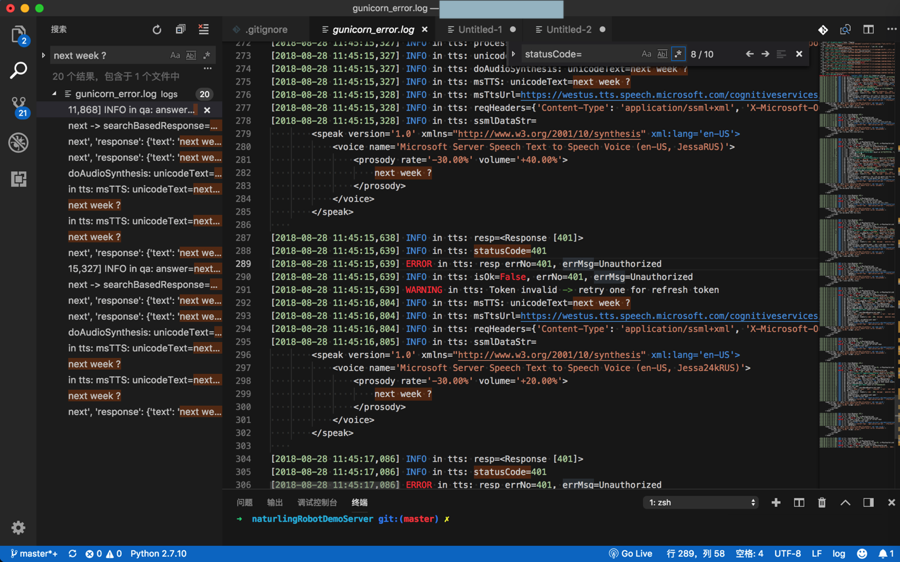
后来的类似的log:
<code>[2018-08-28 13:30:01,070 INFO tts.py:143 msTTS] msTtsUrl=https://westus.tts.speech.microsoft.com/cognitiveservices/v1
[2018-08-28 13:30:01,070 INFO tts.py:150 msTTS] reqHeaders={'Content-Type': 'application/ssml+xml', 'X-Microsoft-OutputFormat': 'audio-16khz-128kbitrate-mono-mp3', 'Ocp-Apim-Subscription-Key': 'df01e5864e934dafaa8469b4d7d1959f', 'Authorization': 'Bear { "statusCode": 403, "message": "Out of call volume quota. Quota will be replenished in 4.03:08:32." }'}
[2018-08-28 13:30:01,070 INFO tts.py:164 msTTS] ssmlDataStr=
<speak version='1.0' xmlns="http://www.w3.org/2001/10/synthesis" xml:lang='en-US'>
<voice name='Microsoft Server Speech Text to Speech Voice (en-US, Jessa24kRUS)'>
<prosody rate='-30.00%' volume='+20.00%'>
i can't wait to share this story with you.
</prosody>
</voice>
</speak>
[2018-08-28 13:30:01,628 INFO tts.py:166 msTTS] resp=<Response [401]>
[2018-08-28 13:30:01,628 INFO tts.py:169 msTTS] statusCode=401
[2018-08-28 13:30:01,628 ERROR tts.py:183 msTTS] resp errNo=401, errMsg=Unauthorized
[2018-08-28 13:30:01,628 INFO tts.py:350 doAudioSynthesis] after refresh token: isOk=Falses, errNo=401, errMsg=Unauthorized
[2018-08-28 13:30:01,628 INFO tts.py:355 doAudioSynthesis] return isOk=False, errMsg=Unauthorized
[2018-08-28 13:30:01,629 WARNING tts.py:416 processResponse] Fail to get synthesis audio for errMsg=Unauthorized
</code>需要去搞清楚原因。
不过先去重启Flask+gunicorn,看看是否还是同样现象
结果问题依旧。
然后看相关代码:
resources/tts.py
<code>gMsToken = ""
def msTTS(unicodeText,
voiceName=settings.MS_TTS_VOICE_NAME,
voiceRate=settings.MS_TTS_VOICE_RATE,
voiceVolume=settings.MS_TTS_VOICE_VOLUME):
"""call ms azure tts to generate audio(mp3/wav/...) from text"""
global gMsToken
# log = app.logger
log.info("msTTS: unicodeText=%s, gMsToken=%s", unicodeText, gMsToken)
isOk = False
audioBinData = None
errNo = 0
errMsg = "Unknown error"
msTtsUrl = settings.MS_TTS_URL
log.info("msTtsUrl=%s", msTtsUrl)
reqHeaders = {
"Content-Type": "application/ssml+xml",
"X-Microsoft-OutputFormat": settings.MS_TTS_OUTPUT_FORMAT,
"Ocp-Apim-Subscription-Key": settings.MS_TTS_SECRET_KEY,
"Authorization": "Bear " + gMsToken
}
log.info("reqHeaders=%s", reqHeaders)
# # for debug
# MS_TTS_VOICE_NAME = "zhang san"
ssmlDataStr = """
<speak version='1.0' xmlns="http://www.w3.org/2001/10/synthesis" xml:lang='en-US'>
<voice name='%s'>
<prosody rate='%s' volume='%s'>
%s
</prosody>
</voice>
</speak>
""" % (voiceName, voiceRate, voiceVolume, unicodeText)
log.info("ssmlDataStr=%s", ssmlDataStr)
resp = requests.post(msTtsUrl, headers=reqHeaders, data=ssmlDataStr)
log.info("resp=%s", resp)
statusCode = resp.status_code
log.info("statusCode=%s", statusCode)
if statusCode == 200:
# respContentType = resp.headers["Content-Type"] # 'audio/x-wav', 'audio/mpeg'
# log.info("respContentType=%s", respContentType)
# if re.match("audio/.*", respContentType):
audioBinData = resp.content
log.info("resp content is audio binary data, length=%d", len(audioBinData))
isOk = True
errMsg = ""
else:
isOk = False
errNo = resp.status_code
errMsg = resp.reason
log.error("resp errNo=%d, errMsg=%s", errNo, errMsg)
# errNo=400, errMsg=Voice zhang san not supported
# errNo=401, errMsg=Unauthorized
# errNo=413, errMsg=Content length exceeded the allowed limit of 1024 characters.
return isOk, audioBinData, errNo, errMsg
# def doAudioSynthesis(unicodeText):
def doAudioSynthesis(unicodeText,
voiceName=settings.MS_TTS_VOICE_NAME,
voiceRate=settings.MS_TTS_VOICE_RATE,
voiceVolume=settings.MS_TTS_VOICE_VOLUME):
"""
do audio synthesis from unicode text
if failed for token invalid/expired, will refresh token to do one more retry
"""
global gMsToken
# log = app.logger
isOk = False
audioBinData = None
errMsg = ""
# # for debug
# gCurBaiduRespDict["access_token"] = "99.569b3b5b470938a522ce60d2e2ea2506.2592000.1528015602.282335-11192483"
log.info("doAudioSynthesis: unicodeText=%s, voiceName=%s, voiceRate=%s, voiceVolume=%s",
unicodeText, voiceName, voiceRate, voiceVolume)
# isOk, audioBinData, errNo, errMsg = baiduText2Audio(unicodeText)
isOk, audioBinData, errNo, errMsg = msTTS(unicodeText, voiceName, voiceRate, voiceVolume)
log.info("isOk=%s, errNo=%d, errMsg=%s", isOk, errNo, errMsg)
if isOk:
errMsg = ""
log.info("got synthesized audio binary data length=%d", len(audioBinData))
else:
# if errNo == BAIDU_ERR_TOKEN_INVALID:
if errNo == settings.MS_ERR_UNAUTHORIZED:
log.warning("Token invalid -> retry one for refresh token")
# refreshBaiduToken()
log.info("before retry token: gMsToken=%s", gMsToken)
gMsToken = refreshAzureSpeechToken()
log.info("after retry token: gMsToken=%s", gMsToken)
# isOk, audioBinData, errNo, errMsg = baiduText2Audio(unicodeText)
isOk, audioBinData, errNo, errMsg = msTTS(unicodeText, voiceName, voiceRate, voiceVolume)
log.info("after refresh token: isOk=%ss, errNo=%s, errMsg=%s", isOk, errNo, errMsg)
else:
log.warning("try synthesized audio occur error: errNo=%d, errMsg=%s", errNo, errMsg)
audioBinData = None
log.info("return isOk=%s, errMsg=%s", isOk, errMsg)
if audioBinData:
log.info("audio binary bytes=%d", len(audioBinData))
return isOk, audioBinData, errMsg
</code>感觉是gMsToken没有生效?
或者是:
由于多线程,多进程,导致gMsToken被别的地方改掉了,从而此处使用的token还是旧的,或者被再次给更新掉,失效了。
后来才注意到是:
<code>[2018-08-28 13:30:12,505 INFO tts.py:150 msTTS] reqHeaders={'Content-Type': 'application/ssml+xml', 'X-Microsoft-OutputFormat': 'audio-16khz-128kbitrate-mono-mp3', 'Ocp-Apim-Subscription-Key': 'df01e5864e934dafaa8469b4d7d1959f', 'Authorization': 'Bear { "statusCode": 403, "message": "Out of call volume quota. Quota will be replenished in 4.04:43:06." }'}
</code>所以还是去搞清楚什么情况:
然后继续正常去试试在线环境,也是可以获取token的了
【总结】
此处最终证实,不是自己代码的问题,而是微软Azure的垃圾做法:
免费资源给你用,实际上虽然没有超过额度限制,但是却告诉你403 超额了
最后只能是从F0免费套餐,升级到S0收费套餐,才可以正常获取token。
详见:
另外,还要继续去优化全局变量的问题: