折腾:
期间,api接口试用成功后,需要把服务集成到Flask后台中。先去集成到本地Flask环境。
期间,明显还要增加后台服务,用已有的celery加上周期性task,去每隔不到10分钟,更新一次JWT的token。
参考:
The Speech Synthesis Markup Language – Microsoft Cognitive Services | Microsoft Docs
Speech service REST APIs | Microsoft Docs
Use Text to Speech using Speech services – Microsoft Cognitive Services | Microsoft Docs
【总结】
然后用代码:
<code>import requests
### TTS ###
TTS_AUDIO_SUFFIX = ".mp3"
# Use Text to Speech using Speech services - Microsoft Cognitive Services | Microsoft Docs
# https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/how-to-text-to-speech
MS_TTS_OUTPUT_FORMAT = "audio-16khz-128kbitrate-mono-mp3"
# MS_TTS_OUTPUT_FORMAT = "riff-24khz-16bit-mono-pcm"
# https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/supported-languages
# MS_TTS_SPEAKER = "Microsoft Server Speech Text to Speech Voice (en-US, ZiraRUS)"
# MS_TTS_SPEAKER = "Microsoft Server Speech Text to Speech Voice (en-US, JessaRUS)"
MS_TTS_SPEAKER = "Microsoft Server Speech Text to Speech Voice (en-US, Jessa24kRUS)"
MS_TTS_RATE = "-30.00%"
MS_TTS_VOLUME = "+20.00%"
# https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/how-to-text-to-speech
MS_ERR_BAD_REQUEST = 400
MS_ERR_UNAUTHORIZED = 401
MS_ERR_REQUEST_ENTITY_TOO_LARGE = 413
def initAudioSynthesis():
"""
init audio synthesis related:
init token
:return:
"""
createAudioTempFolder()
# getBaiduToken()
getMsToken()
refreshMsTokenPeriodic()
def getMsToken():
"""get ms azure token"""
refreshMsToken()
def refreshMsToken():
"""refresh microsoft azure token for later call tts api"""
global app, log, gMsToken
log.info("refreshMsToken: gMsToken=%s", gMsToken)
getMsTokenUrl = app.config["MS_GET_TOKEN_URL"]
reqHeaders = {"Ocp-Apim-Subscription-Key": app.config["MS_TTS_SECRET_KEY"]}
log.info("getMsTokenUrl=%s, reqHeaders=%s", getMsTokenUrl, reqHeaders)
resp = requests.post(getMsTokenUrl, headers=reqHeaders)
log.info("resp=%s", resp)
respTokenText = resp.text # eyxxxxiJ9.xxx.xxx
log.info("respTokenText=%s", respTokenText)
gMsToken = respTokenText
# # for debug
# gMsToken = "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJ1cm46bXMuY29nbml0aXZlc2VydmljZXMiLCJleHAiOiIxNTI3MDU5MTYxIiwicmVnaW9uIjoid2VzdHVzIiwic3Vic2NyaXB0aW9uLWlkIjoiOWQ0MmQ1N2I3YTQ1NDVjOThhZDE0ZDdjOWRhYWNjNjIiLCJwcm9kdWN0LWlkIjoiU3BlZWNoU2VydmljZXMuRnJlZSIsImNvZ25pdGl2ZS1zZXJ2aWNlcy1lbmRwb2ludCI6Imh0dHBzOi8vYXBpLmNvZ25pdGl2ZS5taWNyb3NvZnQuY29tL2ludGVybmFsL3YxLjAvIiwiYXp1cmUtcmVzb3VyY2UtaWQiOiIiLCJzY29wZSI6InNwZWVjaHNlcnZpY2VzIiwiYXVkIjoidXJuOm1zLnNwZWVjaHNlcnZpY2VzLndlc3R1cyJ9.B8_QoDtUtfsQs6OlKXG6p5SC4mm8s0nISdiUyr4Fnez"
log.info("gMsToken=%s", gMsToken)
def refreshMsTokenPeriodic():
"""periodically refresh ms token"""
# TODO: add celery periodic task to refresh ms token
log.info("refreshMsTokenPeriodic")
refreshMsToken()
def msTTS(unicodeText):
"""call ms azure tts to generate audio(mp3/wav/...) from text"""
global app, log, gMsToken
log.info("msTTS: unicodeText=%s", unicodeText)
isOk = False
audioBinData = None
errNo = 0
errMsg = "Unknown error"
msTtsUrl = app.config["MS_TTS_URL"]
log.info("msTtsUrl=%s", msTtsUrl)
reqHeaders = {
"Content-Type": "application/ssml+xml",
"X-Microsoft-OutputFormat": MS_TTS_OUTPUT_FORMAT,
"Ocp-Apim-Subscription-Key": app.config["MS_TTS_SECRET_KEY"],
"Authorization": "Bear " + gMsToken
}
log.info("reqHeaders=%s", reqHeaders)
# # for debug
# MS_TTS_SPEAKER = "zhang san"
ssmlDataStr = """
<speak version='1.0' xmlns="http://www.w3.org/2001/10/synthesis" xml:lang='en-US'>
<voice name='%s'>
<prosody rate='%s' volume='%s'>
%s
</prosody>
</voice>
</speak>
""" % (MS_TTS_SPEAKER, MS_TTS_RATE, MS_TTS_VOLUME, unicodeText)
log.info("ssmlDataStr=%s", ssmlDataStr)
resp = requests.post(msTtsUrl, headers=reqHeaders, data=ssmlDataStr)
log.info("resp=%s", resp)
statusCode = resp.status_code
log.info("statusCode=%s", statusCode)
if statusCode == 200:
# respContentType = resp.headers["Content-Type"] # 'audio/x-wav', 'audio/mpeg'
# log.info("respContentType=%s", respContentType)
# if re.match("audio/.*", respContentType):
audioBinData = resp.content
log.info("resp content is audio binary data, length=%d", len(audioBinData))
isOk = True
errMsg = ""
else:
isOk = False
errNo = resp.status_code
errMsg = resp.reason
log.error("resp errNo=%d, errMsg=%s", errNo, errMsg)
# errNo=400, errMsg=Voice zhang san not supported
# errNo=401, errMsg=Unauthorized
# errNo=413, errMsg=Content length exceeded the allowed limit of 1024 characters.
return isOk, audioBinData, errNo, errMsg
def doAudioSynthesis(unicodeText):
"""
do audio synthesis from unicode text
if failed for token invalid/expired, will refresh token to do one more retry
"""
global app, log, gCurBaiduRespDict
isOk = False
audioBinData = None
errMsg = ""
# # for debug
# gCurBaiduRespDict["access_token"] = "99.569b3b5b470938a522ce60d2e2ea2506.2592000.1528015602.282335-11192483"
log.info("doAudioSynthesis: unicodeText=%s", unicodeText)
# isOk, audioBinData, errNo, errMsg = baiduText2Audio(unicodeText)
isOk, audioBinData, errNo, errMsg = msTTS(unicodeText)
log.info("isOk=%s, errNo=%d, errMsg=%s", isOk, errNo, errMsg)
if isOk:
errMsg = ""
log.info("got synthesized audio binary data length=%d", len(audioBinData))
else:
# if errNo == BAIDU_ERR_TOKEN_INVALID:
if errNo == MS_ERR_UNAUTHORIZED:
log.warning("Token invalid -> retry one for refresh token")
# refreshBaiduToken()
refreshMsToken()
# isOk, audioBinData, errNo, errMsg = baiduText2Audio(unicodeText)
isOk, audioBinData, errNo, errMsg = msTTS(unicodeText)
log.info("after refresh token: isOk=%ss, errNo=%s, errMsg=%s", isOk, errNo, errMsg)
else:
log.warning("try synthesized audio occur error: errNo=%d, errMsg=%s", errNo, errMsg)
audioBinData = None
log.info("return isOk=%s, errMsg=%s", isOk, errMsg)
if audioBinData:
log.info("audio binary bytes=%d", len(audioBinData))
return isOk, audioBinData, errMsg
def testAudioSynthesis():
global app, log, gTempAudioFolder
# testInputUnicodeText = u"as a book-collector, i have the story you just want to listen!"
testInputUnicodeText = u"but i have an funny story, as well. would you like to listen, very very funny?"
# # for debug
# testInputUnicodeText = u"but i have an funny story, as well. ttttttttttooooooooolllllllllllooooooooonnnnnnnnnnggggggg but i have an funny story, as well. would you like to listen, very very funny?"
isOk, audioBinData, errMsg = doAudioSynthesis(testInputUnicodeText)
if isOk:
audioBinDataLen = len(audioBinData)
log.info("Now will save audio binary data %d bytes to file", audioBinDataLen)
# 1. save audio binary data into tmp file
newUuid = generateUUID()
log.info("newUuid=%s", newUuid)
tempFilename = newUuid + TTS_AUDIO_SUFFIX
log.info("tempFilename=%s", tempFilename)
if not gTempAudioFolder:
createAudioTempFolder()
tempAudioFullname = os.path.join(gTempAudioFolder, tempFilename) #'/Users/crifan/dev/dev_root/company/naturling/projects/robotDemo/server/tmp/audio/2aba73d1-f8d0-4302-9dd3-d1dbfad44458.mp3'
log.info("tempAudioFullname=%s", tempAudioFullname)
with open(tempAudioFullname, 'wb') as tmpAudioFp:
log.info("tmpAudioFp=%s", tmpAudioFp)
tmpAudioFp.write(audioBinData)
tmpAudioFp.close()
log.info("Done to write audio data into file of %d bytes", audioBinDataLen)
log.info("use celery to delay delete tmp file")
else:
log.warning("Fail to get synthesis audio for errMsg=%s", errMsg)
initAudioSynthesis()
testAudioSynthesis()
</code>config.py
<code># Audio Synthesis == TTS MS_TTS_SECRET_KEY = "224xxxxx2" MS_GET_TOKEN_URL = "https://westus.api.cognitive.microsoft.com/sts/v1.0/issueToken" MS_TTS_URL = "https://westus.tts.speech.microsoft.com/cognitiveservices/v1" </code>
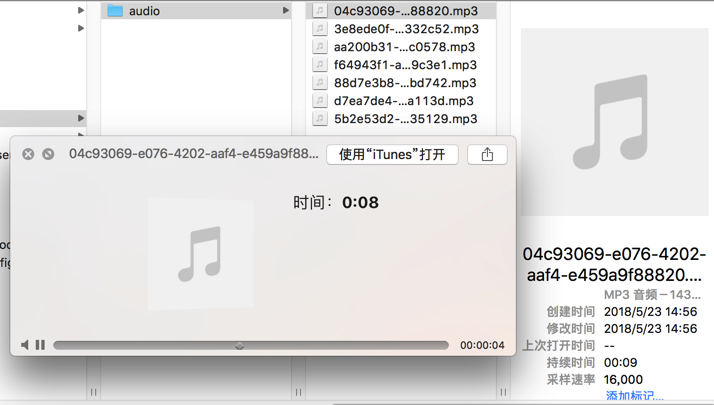
可以获得对应的token,和返回语音文件:
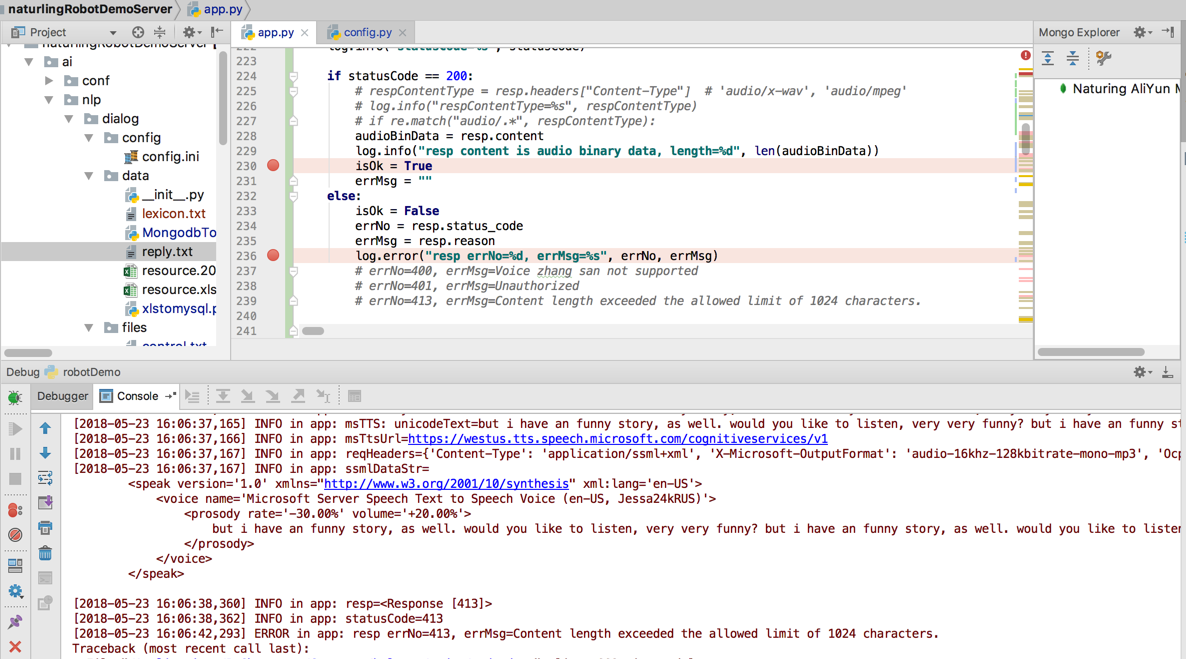
且调试模拟出错也是返回预期的错误的:
然后接着去:
新增celery的periodical的task,去refresh azure的token
【已解决】Flask中新增Celery周期任务去定期更新Azure的token
转载请注明:在路上 » 【已解决】把微软Azure语言合成TTS集成到Flask本地环境