折腾:
期间,已经搞定了如何传递data的json数据,已经可以获取返回的数据了,其中J字段包含要的数据。
但是后来又遇到另外问题:
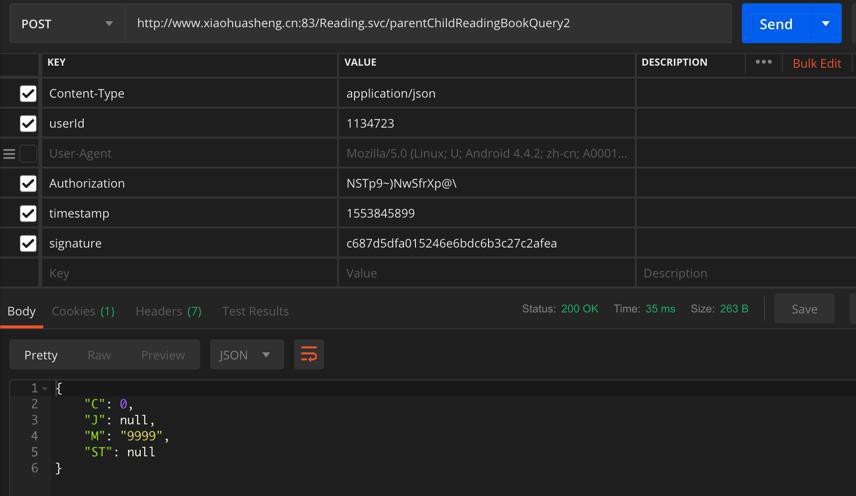
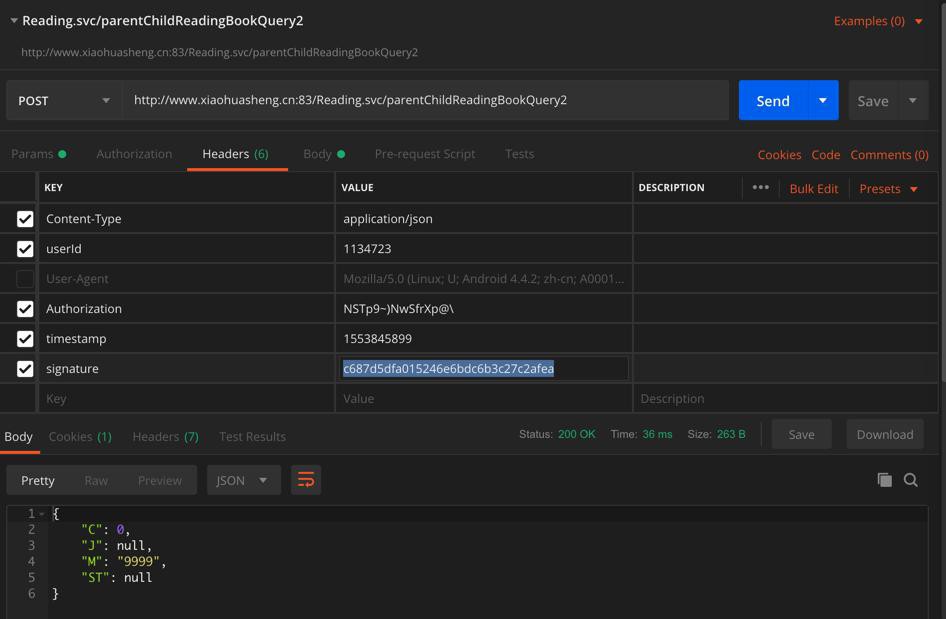
虽然调用api没有500错误,但是返回的J是空的:
{
"C": 0,
"J": null,
"M": "9999",
"ST": null
}
而对应的代码中,以为是格式问题,调试了半天:
ParentChildReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/parentChildReadingBookQuery2"
def getParentChildReading(self, offset, limit):
print("offset=%d, limit=%d" % (offset, limit))
# jTemplate = """{"userId":"%s","fieldName":"","fieldValue":"全部类别","theStageOfTheChild":"","parentalEnglishLevel":"","supportingResources":"有音频","offset":%d,"limit":%d}"""
jTemplate = "{\"userId\":\"%s\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":%d,\"limit\":%d}"
jcJsonDict = {
"J": jTemplate % (UserId, offset, limit),
"C": 0
}
print("jcJsonDict=%s" % jcJsonDict)
parentChildReadingParamDict = {
"offset": offset,
"limit": limit,
"jTemplate": jTemplate,
"jcJsonDict": jcJsonDict
}
# for debug
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"grades\":\"\",\"levels\":\"\",\"supportingResources\":\"有音频\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"grades\":\"\",\"levels\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":'{"userId":"1134723","fieldName":"","fieldValue":"全部类别","grades":"","levels":"","supportingResources":"","offset":0,"limit":10}',"C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":0,\"limit\":10}","C":0}
jcJsonDictStr = json.dumps(jcJsonDict)
print("jcJsonDictStr=%s" % jcJsonDictStr)
# # for debug
# jcJsonDictStr = '{"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}'
# print("jcJsonDictStr=%s" % jcJsonDictStr)
self.crawl(ParentChildReadingUrl,
method="POST",
# data=jcJsonDict,
data= jcJsonDictStr,
callback=self.getParentChildReadingCallback,
save=parentChildReadingParamDict
)经过大量的调试发现:
原来是:
不同的分页数据,对应着不同的timestamp和signature
此处抓包出来的是:
limit都是10
(1)offset=0
timestamp: 1553845333
signature: 2c30a3ac5898fa43eeececfa21560f5b
{"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":0,\"limit\":10}","C":0}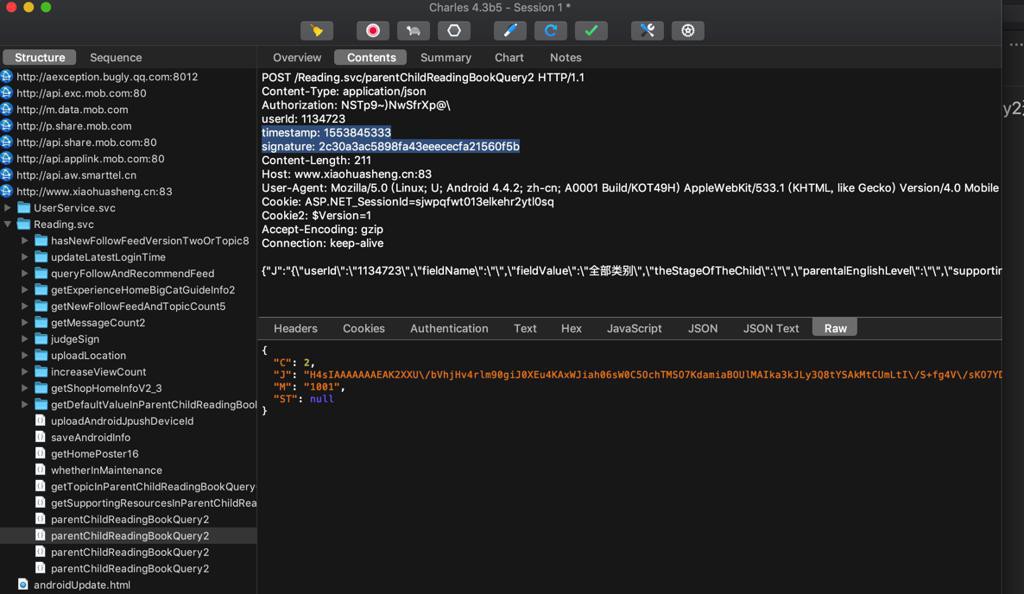
(2)offset=10
timestamp: 1553845860
signature: 1a9e12563d819f4ad929d01168a9347a
{"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":10,\"limit\":10}","C":0}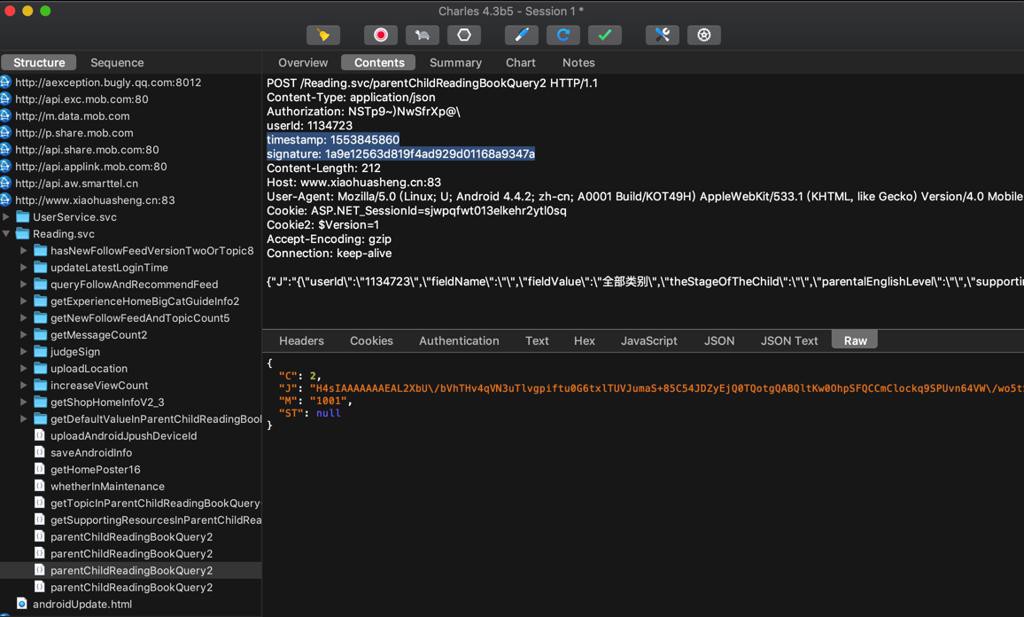
(3)offset=20
timestamp: 1553845899
signature: c687d5dfa015246e6bdc6b3c27c2afea
{"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":20,\"limit\":10}","C":0}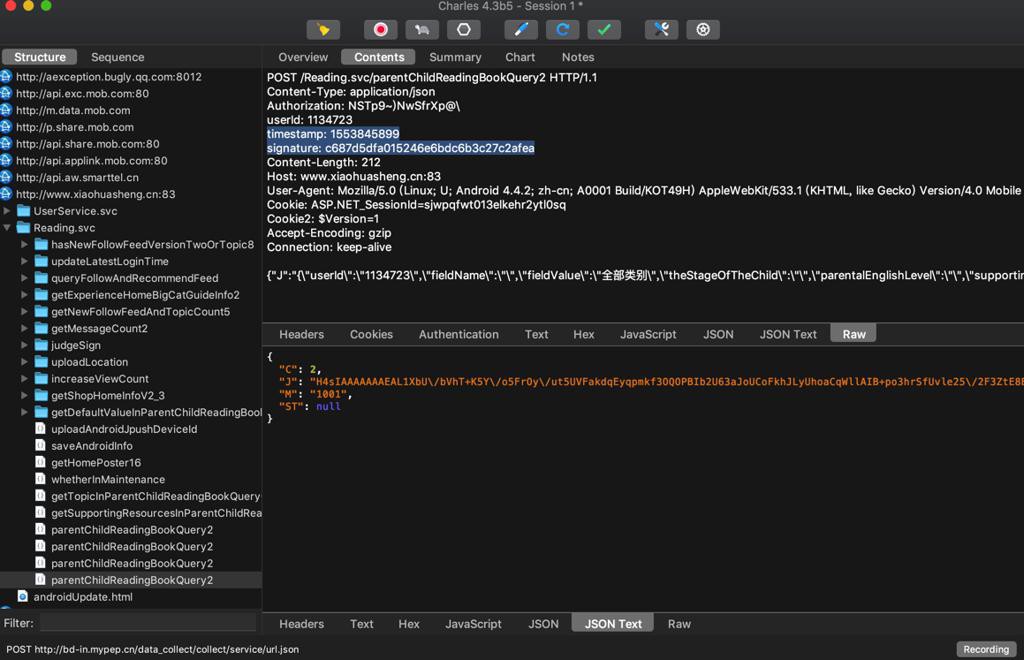
而去postman中测试,如果:
offset=0的
timestamp: 1553845333
signature: 2c30a3ac5898fa43eeececfa21560f5b
继续用在
offset=10
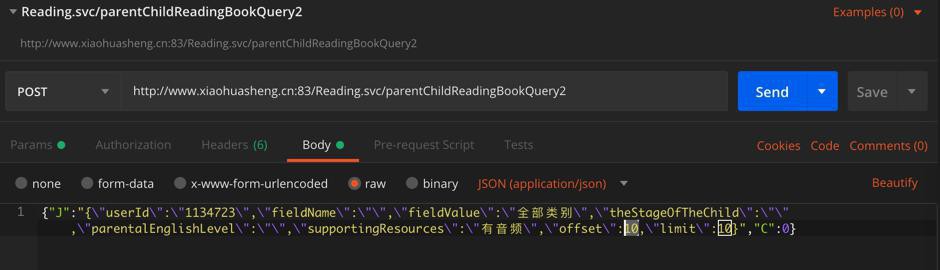
或者
其他如offset=20 的
timestamp: 1553845899
signature: c687d5dfa015246e6bdc6b3c27c2afea
用到了offset=10
都会导致
{
"C": 0,
"J": null,
"M": "9999",
"ST": null
}
那问题就转换为:
【已解决】小花生app中调用接口parentChildReadingBookQuery2时timestamp和signature生成的逻辑
【总结】
之前返回空数据,是因为signature的值不对,所以会返回空数据。
而现在已可以,生成正确的signature,所以就可以继续调用api获取json,且解密json了。
完整代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-03-27 15:35:20
# Project: XiaohuashengApp
from pyspider.libs.base_handler import *
import os
import json
import codecs
import base64
import gzip
import copy
import time
# import datetime
from datetime import datetime, timedelta
from hashlib import md5
######################################################################
# Const
######################################################################
SelfReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/selfReadingBookQuery2"
ParentChildReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/parentChildReadingBookQuery2"
RESPONSE_OK = "1001"
######################################################################
# Config & Settings
######################################################################
OutputFolder = "/Users/crifan/dev/dev_root/company/xxx/projects/crawler_projects/crawler_xiaohuasheng_app/output"
DefaultPageSize = 10
UserAgentNoxAndroid = "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; A0001 Build/KOT49H) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"
gUserId = "1134723"
gAuthorization = """NSTp9~)NwSfrXp@\\"""
# Timestamp = "1553671960"
# Signature = "bc8d887e7f16ef92269f55bfd74e131b"
# Timestamp = "1553671956"
# Signature = "a1f51f6852f42d934f0ac154dc374500"
# Timestamp = "1553675572"
# Signature = "d516df23120d3c9f0397475f03c61199"
# gTimestamp = "1553845333"
# gSignature = "2c30a3ac5898fa43eeececfa21560f5b"
gUserToken = "40d2267f-359e-4526-951a-66519e5868c3"
gSecretKey = “AyGt7ohMR!xx#N"
gHeaders = {
"Host": "www.xiaohuasheng.cn:83",
"User-Agent": UserAgentNoxAndroid,
"Content-Type": "application/json",
"userId": gUserId,
"Authorization": gAuthorization,
# "timestamp": gTimestamp,
# "signature": gSignature,
"cookie": "ASP.NET_SessionId=dxf3obxgn5t4w350xp3icgy0",
# "Cookie2": "$Version=1",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"cache-control": "no-cache",
"Connection": "keep-alive",
# "content-length": "202",
}
######################################################################
# Common Util Functions
######################################################################
def getCurTimestamp(withMilliseconds=False):
"""
get current time's timestamp
(default)not milliseconds -> 10 digits: 1351670162
with milliseconds -> 13 digits: 1531464292921
"""
curDatetime = datetime.now()
return datetimeToTimestamp(curDatetime, withMilliseconds)
def datetimeToTimestamp(datetimeVal, withMilliseconds=False) :
"""
convert datetime value to timestamp
eg:
"2006-06-01 00:00:00.123" -> 1149091200
if with milliseconds -> 1149091200123
:param datetimeVal:
:return:
"""
timetupleValue = datetimeVal.timetuple()
timestampFloat = time.mktime(timetupleValue) # 1531468736.0 -> 10 digits
timestamp10DigitInt = int(timestampFloat) # 1531468736
timestampInt = timestamp10DigitInt
if withMilliseconds:
microsecondInt = datetimeVal.microsecond # 817762
microsecondFloat = float(microsecondInt)/float(1000000) # 0.817762
timestampFloat = timestampFloat + microsecondFloat # 1531468736.817762
timestampFloat = timestampFloat * 1000 # 1531468736817.7621 -> 13 digits
timestamp13DigitInt = int(timestampFloat) # 1531468736817
timestampInt = timestamp13DigitInt
return timestampInt
def extractSuffix(fileNameOrUrl):
"""
extract file suffix from name or url
eg:
https://cdn2.xxx.cn/2018-09-10/15365514898246.mp4 -> mp4
15365514894833.srt -> srt
"""
return fileNameOrUrl.split('.')[-1]
def createFolder(folderFullPath):
"""
create folder, even if already existed
Note: for Python 3.2+
"""
os.makedirs(folderFullPath, exist_ok=True)
print("Created folder: %s" % folderFullPath)
def saveDataToFile(fullFilename, binaryData):
"""save binary data info file"""
with open(fullFilename, 'wb') as fp:
fp.write(binaryData)
fp.close()
print("Complete save file %s" % fullFilename)
def saveJsonToFile(fullFilename, jsonValue):
"""save json dict into file"""
with codecs.open(fullFilename, 'w', encoding="utf-8") as jsonFp:
json.dump(jsonValue, jsonFp, indent=2, ensure_ascii=False)
print("Complete save json %s" % fullFilename)
def loadJsonFromFile(fullFilename):
"""load and parse json dict from file"""
with codecs.open(fullFilename, 'r', encoding="utf-8") as jsonFp:
jsonDict = json.load(jsonFp)
print("Complete load json from %s" % fullFilename)
return jsonDict
######################################################################
# Main
######################################################################
class Handler(BaseHandler):
crawl_config = {
# 'headers': {
# "Host": "www.xiaohuasheng.cn:83",
# "User-Agent": UserAgentNoxAndroid,
# "Content-Type": "application/json",
# "userId": gUserId,
# "Authorization": gAuthorization,
# # "timestamp": gTimestamp,
# # "signature": gSignature,
# "cookie": "ASP.NET_SessionId=dxf3obxgn5t4w350xp3icgy0",
# # "Cookie2": "$Version=1",
# "Accept": "*/*",
# "Accept-Encoding": "gzip, deflate",
# "cache-control": "no-cache",
# "Connection": "keep-alive",
# # "content-length": "202",
# },
}
def on_start(self):
offset = 0
limit = DefaultPageSize
self.getParentChildReading(offset, limit)
def getParentChildReading(self, offset, limit):
print("offset=%d, limit=%d" % (offset, limit))
# jTemplate = """{"userId":"%s","fieldName":"","fieldValue":"全部类别","theStageOfTheChild":"","parentalEnglishLevel":"","supportingResources":"有音频","offset":%d,"limit":%d}"""
jTemplate = "{\"userId\":\"%s\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":%d,\"limit\":%d}"
jcJsonDict = {
"J": jTemplate % (gUserId, offset, limit),
"C": 0
}
# print("jcJsonDict=%s" % jcJsonDict)
parentChildReadingParamDict = {
"offset": offset,
"limit": limit,
"jTemplate": jTemplate,
"jcJsonDict": jcJsonDict
}
# for debug
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"grades\":\"\",\"levels\":\"\",\"supportingResources\":\"有音频\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"grades\":\"\",\"levels\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}
# jcJsonDict = {"J":'{"userId":"1134723","fieldName":"","fieldValue":"全部类别","grades":"","levels":"","supportingResources":"","offset":0,"limit":10}',"C":0}
# jcJsonDict = {"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":0,\"limit\":10}","C":0}
jValueStr = jcJsonDict["J"]
# print("jValueStr=%s" % jValueStr)
jcJsonDictStr = json.dumps(jcJsonDict)
# print("jcJsonDictStr=%s" % jcJsonDictStr)
# # for debug
# jcJsonDictStr = '{"J":"{\"userId\":\"1134723\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"\",\"offset\":0,\"limit\":10}","C":0}'
# print("jcJsonDictStr=%s" % jcJsonDictStr)
curHeaders = copy.deepcopy(gHeaders)
# print("curHeaders=%s" % curHeaders)
# print("type(curHeaders)=%s" % type(curHeaders))
curTimestampInt = getCurTimestamp()
# # for debug
# curTimestampInt = int(gTimestamp)
# print("curTimestampInt=%s" % curTimestampInt)
curTimestampStr = str(curTimestampInt)
# print("curTimestampStr=%s" % curTimestampStr)
curHeaders["timestamp"] = curTimestampStr
# jValueParamStr = jcJsonDictStr
# jcJsonDictFormattedStr = "%s" % jcJsonDict
# jcJsonDictFormattedStr = jcJsonDictFormattedStr.replace(" ", "")
# print("jcJsonDictFormattedStr=%s" % jcJsonDictFormattedStr)
# jValueParamStr = jcJsonDictFormattedStr
jValueParamStr = jValueStr
calculatedSignature = self.generateSignature(curTimestampInt, jValueParamStr)
# print("calculatedSignature=%s" % calculatedSignature)
curHeaders["signature"] = calculatedSignature
# # for debug
# curHeaders["signature"] = gSignature
# print("debug signature=%s" % curHeaders["signature"])
self.crawl(ParentChildReadingUrl,
method="POST",
# data=jcJsonDict,
data= jcJsonDictStr,
callback=self.getParentChildReadingCallback,
headers=curHeaders,
save=parentChildReadingParamDict
)
def generateSignature(self, timestampInt, jValueParamStr):
# print("generateSignature: timestampInt=%d, jValueParamStr=%s" % (timestampInt, jValueParamStr))
# userId = "1134723"
userId = gUserId
timestamp = "%s" % timestampInt
# localObject = "/Reading.svc/parentChildReadingBookQuery2"
# localObject = jValueParamStr
# userToken = "40d2267f-359e-4526-951a-66519e5868c3"
userToken = gUserToken
# fixedSault = “AyGt7ohMR!xx#N"
# secretKey = “AyGt7ohMR!xx#N"
secretKey = gSecretKey
# strToCalc = userId + timestamp + localObject + jValueParamStr + fixedSault
# strToCalc = timestamp + localObject + fixedSault
strToCalc = userId + timestamp + jValueParamStr + userToken + secretKey
# print("strToCalc=%s" % strToCalc)
encodedStr = strToCalc.encode()
# encodedStr = strToCalc.encode("UTF-8")
# print("encodedStr=%s" % encodedStr)
md5Result = md5(encodedStr)
# print("md5Result=%s" % md5Result) # md5Result=<md5 HASH object @ 0x1044f1df0>
# md5Result = md5()
# md5Result.update(strToCalc)
# md5Digest = md5Result.digest()
# print("md5Digest=%s" % md5Digest) #
# print("len(md5Digest)=%s" % len(md5Digest))
md5Hexdigest = md5Result.hexdigest()
# print("md5Hexdigest=%s" % md5Hexdigest)
# print("len(md5Hexdigest)=%s" % len(md5Hexdigest))
# md5Hexdigest=c687d5dfa015246e6bdc6b3c27c2afea
print("md5=%s from %s" % (md5Hexdigest, strToCalc))
return md5Hexdigest
# return md5Digest
def extractResponseData(self, respJson):
"""
{
"C": 2,
"J": "H4sIAA.......AA=",
"M": "1001",
"ST": null
}
"""
# respJson = json.loads(respJson)
respM = respJson["M"]
if respM != RESPONSE_OK:
return None
encodedStr = respJson["J"]
decodedStr = base64.b64decode(encodedStr)
# print("decodedStr=%s" % decodedStr)
decompressedStr = gzip.decompress(decodedStr)
# print("decompressedStr=%s" % decompressedStr)
decompressedStrUnicode = decompressedStr.decode("UTF-8")
# print("decompressedStrUnicode=%s" % decompressedStrUnicode)
decompressedJson = json.loads(decompressedStrUnicode)
respDataDict = decompressedJson
return respDataDict
def getParentChildReadingCallback(self, response):
respUrl = response.url
print("respUrl=%s" % respUrl)
prevParaDict = response.save
print("prevParaDict=%s" % prevParaDict)
respJson = response.json
print("respJson=%s" % respJson)
respData = self.extractResponseData(respJson)
print("respData=%s" % respData)
if respData:
bookSeriesList = respData
for eachBookSerie in bookSeriesList:
print("eachBookSerie=%s" % eachBookSerie)
# self.getStorybookDetail(eachBookSerie)
prevOffset = prevParaDict["offset"]
limit = prevParaDict["limit"]
print("prevOffset=%d, limit=%d" % (prevOffset, limit))
offset = prevOffset + limit
self.getParentChildReading(offset, limit)
else:
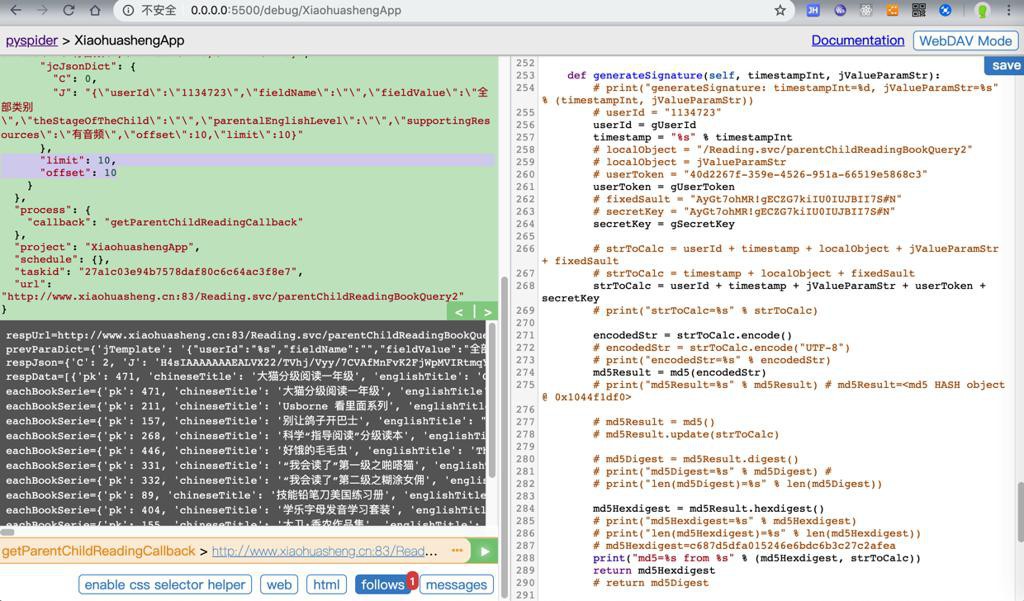
print("!!! %s return no more data: %s" % (response.url, respJson))效果:
转载请注明:在路上 » 【已解决】PySpider模拟小花生app请求parentChildReadingBookQuery2返回空数据