折腾:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
期间,虽然已经用代码:
<code># -*- coding: utf-8 -*-
import scrapy
# from scrapy import Request, Spider
from urllib import urlencode, unquote
import re
import json
from bs4 import BeautifulSoup
import os
class YoutubesubtitleSpider(scrapy.Spider):
name = 'YoutubeSubtitle'
allowed_domains = ['youtube.com', "yousubtitles.com"]
start_urls = [
"https://www.youtube.com/user/theofficialhumf/playlists"
]
# def start_requests(self):
# """This is our first request to grab all the urls of the profiles.
# """
# for url in self.start_urls:
# self.logger.info("url=%s", url)
#
# yield scrapy.Request(
# url=url,
# meta={
# "proxy": "http://127.0.0.1:1087"
# },
# callback=self.parse,
# )
def saveToFile(self, filename, content, suffix=".html"):
filename = filename + suffix
with open(filename, 'wb') as f:
f.write(content)
def parse(self, response):
respUrl = response.url
print "respUrl=%s"%(respUrl)
filename = respUrl.split("/")[-2] + '.html'
self.saveToFile(filename=filename, content=response.body)
# with open(filename, 'wb') as f:
# f.write(response.body)
# extract group/collection url
lockupElemList = response.xpath('//div[@class="yt-lockup-thumbnail"]/a[starts-with(@href, "/watch")]')
self.logger.info("lockupElemList=%s", lockupElemList)
for eachLockupElem in lockupElemList:
self.logger.info("eachLockupElem=%s", eachLockupElem)
# href = eachLockupElem.xpath('//div/a/@href')
hrefValue = eachLockupElem.xpath('@href').extract()
self.logger.info("hrefValue=%s", hrefValue)
groupUrl = u"https://www.youtube.com" + hrefValue[0]
self.logger.info("groupUrl=%s", groupUrl)
yield scrapy.Request(url=groupUrl, callback=self.parseEachYoutubeUrl)
def parseEachYoutubeUrl(self, response):
"""
parse each youtube url from group url's response
:param response:
:return:
"""
# for debug
respUrl = response.url
self.logger.info("respUrl=%s", respUrl)
self.saveToFile("groupUrl", response.body)
dataIdElemList = response.xpath('//li[@data-video-id]/a[@href]')
self.logger.info("dataIdElemList=%s", dataIdElemList)
if dataIdElemList:
dataIdElemListCount = len(dataIdElemList)
self.logger.info("dataIdElemListCount=%s", dataIdElemListCount)
for eachDataIdElem in dataIdElemList:
self.logger.info("eachDataIdElem=%s", eachDataIdElem)
hrefValue = eachDataIdElem.xpath('@href').extract()
self.logger.info("hrefValue=%s", hrefValue)
singleVideoUrl = u"https://www.youtube.com" + hrefValue[0]
self.logger.info("singleVideoUrl=%s", singleVideoUrl)
# https://www.youtube.com/watch?v=23t1f8d2ISs&list=PLHOR8x-IicVJDAmJWZmJ-IMu1x3lTAld5&index=1
# # http://www.yousubtitles.com/load/?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DgtaC1JVjvO4%26index%3D58%26list%3DPLHOR8x-IicVJDAmJWZmJ-IMu1x3lTAld5&ch=1
# yousubtitlesUrlBase = "http://www.yousubtitles.com/load/?"
# youtubeUrlParaDict = {"url" : singleVideoUrl}
# encodedUrlPara = urlencode(youtubeUrlParaDict)
# fullYousubtitlesUrl = yousubtitlesUrlBase + encodedUrlPara
#
# yield scrapy.Request(url=fullYousubtitlesUrl, callback=self.parseYoususbtitlesUrl)
foundVideoId = re.search(r'v=(?P<videoId>[\w\-]+)', singleVideoUrl)
if foundVideoId:
videoId = foundVideoId.group("videoId")
self.logger.info("videoId=%s", videoId) # u'23t1f8d2ISs'
# http://www.yousubtitles.com/loadvideo/23t1f8d2ISs
loadVideoUrl = "http://www.yousubtitles.com/loadvideo/" + videoId
self.logger.info("loadVideoUrl=%s", loadVideoUrl) # u'http://www.yousubtitles.com/loadvideo/23t1f8d2ISs'
yield scrapy.Request(url=loadVideoUrl, callback=self.parseLoadVideoResp, method="POST")
def parseLoadVideoResp(self, response):
"""
parse response of yousubtitles load video for each youtube video id
:param response:
:return:
"""
# for debug
self.saveToFile("loadvideo", response.body)
respUrl = response.url # 'http://www.yousubtitles.com/loadvideo/UhO0bkdC4pQ'
self.logger.info("respUrl=%s", respUrl)
decodedLinksDict = json.loads(response.body)
self.logger.info("decodedLinksDict=%s", decodedLinksDict)
if "links" not in decodedLinksDict:
self.logger.warning("links not in decodedLinksDict=%s", decodedLinksDict)
# {u'error': 1}
else:
linksHtml = decodedLinksDict["links"]
# self.logger.info("linksHtml=%s", linksHtml)
linksSoup = BeautifulSoup(linksHtml)
self.logger.info("linksSoup=%s", linksSoup)
englishNode = linksSoup.find(lambda tag : tag.name == "p" and "English" in tag.get_text())
if englishNode:
# self.logger.info("englishNode.contents=%s", englishNode.contents)
self.logger.info("englishNode.text=%s", englishNode.text)
# self.logger.info("englishNode=%s", englishNode)
downloadHref = englishNode.a["href"]
self.logger.info("downloadHref=%s", downloadHref) # /download/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fsignature%3D0300D3B6307468779D9FE34128AAC8FA4EE978E4.7D5E553538919EB4479D2AD710C693BABDED961D%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cxorp%252Cexpire%26asr_langs%3Des%252Cru%252Cit%252Cnl%252Cpt%252Cde%252Cko%252Cja%252Cen%252Cfr%26caps%3Dasr%26hl%3Den_US%26xorp%3DTrue%26key%3Dyttt1%26expire%3D1520333270%26v%3D23t1f8d2ISs%26kind%3Dasr%26lang%3Den&title=Humf+-+Compilation+%28episodes+16+to+22%29
downloadUrl = "http://www.yousubtitles.com" + downloadHref # http://www.yousubtitles.com/download/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fsignature%3D0300D3B6307468779D9FE34128AAC8FA4EE978E4.7D5E553538919EB4479D2AD710C693BABDED961D%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cxorp%252Cexpire%26asr_langs%3Des%252Cru%252Cit%252Cnl%252Cpt%252Cde%252Cko%252Cja%252Cen%252Cfr%26caps%3Dasr%26hl%3Den_US%26xorp%3DTrue%26key%3Dyttt1%26expire%3D1520333270%26v%3D23t1f8d2ISs%26kind%3Dasr%26lang%3Den&title=Humf+-+Compilation+%28episodes+16+to+22%29
self.logger.info("downloadUrl=%s", downloadUrl)
yield scrapy.Request(url=downloadUrl, callback=self.parseDownloadSubtitlesResp)
else:
self.logger.warning("can not find english subtile node")
def parseDownloadSubtitlesResp(self, response):
"""
parse download subtitles of youtube video
:param response:
:return:
"""
# for debug
respUrl = response.url # http://www.yousubtitles.com/download/?url=http%3A%2F%2Fwww.youtube.com%2Fapi%2Ftimedtext%3Fsignature%3D4A2A6F9EA37E8A508D6D3C93B575ADFFAA910E66.40BD74A9A28E3B158532EE17837676F7B11B1180%26xorp%3DTrue%26sparams%3Dasr_langs%252Ccaps%252Cv%252Cxorp%252Cexpire%26asr_langs%3Dde%252Cru%252Cko%252Cja%252Cen%252Cpt%252Cit%252Ces%252Cnl%252Cfr%26hl%3Den_US%26key%3Dyttt1%26caps%3Dasr%26expire%3D1520333397%26v%3D23t1f8d2ISs%26kind%3Dasr%26lang%3Den&title=Humf+-+Compilation+%28episodes+16+to+22%29
self.logger.info("respUrl=%s", respUrl)
decodedUrl = unquote(respUrl) # http://www.yousubtitles.com/download/?url=http://www.youtube.com/api/timedtext?caps=asr&v=7A6y4WPkG5o&expire=1520334242&asr_langs=en%2Cfr%2Cja%2Cko%2Cde%2Cpt%2Cit%2Cnl%2Cru%2Ces&hl=en_US&xorp=True&key=yttt1&signature=26E544FE885C617E1B6AC946C1EE21C1E0C95795.83020B2CBAF8806252387C5AD7BA0879B2CC1888&sparams=asr_langs%2Ccaps%2Cv%2Cxorp%2Cexpire&kind=asr&lang=en&title=Humf+-+25++Slow+Down,+Wallace++(full+episode)
self.logger.info("decodedUrl=%s", decodedUrl)
foundIdName = re.search(r'[&|?]v=(?P<videoId>[\w\-]+).*&title=(?P<videoTitle>[^&]+)', decodedUrl)
if foundIdName:
videoId = foundIdName.group("videoId") # '7A6y4WPkG5o'
videoTitle = foundIdName.group("videoTitle") # Humf+-+25++Slow+Down,+Wallace++(full+episode)
subtitleFilename = videoId + "_" + videoTitle
downloadFolder = "download_subtitles/Humf"
if not os.path.exists(downloadFolder):
os.makedirs(downloadFolder)
self.saveToFile(downloadFolder + "/" + subtitleFilename, response.body, suffix=".srt")
else:
self.logger.warning("can not find id and name")
# def parseYoususbtitlesUrl(self, response):
# """
# parse each yousubtitles.com download response
# :param response:
# :return:
# """
# # for debug
# self.saveToFile("yousubtitles_load", response.body)
# respUrl = response.url
# self.logger.info("respUrl=%s", respUrl)
</code>下载到了字幕:
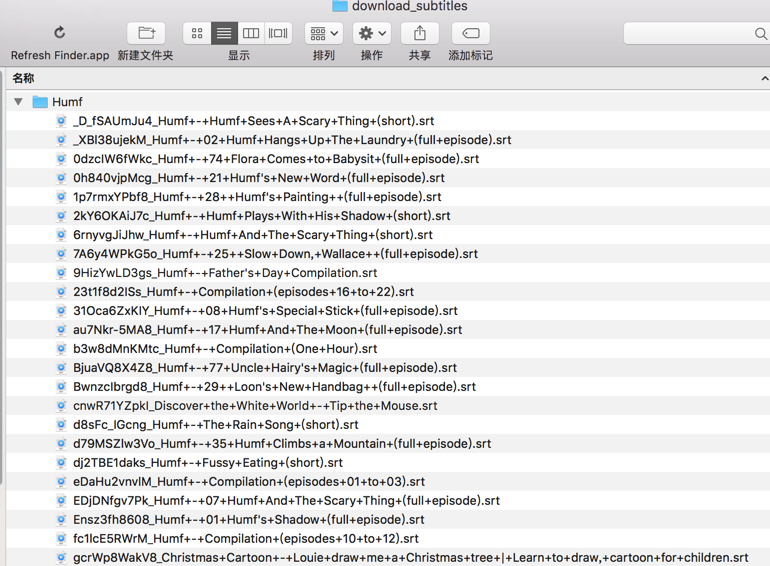
但是,希望是:
保存字幕时,能够放到自己的系列中
所以希望在下载保存字幕时,能否把前面的所属哪个系列的系列名传递过来
所以就转换为scrapy在后续的处理request时,能否获得前面传递过来的其他参数等信息
希望把这个
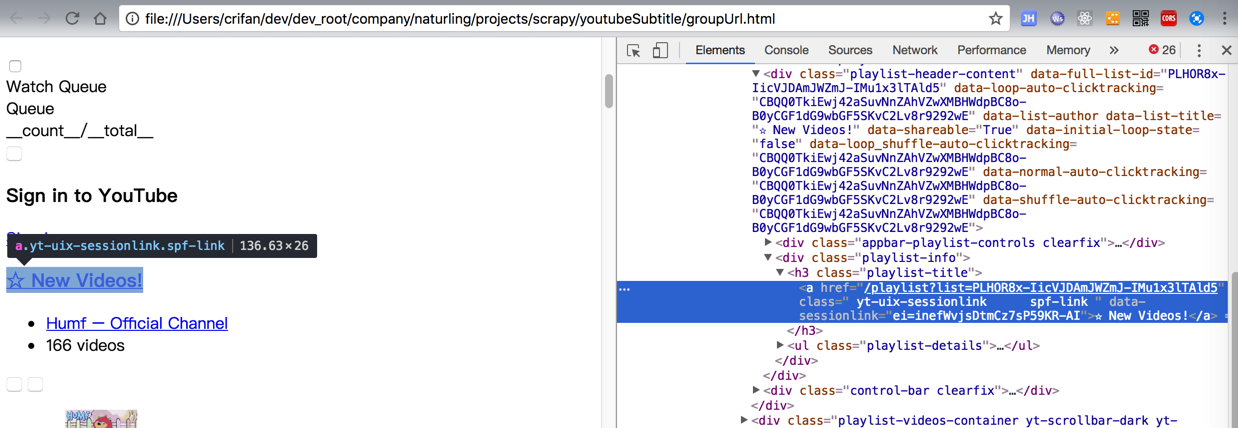
h3的class=”playlist-title”
传递到后面
scrapy pass parameter to callback
python – Passing a argument to a callback function – Stack Overflow
用meta去传递
Requests and Responses — Scrapy 1.5.0 documentation
看到有meta了:
“* meta (dict) – the initial values for the Request.meta attribute. If given, the dict passed in this parameter will be shallow copied.
meta
A dict that contains arbitrary metadata for this request. This dict is empty for new Requests, and is usually populated by different Scrapy components (extensions, middlewares, etc). So the data contained in this dict depends on the extensions you have enabled.
See Request.meta special keys for a list of special meta keys recognized by Scrapy.
This dict is shallow copied when the request is cloned using the copy() or replace()methods, and can also be accessed, in your spider, from the response.meta attribute.”
meta中的,可以被Scrapy的extension识别的,一些特殊的key:
Requests and Responses — Scrapy 1.5.0 documentation
通过:
<code>yield scrapy.Request(url=loadVideoUrl, callback=self.parseLoadVideoResp, method="POST", meta={"humfGroupTitle" : humfGroupTitle})
</code>yield scrapy.Request(url=downloadUrl, callback=self.parseDownloadSubtitlesResp, meta=response.meta)
调试期间发现,除了自己的参数,还有其他一些:
<code>2018-03-07 14:00:38 [YoutubeSubtitle] INFO: response.meta={'download_timeout': 180.0, 'depth': 3, 'proxy': 'http://127.0.0.1:1087', 'humfGroupTitle': u'\u2606 New Videos!', 'download_latency': 3.410896062850952, 'download_slot': 'www.yousubtitles.com'}
</code>【总结】
Scrapy可以向后传递参数的,可以借用meta,比如:
<code>yield scrapy.Request(url=loadVideoUrl, callback=self.parseLoadVideoResp, method="POST", meta={"humfGroupTitle" : humfGroupTitle})
</code>之后的callback中即可通过response.meta去取值:
<code>def parseLoadVideoResp(self, response): humfGroupTitle = response.meta["humfGroupTitle"] </code>
即可。