折腾:
【记录】用PySpider去爬取scholastic的绘本书籍数据
期间,去真正Run批量爬取,结果看到输出的log中出错:
[I 181016 09:10:38 result_worker:33] result ScholasticStorybook:b9571bf852d2a10a2f14a999e5f8c51b
https://www.scholastic.com/content/scholastic/books2/house-of-robots-by-chris-grabenstein
-> {'originUrl': '
https://www.sch
[E 181016 09:10:38 result_worker:63] Object of type 'ObjectId' is not JSON serializable
Traceback (most recent call last):
File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/result/result_worker.py", line 54, in run
self.on_result(task, result)
File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/result/result_worker.py", line 38, in on_result
result=result
File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/database/sqlite/resultdb.py", line 58, in save
return self._replace(tablename, **self._stringify(obj))
File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/database/sqlite/resultdb.py", line 44, in _stringify
data['result'] = json.dumps(data['result'])
File "/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/__init__.py", line 231, in dumps
return _default_encoder.encode(obj)
File "/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/encoder.py", line 199, in encode
chunks = self.iterencode(o, _one_shot=True)
File "/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/encoder.py", line 257, in iterencode
return _iterencode(o, 0)
File "/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/encoder.py", line 180, in default
o.__class__.__name__)
TypeError: Object of type 'ObjectId' is not JSON serializable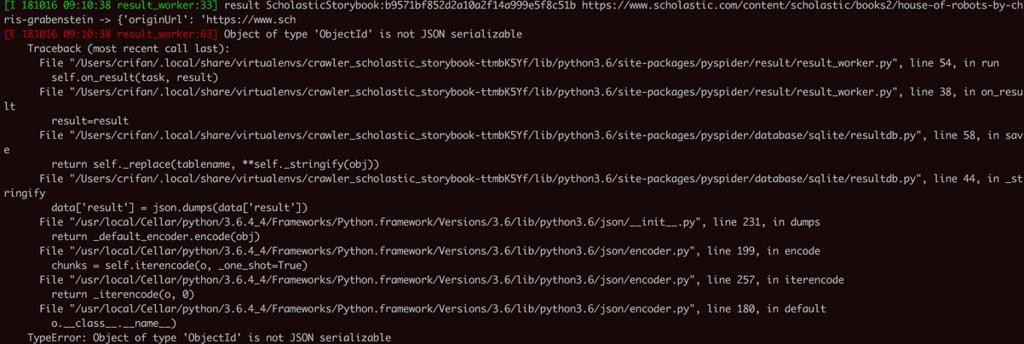
以为出错的url是:
后来发现不是。
然后以为是ObjectId,是之前接触到的MongoDB中的变量类型
所以去把代码改为:
class ResultMongo(object):
...
def on_result(self, result):
"""save result to mongodb"""
print("ResultMongo on_result: result=%s" % result)
respResult = None
if result:
respResult = self.collection.insert(result)
print("respResult=%s" % respResult) # respResult=5bc45fad7f4d3847b78e8c69
# return respResult即:不去保存和返回mongodb的insert返回的ObjectId类型的变量了。
结果问题依旧。
怀疑是:
class Handler(BaseHandler):
mongo = ResultMongo()
print("mongo=%s" % mongo)
。。。
def on_result(self, result):
print("PySpider on_result: result=%s" % result)
self.mongo.on_result(result) # 执行插入数据的操作
super(Handler, self).on_result(result) # 调用原有的数据存储中
super(Handler, self).on_result(result)
的问题,都想要去注释掉呢,反正其实也用不到,数据都已保存到MongoDB了。
然后对于此处错误,开始以为只有一处出错,后来看log才发现:
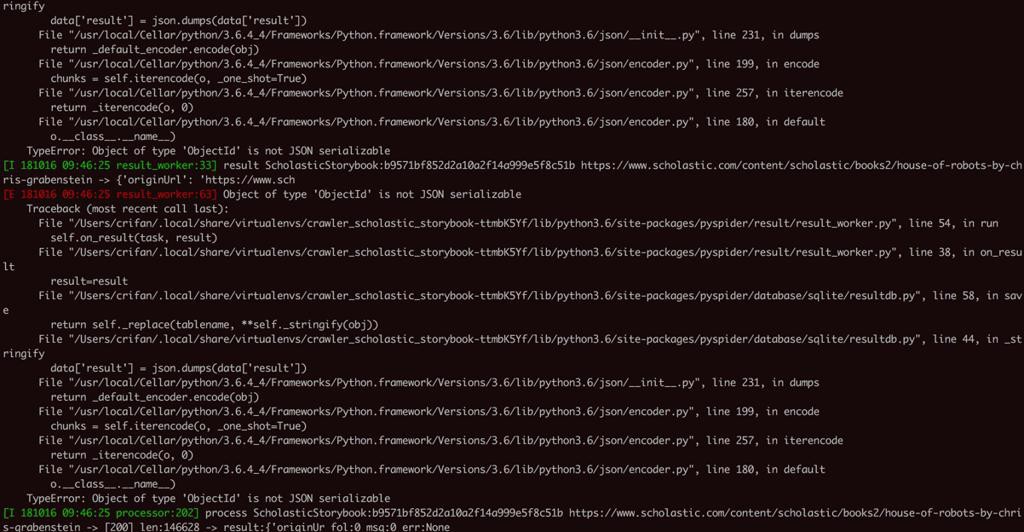
是多处都出错了
-》证明不是某个url的问题
-》基本上确定就是:
super(Handler, self).on_result(result)
的问题
-》估计是json里面嵌套的值,此处PySPider中无法直接保存,而出错的。
-》打算去注释掉。
先不这么做,先去注释掉要保存的数据中的recommendations:
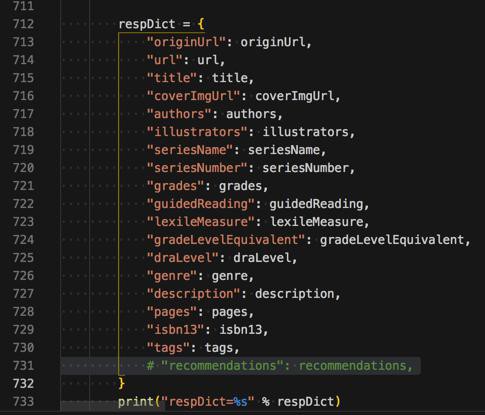
因为recommendations是对象的列表而不是普通变量类型的列表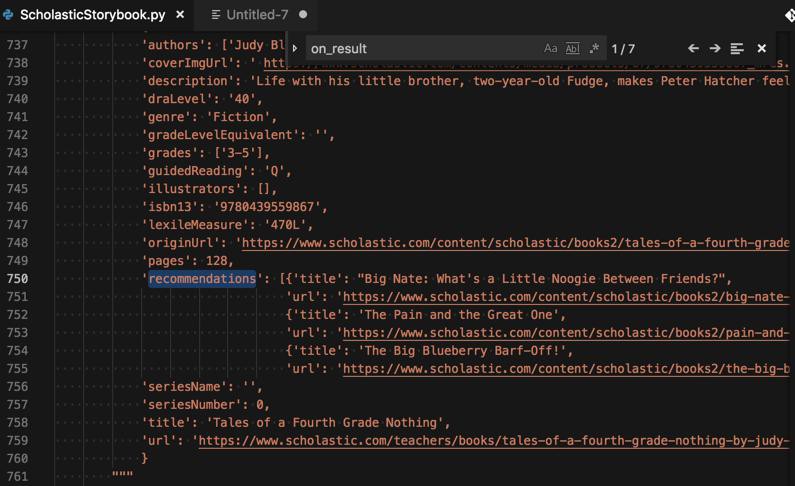
-》而其他要保存的字段都是普通的类型,应该不会出现无法保存的问题。
然后再去运行看看:
如果没有出现此处问题,就说明之前猜测是对的。
竟然还是出错,问题依旧:
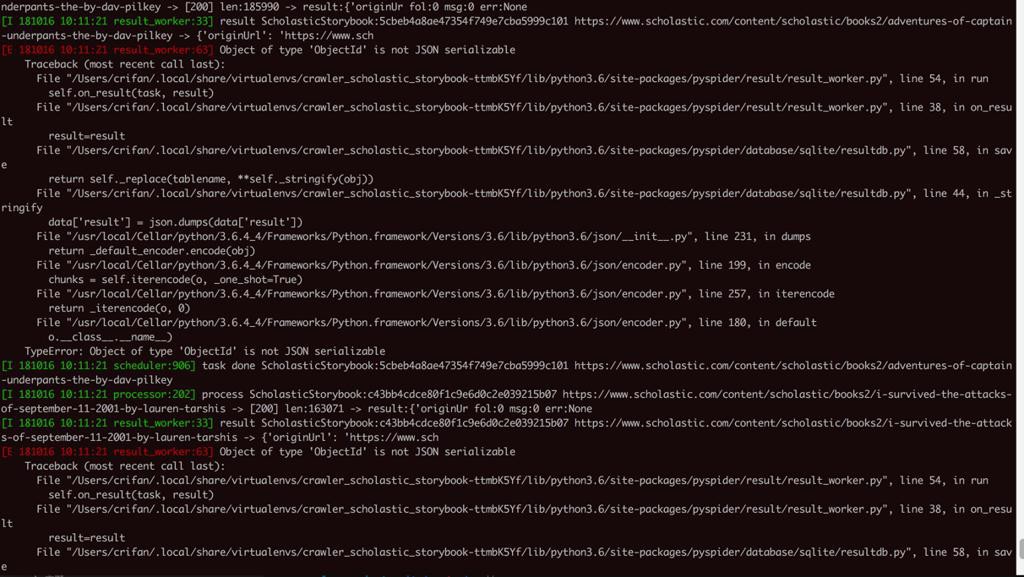
pyspider TypeError: Object of type ‘ObjectId’ is not JSON serializable
pyspider result_worker TypeError Object of type not JSON serializable
确定就是PySPider中的result_worker的报的错
且此处是不支持ObjectId
-》而ObjectId本身是pymongo的类型
-》所以要去搞清楚,此处保存的数据中,到底哪里包含了:
ObjectId
而此处感觉能和ObjectId有关系的,就只有这一处,所以强制转换为str吧:
def on_result(self, result):
"""save result to mongodb"""
print("ResultMongo on_result: result=%s" % result)
respResult = None
if result:
respResult = self.collection.insert(result)
print("type(respResult)=%s" % type(respResult))
respResult = str(respResult)
print("type(respResult)=%s" % type(respResult))
print("respResult=%s" % respResult) # respResult=5bc45fad7f4d3847b78e8c69
return respResult先去调试确保输出是str:
type(respResult)=<class 'bson.objectid.ObjectId'> type(respResult)=<class 'str'> respResult=5bc54e0bbfaa44fcce305d8d
然后再去批量爬取,结果:
问题依旧。
去看Results:
果然是空的:
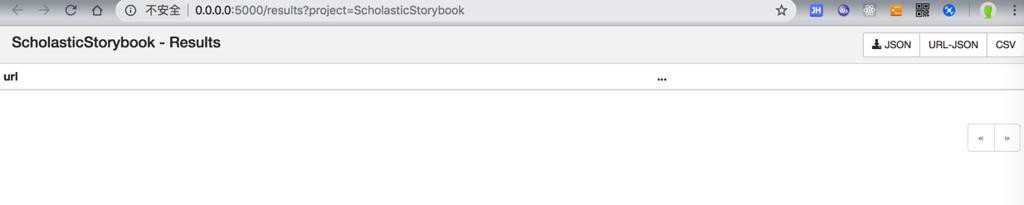
都没有保存成功。
感觉:
super(Handler, self).on_result(result) # 调用原有的数据存储
的写法,难道有问题?
先去加上提调试代码:
for eachValue in respDict.values():
print("eachValue=%s, type(eachValue)=%s", eachValue, type(eachValue))看看保存数据的类型是否全是普通类型
eachValue=
https://www.scholastic.com/content/scholastic/books2/house-of-robots-by-chris-grabenstein
, type(eachValue)=<class 'str'>
eachValue=
https://www.scholastic.com/teachers/books/house-of-robots-by-chris-grabenstein/
, type(eachValue)=<class 'str'>
eachValue=House of Robots, type(eachValue)=<class 'str'>
eachValue=
https://www.scholastic.com/content5/media/products/49/9780545912549_mres.jpg
, type(eachValue)=<class 'str'>
eachValue=['Chris Grabenstein', 'James Patterson'], type(eachValue)=<class 'list'>
eachValue=['Juliana Neufeld'], type(eachValue)=<class 'list'>
eachValue=, type(eachValue)=<class 'str'>
eachValue=0, type(eachValue)=<class 'int'>
eachValue=['3-5', '6-8'], type(eachValue)=<class 'list'>
eachValue=T, type(eachValue)=<class 'str'>
eachValue=750L, type(eachValue)=<class 'str'>
eachValue=, type(eachValue)=<class 'str'>
eachValue=50, type(eachValue)=<class 'str'>
eachValue=Fiction, type(eachValue)=<class 'str'>
eachValue=It's never been easy for Sammy Hayes-Rodriguez to fit in, so he's dreading the day when his genius mom insists he bring her newest invention to school: a walking, talking robot he calls E - for "Error." Sammy's no stranger to robots; his house is full of them. But this one not only thinks it's Sammy's brother; it's actually even nerdier than Sammy. Will E be Sammy's one-way ticket to Loserville? Or will he prove to the world that it's cool to be square? It's a roller-coaster ride for Sammy to discover the amazing secret E holds that could change his family forever, if all goes well on the trial run!, type(eachValue)=<class 'str'>
eachValue=336, type(eachValue)=<class 'int'>
eachValue=9780545912549, type(eachValue)=<class 'str'>
eachValue=['Fitting In', 'Inventors and Inventions', 'Middle School', 'Siblings'], type(eachValue)=<class 'list'>
eachValue=[{'url': '
https://www.scholastic.com/content/scholastic/books2/my-sister-the-vampire-11-vampire-school-dropout-by-sienna-mer
', 'title': 'Vampire School Dropout?'}, {'url': '
https://www.scholastic.com/content/scholastic/books2/middle-school-my-brother-is-a-big-fat-liar-by-james-patterson
', 'title': 'My Brother Is a Big, Fat Liar'}, {'url': '
https://www.scholastic.com/content/scholastic/books2/candy-apple-11-the-sister-switch-by-jane-b-mason
', 'title': 'The Sister Switch'}], type(eachValue)=<class 'list'>
好像是没问题的:
除了recommendations外,
都是str或int,或str的list,都是普通变量,没有ObjectId
算了,还是:
要么注释掉:super(Handler, self).on_result(result) # 调用原有的数据存储
要么想办法找到正确的写法?
先去找找是否有更好的写法
pyspider result worker
pyspider result worker on_result
pyspider on_result
demo.pyspider.org 部署经验 | Binuxの杂货铺
“super(Handler, self).on_result(result)”
是作者自己这么写的,说明没问题。
Pyspider操作指南 | 思维之海
算了,去注释掉:
def on_result(self, result):
print("PySpider on_result: result=%s" % result)
self.mongo.on_result(result) # 执行插入数据的操作
# super(Handler, self).on_result(result) # 调用原有的数据存储结果:
终于没有错误了,但是Results中也不会有数据保存了:


【总结】
此处PySpider保存的json字典中,没有特殊的值的类型,都是普通的str,int,str的list等,
尤其是没有(pymongo的)ObjectId
并且:(实际上是没关系,但是以防万一)我ResultMongo的on_result中的(真正是)ObjectId的变量,也去转为str了。
但是结果用:
from pyspider.libs.base_handler import *
import re
import json
# import html
import lxml
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from pymongo import MongoClient
class ResultMongo(object):
def __init__(self):
print("ResultMongo __init__")
self.client = createMongoClient()
print("self.client=%s" % self.client)
self.db = self.client[MONGODB_DB_NAME]
print("self.db=%s" % self.db) # self.db=Database(MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True), 'Scholastic')
self.collection = self.db[MONGODB_COLLECTION_NAME]
print("self.collection=%s" % self.collection) # self.collection=Collection(Database(MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True), 'Scholastic'), 'Storybook')
def __del__(self):
print("ResultMongo __del__")
self.client.close()
def on_result(self, result):
"""save result to mongodb"""
print("ResultMongo on_result: result=%s" % result)
respResult = None
if result:
respResult = self.collection.insert(result)
print("type(respResult)=%s" % type(respResult))
respResult = str(respResult)
print("type(respResult)=%s" % type(respResult))
print("respResult=%s" % respResult) # respResult=5bc45fad7f4d3847b78e8c69
return respResult
class Handler(BaseHandler):
mongo = ResultMongo()
print("mongo=%s" % mongo)
# for debug
for eachValue in respDict.values():
print("eachValue=%s, type(eachValue)=%s" % (eachValue, type(eachValue)))
...
return respDict
def on_result(self, result):
print("PySpider on_result: result=%s" % result)
self.mongo.on_result(result) # 执行插入数据的操作
super(Handler, self).on_result(result) # 调用原有的数据存储但是竟然竟然报错:
TypeError: Object of type ‘ObjectId’ is not JSON serializable
所以很是诡异。
最后没办法,只有去注释掉PySpider中的保存数据:
# super(Handler, self).on_result(result)
而规避此问题。
-》由此,当然PySpider中webui点击Results的话,也是看不到结果,是空的了。
TODO:
如果以后有机会和时间,再去深入研究,为何出现这么奇怪的问题,找到根本原因。
【后记1】
后来开始真正批量爬取时,又出现此错误了:
所以看来是其他方面的问题,不是此处的问题。
转载请注明:在路上 » 【部分解决】PySPider出错:TypeError: Object of type ‘ObjectId’ is not JSON serializable