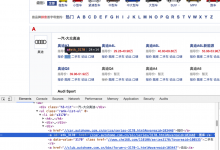
【已解决】pyspider中如何写规则去提取网页内容
crifan 8年前 (2018-04-22) 3957浏览
折腾: 【已解决】写Python爬虫爬取汽车之家品牌车系车型数据 期间,对于如下页面的数据: 此处是需要抓取: class=”rank-list-ul” 中的: a中href类似于: “//car.autohom...
crifan 8年前 (2018-04-22) 3957浏览
折腾: 【已解决】写Python爬虫爬取汽车之家品牌车系车型数据 期间,对于如下页面的数据: 此处是需要抓取: class=”rank-list-ul” 中的: a中href类似于: “//car.autohom...
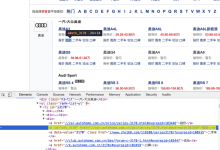
crifan 8年前 (2018-04-22) 4270浏览
折腾: 【已解决】写Python爬虫爬取汽车之家品牌车系车型数据 期间,对于同样的html内容: <code><ul class="rank-list-ul" 0="">...
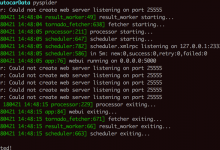
crifan 8年前 (2018-04-21) 8534浏览
折腾: 【已解决】写Python爬虫爬取汽车之家品牌车系车型数据 期间,去运行pyspider,结果出错: <code>➜ AutocarData pyspider Error: Could not create web server ...

crifan 8年前 (2018-04-21) 5517浏览
折腾: 【已解决】写Python爬虫爬取汽车之家品牌车系车型数据 期间,在pipenv中安装好了pyspider后,去运行: pyspider 结果出错: <code>➜ AutocarData pyspider phantomjs f...
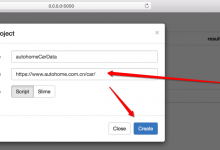
crifan 8年前 (2018-04-21) 7490浏览
需要实现爬取汽车之家的所有的品牌的车系和车型数据: https://www.autohome.com.cn/car/ 现在去写Python的爬虫。 之前了解有多个爬虫框架,用过Scrapy,貌似有点点复杂。 听说PySpider不错,去试试,主要看中...
crifan 8年前 (2018-03-22) 2579浏览
根据需求,需要去爬取: Eng-NA Corpora Bilingual Corpora 中,对应的内容的: 字幕,去掉各种标注的 音频,如果有 视频,如果有 参考之前自己的: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕...
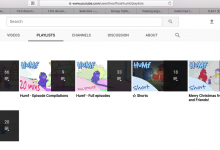
crifan 9年前 (2018-03-07) 6654浏览
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,发现个问题: 对于原始的页面中的多个分组的内容: 结果最后抓取的内容,缺了很多: 比如: ☆ Shorts 中,本来有18个,但是实际上只爬取了8个: 缺了1...
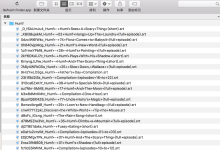
crifan 9年前 (2018-03-07) 5478浏览
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,虽然已经用代码: <code># -*- coding: utf-8 -*- import scrapy # from scrapy import R...
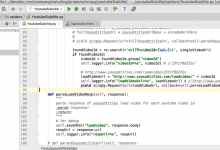
crifan 9年前 (2018-03-05) 5193浏览
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,已经可以用scrapy去post某个url得到返回的部分的html的字符串了: {“id”:1637788,”title&#...
crifan 9年前 (2018-03-02) 4539浏览
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间, 已经可以去用scrapy打开页面: http://www.yousubtitles.com/load/?url=https%3A%2F%2Fwww.youtub...