折腾:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
期间,发现个问题:
对于原始的页面中的多个分组的内容:
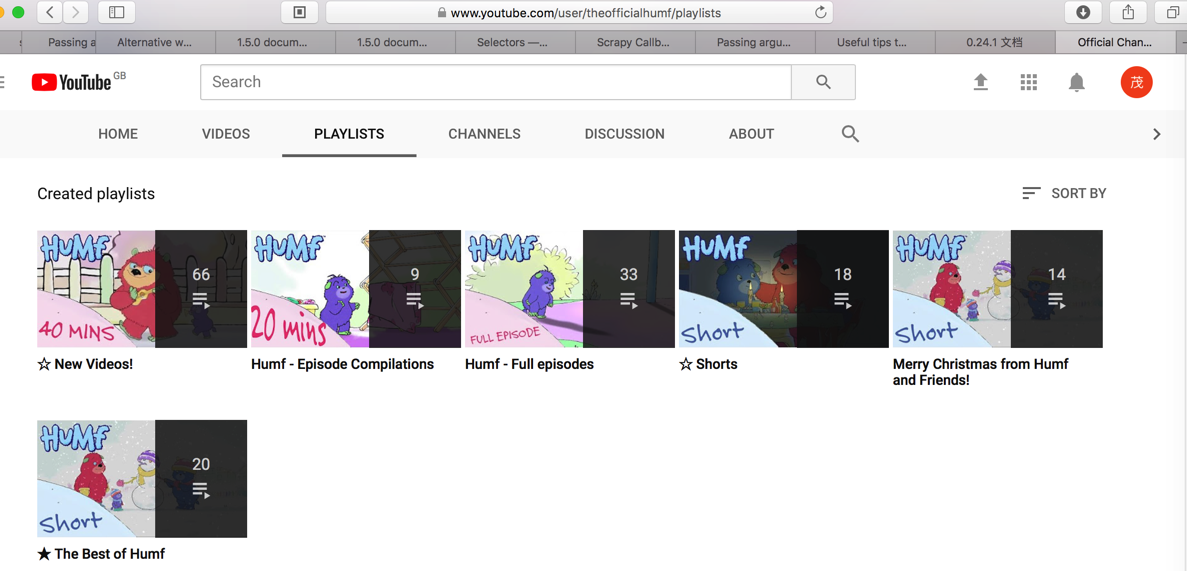
结果最后抓取的内容,缺了很多:
比如:
☆ Shorts
中,本来有18个,但是实际上只爬取了8个:
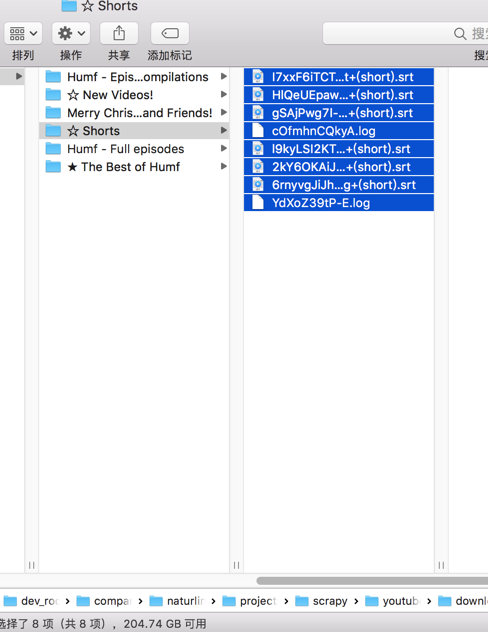
缺了10个
其他也是缺很多。
但是我的代码中,是对于异常的情况,是做了处理,也打了断点的:
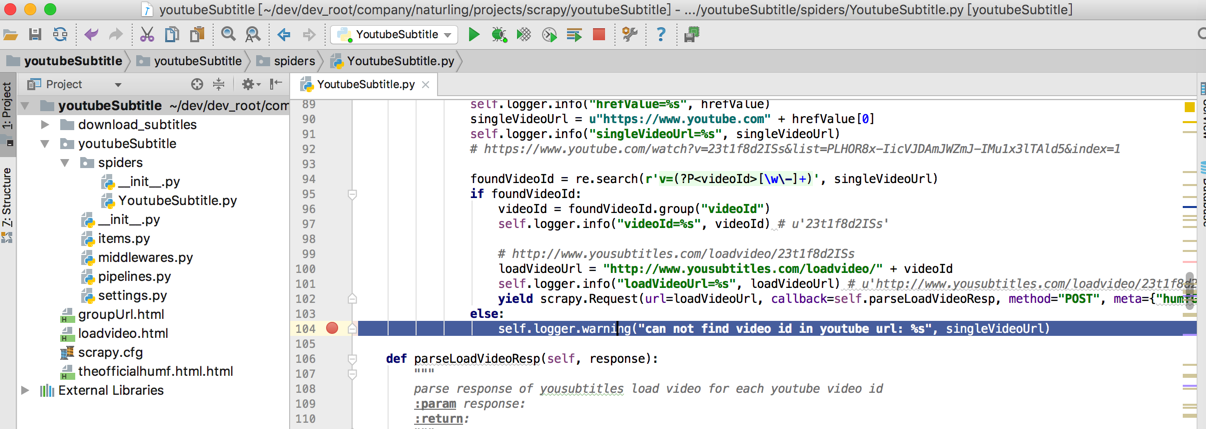
但是并没有执行到。
而对于字幕本身,xxx.log的是异常的内容,获取不到字幕的,也是做了处理的:
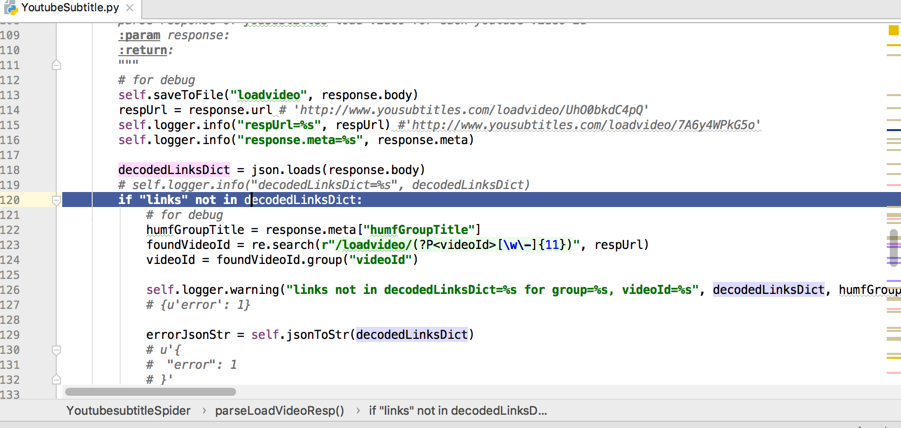
所以此处要去找到什么原因导致丢失url没有抓取。
scrapy crawl missing
scrapy missing url
scrapy 丢失url
python 2.7 – scrapy “Missing scheme in request url” – Stack Overflow
Request(url,callback=self.parse_item)有些请求会丢失掉? – 黄瓜君的回答 – SegmentFault 思否
scrapy yield request lost
python – Scrapy: how to debug scrapy lost requests – Stack Overflow
有空试试:
dont_filter=True
看到
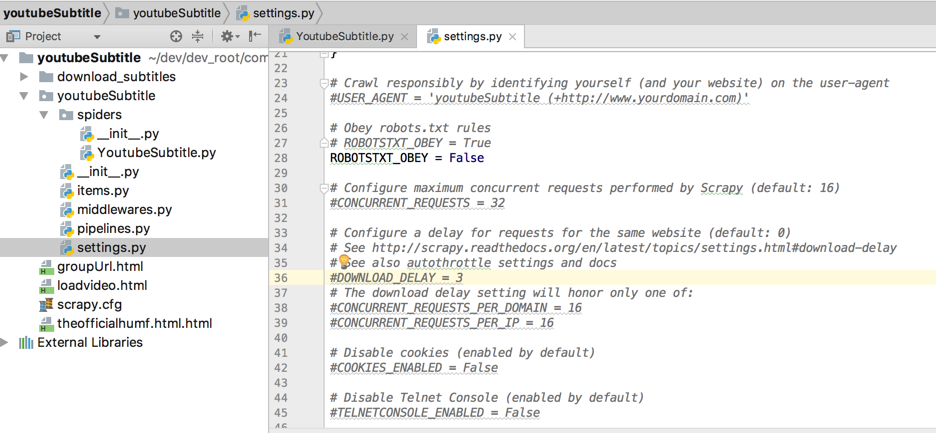
所以去开启这些参数:
youtubeSubtitle/settings.py
<code># Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16 </code>
看看效果,能否减少丢失url的情况
好像没用。
算了,降低点delay,加上其他的:
<code># Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 3
DOWNLOAD_DELAY = 0.5
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'youtubeSubtitle.pipelines.YoutubesubtitlePipeline': 300,
}
</code>以及加上dont_filter=True:
<code>yield scrapy.Request(url=groupUrl, callback=self.parseEachYoutubeUrl, dont_filter=True) </code>
然后就可以不丢失url了,可以全部爬取了:
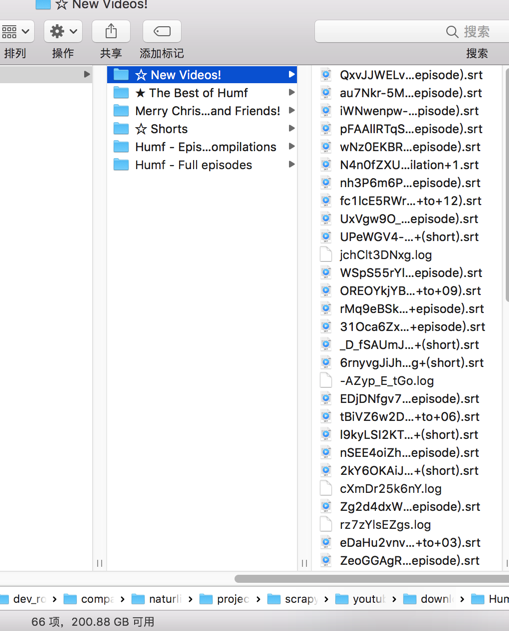
【总结】
可能是:filter过滤了
也可能是:爬取频率太快导致其他问题,最后是:
youtubeSubtitle/settings.py
中配置为:
<code># Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # DOWNLOAD_DELAY = 3 DOWNLOAD_DELAY = 0.5 # The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16 </code>
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
‘youtubeSubtitle.pipelines.YoutubesubtitlePipeline’: 300,
}
以及每个Request都加上dont_filter=True:
<code>yield scrapy.Request(url=groupUrl,
callback=self.parseEachYoutubeUrl,
dont_filter=True)
yield scrapy.Request(url=loadVideoUrl,
callback=self.parseLoadVideoResp,
method="POST",
dont_filter=True,
meta={"humfGroupTitle" : humfGroupTitle})
yield scrapy.Request(url=downloadUrl,
callback=self.parseDownloadSubtitlesResp,
meta=response.meta,
dont_filter=True)
</code>最后就全部不丢失url,全部可以慢慢的爬取了。
转载请注明:在路上 » 【已解决】Scrapy中丢失部分url链接没有抓取