折腾:
【已解决】写脚本下载crifan的所有电子书
之后,继续顺带生成所有的crifan的ebook的电子书的url的列表
【总结】
经过调试,代码:
# Function: Download all crifan ebook files
# Author: Crifan Li
# Update: 20201212
# Latest: https://github.com/crifan/crifan_ebook_readme/blob/master/downloadAllBooks.py
import os
import codecs
import re
import requests
import time
################################################################################
# Config
################################################################################
OutputFolder = os.path.join("downloaded", "pdf")
# 'downloaded/pdf'
RequestsProxies = {
"http" : "http://127.0.0.1:58591",
"https" : "http://127.0.0.1:58591",
}
################################################################################
# Util Functions
################################################################################
def createFolder(folderFullPath):
"""
create folder, even if already existed
Note: for Python 3.2+
"""
os.makedirs(folderFullPath, exist_ok=True)
def loadTextFromFile(fullFilename, fileEncoding="utf-8"):
"""load file text content from file"""
with codecs.open(fullFilename, 'r', encoding=fileEncoding) as fp:
allText = fp.read()
# logging.debug("Complete load text from %s", fullFilename)
return allText
def isFileExistAndValid(filePath, fullFileSize=None):
"""Check file exist and valid or not
Args:
filePath (str): file path
fullFileSize (int): full file size
Returns:
existed and valid (bool)
Raises:
Examples:
"""
isExistFile = os.path.isfile(filePath)
isValidFile = False
if isExistFile:
curFileSize = os.path.getsize(filePath) # 260900226
if fullFileSize:
isValidFile = curFileSize == fullFileSize
else:
isValidFile = curFileSize > 0
isExistAndValid = isExistFile and isValidFile
return isExistAndValid
def floatSecondsToDatetimeDict(floatSeconds):
"""
convert float seconds(time delta) to datetime dict{days, hours, minutes, seconds, millseconds, microseconds}
example: 96400.3765293 -> {'days': 1, 'hours': 2, 'minutes': 46, 'seconds': 40, 'millseconds': 376, 'microseconds': 529}
"""
secondsInt = int(floatSeconds)
decimalsFloat = floatSeconds - secondsInt
millisecondsFloat = decimalsFloat * 1000
millisecondsInt = int(millisecondsFloat)
microsecondsDecimal = millisecondsFloat - millisecondsInt
microsecondsInt = int(microsecondsDecimal * 1000)
minutes, seconds = divmod(secondsInt, 60)
hours, minutes = divmod(minutes, 60)
days, hours = divmod(hours, 24)
convertedDict = {
"days": days,
"hours": hours,
"minutes": minutes,
"seconds": seconds,
"millseconds": millisecondsInt,
"microseconds": microsecondsInt,
}
return convertedDict
def datetimeDictToStr(datetimeDict,
seperatorD=" ",
seperatorHms=":",
seperatorMilliS=".",
isShowZeroDayStr=False,
isShowMilliSecPart=True,
):
"""Convert date time dict into date time string
Args:
datetimeDict (dict): date time dict
seperatorD (str): day seperator
seperatorHms (str): hour/minute/second seperator
seperatorMilliS (str): milli seconds seperator
isShowZeroDayStr (bool): whether show days string when days=0
isShowMilliSecPart (bool): whether show milli seconds part
Returns:
str
Raises:
Examples:
input:
{'days': 0, 'hours': 0, 'microseconds': 986, 'millseconds': 804, 'minutes': 3, 'seconds': 38}
{'hours': 0, minutes': 3, 'seconds': 38}
output:
'0 00:03:38.804'
'00:03:38'
"""
dayStr = ""
hasDays = "days" in datetimeDict
if hasDays:
days = datetimeDict["days"]
if (not isShowZeroDayStr) and (days == 0):
dayStr = ""
else:
dayStr = "%d%s" % (days, seperatorD)
hmsStr = "%02d%s%02d%s%02d" % (datetimeDict["hours"], seperatorHms, datetimeDict["minutes"], seperatorHms, datetimeDict["seconds"]) # '00:03:12'
milliSecStr = ""
hasMilliSec = "millseconds" in datetimeDict
if hasMilliSec:
if isShowMilliSecPart:
milliSecStr = "%s%03d" % (seperatorMilliS, datetimeDict["millseconds"])
formattedStr = "%s%s%s" % (dayStr, hmsStr, milliSecStr) # '00:03:12'
return formattedStr
def formatSize(sizeInBytes, decimalNum=1, isUnitWithI=False, sizeUnitSeperator=""):
"""
format size to human readable string
example:
3746 -> 3.7KB
87533 -> 85.5KiB
98654 -> 96.3 KB
352 -> 352.0B
76383285 -> 72.84MB
763832854988542 -> 694.70TB
763832854988542665 -> 678.4199PB
refer:
https://stackoverflow.com/questions/1094841/reusable-library-to-get-human-readable-version-of-file-size
"""
# https://en.wikipedia.org/wiki/Binary_prefix#Specific_units_of_IEC_60027-2_A.2_and_ISO.2FIEC_80000
# K=kilo, M=mega, G=giga, T=tera, P=peta, E=exa, Z=zetta, Y=yotta
sizeUnitList = ['','K','M','G','T','P','E','Z']
largestUnit = 'Y'
if isUnitWithI:
sizeUnitListWithI = []
for curIdx, eachUnit in enumerate(sizeUnitList):
unitWithI = eachUnit
if curIdx >= 1:
unitWithI += 'i'
sizeUnitListWithI.append(unitWithI)
# sizeUnitListWithI = ['','Ki','Mi','Gi','Ti','Pi','Ei','Zi']
sizeUnitList = sizeUnitListWithI
largestUnit += 'i'
suffix = "B"
decimalFormat = "." + str(decimalNum) + "f" # ".1f"
finalFormat = "%" + decimalFormat + sizeUnitSeperator + "%s%s" # "%.1f%s%s"
sizeNum = sizeInBytes
for sizeUnit in sizeUnitList:
if abs(sizeNum) < 1024.0:
return finalFormat % (sizeNum, sizeUnit, suffix)
sizeNum /= 1024.0
return finalFormat % (sizeNum, largestUnit, suffix)
def getFileSizeFromUrl(fileUrl, proxies=None):
"""Get file size from file url
Args:
fileUrl (str): file url
proxies (dict): requests proxies
Returns:
file size or 0 mean fail to get
Raises:
Examples:
input: https://gameapktxdl.vivo.com.cn/appstore/developer/soft/20201020/202010201805243ed5v.apk
output: 154551625
"""
totalFileSize = None
try:
resp = requests.get(fileUrl, stream=True, proxies=proxies)
respHeaders = resp.headers
# {'Date': 'Thu, 10 Dec 2020 05:27:10 GMT', 'Content-Type': 'application/vnd.android.package-archive', 'Content-Length': '154551625', 'Connection': 'keep-alive', 'Server': 'NWS_TCloud_static_msoc1_xz', 'Cache-Control': 'max-age=600', 'Expires': 'Thu, 10 Dec 2020 05:37:09 GMT', 'Last-Modified': 'Thu, 09 Jan 2020 11:21:35 GMT', 'X-NWS-UUID-VERIFY': '94db2d14f135898d924fb249b13a0964', 'X-Verify-Code': '2871bd7acf67c7e298e9c8d8c865e27d', 'X-NWS-LOG-UUID': 'a83536f2-ab83-465d-ba09-0e19a15cc706', 'X-Cache-Lookup': 'Hit From Disktank3, Hit From Inner Cluster', 'Accept-Ranges': 'bytes', 'ETag': '"46C50A5CADB6BEE339236477BB6DDC14"', 'X-Daa-Tunnel': 'hop_count=2'}
# {'Server': 'Tengine', 'Date': 'Fri, 11 Dec 2020 14:11:00 GMT', 'Content-Type': 'application/pdf', 'Content-Length': '24422168', 'Last-Modified': 'Fri, 18 Sep 2020 09:56:15 GMT', 'Connection': 'keep-alive', 'ETag': '"5f64843f-174a718"', 'Strict-Transport-Security': 'max-age=15768000', 'Accept-Ranges': 'bytes'}
contentLengthStr = respHeaders['Content-Length'] # '154551625', '24422168'
contentLengthInt = int(contentLengthStr) # 154551625, 24422168
totalFileSize = contentLengthInt
except:
totalFileSize = None
return totalFileSize # 154551625
def streamingDownloadFile(
url,
fileToSave=None,
proxies=None,
isShowSpeed=True,
chunkSize=1024*512,
resumeSize=0,
totalSize=0,
):
"""Download file using stream mode, support showing process with current speed, percent, size
Args:
url (str): file online url
fileToSave (str): filename or full file path
proxies (dict): requests proxies
isShowSpeed (bool): show downloading speed or not
chunkSize (int): when showing download speed, need use stream downloading, need set chunck size
resumeSize (bool): the size to start download, normally is the local already downloaded size
totalSize (int): total file size, only used for calculate downloaded percent
Returns:
download ok or not (bool)
Raises:
Examples:
"""
isDownloadOk = False
if isShowSpeed:
if totalSize == 0:
gotTotalSize = getFileSizeFromUrl(url, proxies) # 154551625
if gotTotalSize:
totalSize = gotTotalSize
headers = {
'Range': 'bytes=%d-' % resumeSize,
# "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
}
resp = requests.get(url, proxies=proxies, headers=headers, stream=True)
curDownloadedSize = 0
with open(fileToSave, "ab") as f:
startTime = time.time()
prevTime = startTime
for curChunkBytes in resp.iter_content(chunk_size=chunkSize):
if curChunkBytes:
curTime = time.time() # 1606456020.0718982
f.write(curChunkBytes)
f.flush()
curChunkSize = len(curChunkBytes) # 524288
curDownloadedSize += curChunkSize # 524288
totalDownloadedSize = curDownloadedSize + resumeSize # 12058624
totalDownloadedSizeStr = formatSize(totalDownloadedSize) # '11.5MB'
curDownloadTime = curTime - prevTime # 15.63818907737732
curSpeed = curChunkSize / curDownloadTime # 670522.651191692
curSpeedStr = formatSize(curSpeed) # '231.3KB'
totalDownloadTime = curTime - startTime # 15.63818907737732
averageSpeed = curDownloadedSize / totalDownloadTime # 670522.651191692
averageSpeedStr = formatSize(averageSpeed) # '231.3KB'
totalDownloadTimeDict = floatSecondsToDatetimeDict(totalDownloadTime)
totalDownloadTimeStr = datetimeDictToStr(totalDownloadTimeDict, isShowMilliSecPart=False)
if isShowSpeed:
showStr = "downloading speed: cur=%s/s, avg=%s/s, time: total=%s, size: %s" % (curSpeedStr, averageSpeedStr, totalDownloadTimeStr, totalDownloadedSizeStr)
if totalSize > 0:
downloadedPercent100 = round(100 * totalDownloadedSize / totalSize, 2) # 47.23
downloadedPercent100Str = str(downloadedPercent100) # '47.23'
percentStr = ", percent: %s%%" % downloadedPercent100Str # ', percent: 47.23%'
else:
percentStr = ""
showStr += percentStr
# 'downloading speed: cur=231.3KB/s, avg=231.3KB/s, time: total=00:00:02, size: 11.5MB, percent: 49.38%'
print(showStr)
prevTime = curTime
return isDownloadOk
def downloadFile(url,
fileToSave=None,
proxies=None,
isStreamMode=True,
isResume=True,
):
"""Download file from url then save to file
Args:
url (str): file online url
fileToSave (str): filename or full file path
proxies (dict): requests proxies
isStreamMode (bool): use stream mode or not
Returns:
download ok or not (bool)
Raises:
Examples:
input:
'https://book.crifan.com/books/5g_message_rcs_tech_summary/pdf/5g_message_rcs_tech_summary.pdf'
'downloaded/pdf/5g_message_rcs_tech_summary.pdf'
output:
True
"""
isDownloadOk = False
if not fileToSave:
urlPartList = url.split("/")
fileToSave = urlPartList[-1] # 5g_message_rcs_tech_summary.pdf
try:
if isStreamMode:
totalFileSize = getFileSizeFromUrl(url, proxies) # 154551625
if not totalFileSize:
print("Failed to get total file size from %s" % url)
return isDownloadOk
totalSizeStr = formatSize(totalFileSize)
print("Get total file size %s from %s" % (totalSizeStr, url))
isDownloadedAndValid = isFileExistAndValid(fileToSave, fullFileSize=totalFileSize)
if isDownloadedAndValid:
print("%s is already download" % fileToSave)
isDownloadOk = True
return isDownloadOk
curDownloadedSize = 0
isExistFile = os.path.isfile(fileToSave)
if isExistFile:
curDownloadedSize = os.path.getsize(fileToSave)
curDownloadedSizeStr = formatSize(curDownloadedSize)
print("Already downloaded %s for %s" % (curDownloadedSizeStr, fileToSave))
if curDownloadedSize > totalFileSize:
# possible is local is new version, so consider as downloaded
print("Downloaded=%s > online=%s, consider as downloaded" % (curDownloadedSizeStr, totalSizeStr))
isDownloadOk = True
return isDownloadOk
if not isResume:
curDownloadedSize = 0
isDownloadOk = streamingDownloadFile(
url,
fileToSave=fileToSave,
proxies=proxies,
isShowSpeed=True,
resumeSize=curDownloadedSize,
totalSize=totalFileSize,
)
else:
resp = requests.get(url, proxies=proxies)
with open(fileToSave, 'wb') as saveFp:
saveFp.write(resp.content)
isDownloadOk = True
except BaseException as curException:
print("Exception %s when download %s to %s" % (curException, url, fileToSave))
return isDownloadOk
################################################################################
# Const & Config & Settings
################################################################################
InputMdFile = "README.md"
################################################################################
# Main
################################################################################
mdStr = loadTextFromFile(InputMdFile)
# print("mdStr=%s" % mdStr)
allPdfUrlList = []
# * [Notepad++](https://www.crifan.com/files/doc/docbook/rec_soft_npp/release/html/rec_soft_npp.html)
# * [硬件电路基础知识](https://www.crifan.com/files/doc/docbook/hardware_basic/release/html/hardware_basic.html)
# allDocbookIter = re.finditer("https?://www\.crifan\.com/files/doc/docbook/(?P<bookName>\w+)/release/", mdStr)
# <callable_iterator object at 0x1094acfd0>
# allDocbookList = list(allDocbookIter)
# [<re.Match object; sp...soft_dev_>, <re.Match object; sp...rec_soft_>, <re.Match object; sp...programmi>, <re.Match object; sp...language_>, <re.Match object; sp...json_tuto>, <re.Match object; sp...char_enco>, <re.Match object; sp...char_enco>, <re.Match object; sp...python_to>, <re.Match object; sp...regular_e>, <re.Match object; sp...python_to>, <re.Match object; sp...csharp_su>, <re.Match object; sp...build_web>, <re.Match object; sp...website_t>, <re.Match object; sp...web_scrap>, ...]
# allDocbookList = re.findall("https?://www\.crifan\.com/files/doc/docbook/\w+/release/", mdStr)
allDocbookNameList = re.findall("https?://www\.crifan\.com/files/doc/docbook/(\w+)/release/", mdStr)
# ['char_encoding_usage', 'crifanlib_python', ...]
docbookTotalNum = len(allDocbookNameList)
print("docbookTotalNum=%s" % docbookTotalNum) # 113
uniqueDocbookNameSet = set(allDocbookNameList)
uniqueDocbookNameList = list(uniqueDocbookNameSet)
uniqueDocbookTotalNum = len(uniqueDocbookNameList)
print("uniqueDocbookTotalNum=%s" % uniqueDocbookTotalNum) # 56
for curIdx, eachDocbookName in enumerate(uniqueDocbookNameList):
curNum = curIdx + 1
curDocbookPdfUrl = "https://www.crifan.com/files/doc/docbook/%s/release/pdf/%s.pdf" % (eachDocbookName, eachDocbookName)
# print("[%d] curDocbookPdfUrl=%s" % (curNum, curDocbookPdfUrl))
# https://www.crifan.com/files/doc/docbook/rec_soft_npp/release/pdf/rec_soft_npp.pdf
# https://www.crifan.com/files/doc/docbook/soft_dev_basic/release/pdf/soft_dev_basic.pdf
allPdfUrlList.append(curDocbookPdfUrl)
# * [风格](https://book.crifan.com/books/program_code_style/website)
# * [VSCode](http://book.crifan.com/books/best_editor_vscode/website)
allGitbookNameList = re.findall("https?://book\.crifan\.com/books/(\w+)/website", mdStr)
gitbooNameTotalNum = len(allGitbookNameList)
print("gitbooNameTotalNum=%s" % gitbooNameTotalNum) # 139
uniqueGitbookNameSet = set(allGitbookNameList)
uniqueGitbookNameList = list(uniqueGitbookNameSet)
uniqueGitbookNameTotalNum = len(uniqueGitbookNameList)
print("uniqueGitbookNameTotalNum=%s" % uniqueGitbookNameTotalNum) # 71
for curIdx, eachGitbookName in enumerate(uniqueGitbookNameList):
curNum = curIdx + 1
curGitbookPdfUrl = "https://book.crifan.com/books/%s/pdf/%s.pdf" % (eachGitbookName, eachGitbookName)
# print("[%d] curGitbookPdfUrl=%s" % (curNum, curGitbookPdfUrl))
# https://book.crifan.com/books/best_editor_vscode/pdf/best_editor_vscode.pdf
# https://book.crifan.com/books/scientific_network_summary/pdf/scientific_network_summary.pdf
allPdfUrlList.append(curGitbookPdfUrl)
allPdfUrlList.sort()
pdfUrlTotalNum = len(allPdfUrlList)
print("pdfUrlTotalNum=%s" % pdfUrlTotalNum) # 127
# download all pdf url
for curUrlIdx, eachPdfUrl in enumerate(allPdfUrlList):
curUrlNum = curUrlIdx + 1
# 'https://book.crifan.com/books/5g_message_rcs_tech_summary/pdf/5g_message_rcs_tech_summary.pdf'
pdfFilename = eachPdfUrl.split("/")[-1]
# '5g_message_rcs_tech_summary.pdf'
print("%s [%2d/%2d] %s %s" % ("-"*30, curUrlNum, pdfUrlTotalNum, pdfFilename ,"-"*30))
print("%s" % eachPdfUrl)
downloadedFilePath = os.path.join(OutputFolder, pdfFilename)
isDownloadOk = downloadFile(eachPdfUrl, downloadedFilePath, proxies=RequestsProxies)
print("%s to downloaded %s from %s" % (isDownloadOk, pdfFilename, eachPdfUrl))生成:
allEbookList/AllCrifanEbookList.md
* crifan所有电子书列表 * docbook * https://www.crifan.com/files/doc/docbook/antlr_tutorial/release/html/antlr_tutorial.html * https://www.crifan.com/files/doc/docbook/arm_vs_mips/release/html/arm_vs_mips.html * https://www.crifan.com/files/doc/docbook/binutils_intro/release/html/binutils_intro.html * https://www.crifan.com/files/doc/docbook/build_website/release/html/build_website.html * https://www.crifan.com/files/doc/docbook/buy_house/release/html/buy_house.html * https://www.crifan.com/files/doc/docbook/char_encoding/release/html/char_encoding.html * https://www.crifan.com/files/doc/docbook/char_encoding_usage/release/html/char_encoding_usage.html * https://www.crifan.com/files/doc/docbook/compute_basic/release/html/compute_basic.html * https://www.crifan.com/files/doc/docbook/crifan_rec_soft/release/html/crifan_rec_soft.html * https://www.crifan.com/files/doc/docbook/crifanlib_csharp/release/html/crifanlib_csharp.html * https://www.crifan.com/files/doc/docbook/crifanlib_python/release/html/crifanlib_python.html * https://www.crifan.com/files/doc/docbook/cross_compile/release/html/cross_compile.html * https://www.crifan.com/files/doc/docbook/crosstool_ng/release/html/crosstool_ng.html * https://www.crifan.com/files/doc/docbook/csharp_summary/release/html/csharp_summary.html * https://www.crifan.com/files/doc/docbook/cygwin_intro/release/html/cygwin_intro.html * https://www.crifan.com/files/doc/docbook/dma_pl08x_analysis/release/html/dma_pl08x_analysis.html * https://www.crifan.com/files/doc/docbook/docbook_dev_note/release/html/docbook_dev_note.html * https://www.crifan.com/files/doc/docbook/embedded_drv_dev/release/html/embedded_drv_dev.html * https://www.crifan.com/files/doc/docbook/embedded_linux_dev/release/html/embedded_linux_dev.html * https://www.crifan.com/files/doc/docbook/embedded_linux_drv_dev/release/html/embedded_linux_drv_dev.html * https://www.crifan.com/files/doc/docbook/fieldbus_intro/release/html/fieldbus_intro.html * https://www.crifan.com/files/doc/docbook/firmware_download/release/html/firmware_download.html * https://www.crifan.com/files/doc/docbook/hardware_basic/release/html/hardware_basic.html * https://www.crifan.com/files/doc/docbook/interrupt_related/release/html/interrupt_related.html * https://www.crifan.com/files/doc/docbook/json_tutorial/release/html/json_tutorial.html * https://www.crifan.com/files/doc/docbook/language_summary/release/html/language_summary.html * https://www.crifan.com/files/doc/docbook/linux_nand_driver/release/html/linux_nand_driver.html * https://www.crifan.com/files/doc/docbook/linux_wireless/release/html/linux_wireless.html * https://www.crifan.com/files/doc/docbook/mpeg_vbr/release/html/mpeg_vbr.html * https://www.crifan.com/files/doc/docbook/nand_get_type/release/html/nand_get_type.html * https://www.crifan.com/files/doc/docbook/programming_language_basic/release/html/programming_language_basic.html * https://www.crifan.com/files/doc/docbook/python_beginner_tutorial/release/html/python_beginner_tutorial.html * https://www.crifan.com/files/doc/docbook/python_intermediate_tutorial/release/html/python_intermediate_tutorial.html * https://www.crifan.com/files/doc/docbook/python_summary/release/html/python_summary.html * https://www.crifan.com/files/doc/docbook/python_topic_beautifulsoup/release/html/python_topic_beautifulsoup.html * https://www.crifan.com/files/doc/docbook/python_topic_re/release/html/python_topic_re.html * https://www.crifan.com/files/doc/docbook/python_topic_str_encoding/release/html/python_topic_str_encoding.html * https://www.crifan.com/files/doc/docbook/python_topic_web_scrape/release/html/python_topic_web_scrape.html * https://www.crifan.com/files/doc/docbook/rec_soft_npp/release/html/rec_soft_npp.html * https://www.crifan.com/files/doc/docbook/regular_expression/release/html/regular_expression.html * https://www.crifan.com/files/doc/docbook/runtime_upgrade_linux/release/html/runtime_upgrade_linux.html * https://www.crifan.com/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html * https://www.crifan.com/files/doc/docbook/symbology_code128/release/html/symbology_code128.html * https://www.crifan.com/files/doc/docbook/symbology_gs1128/release/html/symbology_gs1128.html * https://www.crifan.com/files/doc/docbook/symbology_plessey/release/html/symbology_plessey.html * https://www.crifan.com/files/doc/docbook/symbology_upc/release/html/symbology_upc.html * https://www.crifan.com/files/doc/docbook/uboot_starts_analysis/release/html/uboot_starts_analysis.html * https://www.crifan.com/files/doc/docbook/usb_basic/release/html/usb_basic.html * https://www.crifan.com/files/doc/docbook/usb_disk_driver/release/html/usb_disk_driver.html * https://www.crifan.com/files/doc/docbook/usb_hid/release/html/usb_hid.html * https://www.crifan.com/files/doc/docbook/virtualbox_tutorial/release/html/virtualbox_tutorial.html * https://www.crifan.com/files/doc/docbook/virutal_machine_tutorial/release/html/virutal_machine_tutorial.html * https://www.crifan.com/files/doc/docbook/vmware_tutorial/release/html/vmware_tutorial.html * https://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_login.html * https://www.crifan.com/files/doc/docbook/website_transfer/release/html/website_transfer.html * https://www.crifan.com/files/doc/docbook/embedded_soft_dev/release/html/embedded_soft_dev.html * gitbook * http://book.crifan.com/books/5g_message_rcs_tech_summary/website * http://book.crifan.com/books/5g_tech_summary/website * http://book.crifan.com/books/all_age_sports_badminton/website * http://book.crifan.com/books/android_app_security_crack/website * http://book.crifan.com/books/app_capture_package_tool_charles/website * http://book.crifan.com/books/best_editor_vscode/website * http://book.crifan.com/books/china_suitable_living_suzhou/website * http://book.crifan.com/books/common_data_format_json/website * http://book.crifan.com/books/common_logic_hardware_embedded/website * http://book.crifan.com/books/computer_tech_summary/website * http://book.crifan.com/books/crawl_your_data_spider_technology/website * http://book.crifan.com/books/ebook_system_gitbook/website * http://book.crifan.com/books/file_compare_tool_summary/website * http://book.crifan.com/books/gitbook_demo/website * http://book.crifan.com/books/good_automation_tool_makefile/website * http://book.crifan.com/books/html_parse_tool_beautifulsoup/website * http://book.crifan.com/books/ic_chip_industry_chain_summary/website * http://book.crifan.com/books/industrial_automation_plc/website * http://book.crifan.com/books/industrial_control_security_overview/website * http://book.crifan.com/books/information_security_overview/website * http://book.crifan.com/books/mobile_network_evolution_history/website * http://book.crifan.com/books/most_intelligent_python_ide_pycharm/website * http://book.crifan.com/books/multimedia_core_system_ims/website * http://book.crifan.com/books/python_summary_csv_excel/website * http://book.crifan.com/books/python_summary_http_lib/website * http://book.crifan.com/books/python_html_parse_pyquery/website * http://book.crifan.com/books/python_regex_re_intro/website * http://book.crifan.com/books/python_spider_pyspider/website * http://book.crifan.com/books/python_spider_scrapy/website * http://book.crifan.com/books/regex_usage_examples/website * http://book.crifan.com/books/resident_life_experience_summary/website * http://book.crifan.com/books/smart_speaker_disassemble_summary/website * http://book.crifan.com/books/use_python_write_spider/website * http://book.crifan.com/books/version_control_git/website * https://book.crifan.com/books/5g_tech_summary/website * https://book.crifan.com/books/android_automation_uiautomator2/website * https://book.crifan.com/books/api_tool_postman/website * https://book.crifan.com/books/apple_develop_summary/website * https://book.crifan.com/books/automobile_sales_summary/website * https://book.crifan.com/books/best_diagram_tool/website * https://book.crifan.com/books/common_compress_tool_summary/website * https://book.crifan.com/books/crack_assistant_xposed_framework/website * https://book.crifan.com/books/desktop_app_framework_electron/website * https://book.crifan.com/books/doc_format_markdown/website * https://book.crifan.com/books/ebook_system_gitbook/website * https://book.crifan.com/books/editor_ide_summary/website * https://book.crifan.com/books/good_android_emulator_nox/website * https://book.crifan.com/books/http_restful_api/website * https://book.crifan.com/books/http_summary/website * https://book.crifan.com/books/improve_work_efficiency/website * https://book.crifan.com/books/ios_automation_facebook_wda/website * https://book.crifan.com/books/learn_tech_method_experience/website * https://book.crifan.com/books/make_life_better_python/website * https://book.crifan.com/books/media_process_ffmpeg/website * https://book.crifan.com/books/mobile_app_summary/website * https://book.crifan.com/books/mobile_automation_overview/website * https://book.crifan.com/books/popular_document_db_mongodb/website * https://book.crifan.com/books/popular_js_chart_lib_echarts/website * https://book.crifan.com/books/popular_rmdb_mysql/website * https://book.crifan.com/books/popular_virtual_machine_vmware/website * https://book.crifan.com/books/program_code_style/website * https://book.crifan.com/books/program_common_logic/website * https://book.crifan.com/books/python_common_code_snippet/website * https://book.crifan.com/books/python_newbie_mistakes_questions/website * https://book.crifan.com/books/python_summary_virtual_environment/website * https://book.crifan.com/books/rcs_tech_dev_summary/website * https://book.crifan.com/books/regex_usage_examples/website * https://book.crifan.com/books/scientific_network_summary/website * https://book.crifan.com/books/selenium_summary/website * https://book.crifan.com/books/super_search_regex/website * https://book.crifan.com/books/test_automation_overview/website * https://book.crifan.com/books/work_job_summary/website * https://book.crifan.com/books/xpath_summary/website * https://book.crifan.com/books/youdao_note_summary/website
预览效果:
用md插件生成HTML:
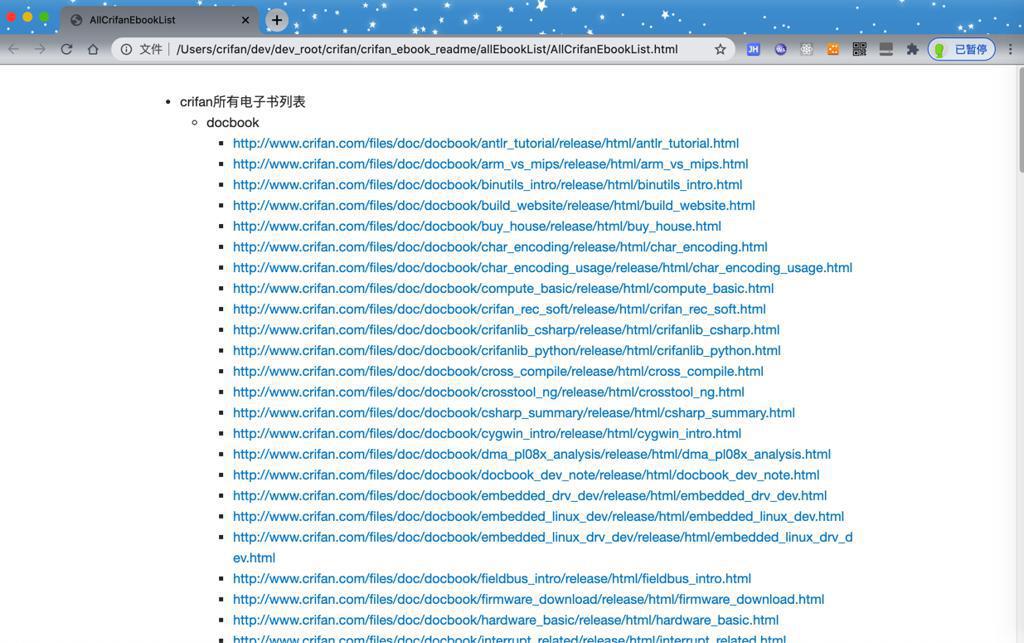
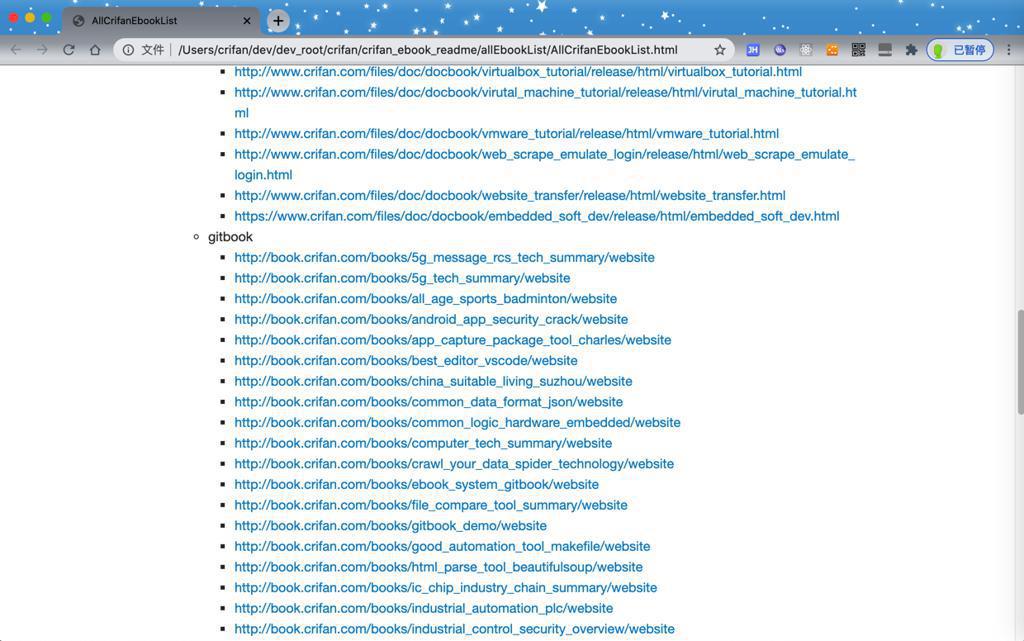
html打开效果:
继续生成pdf:
Chrome(Pupeteer) -》PDF
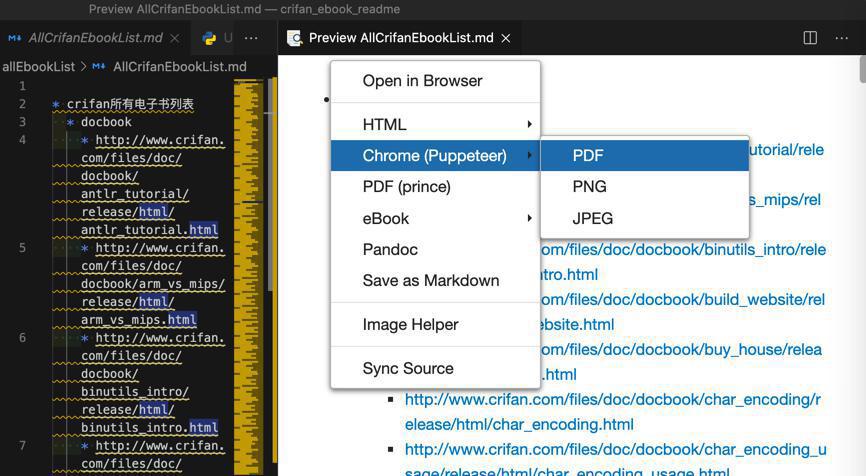
生成 73KB的pdf
(注:如果用eBook->PDF
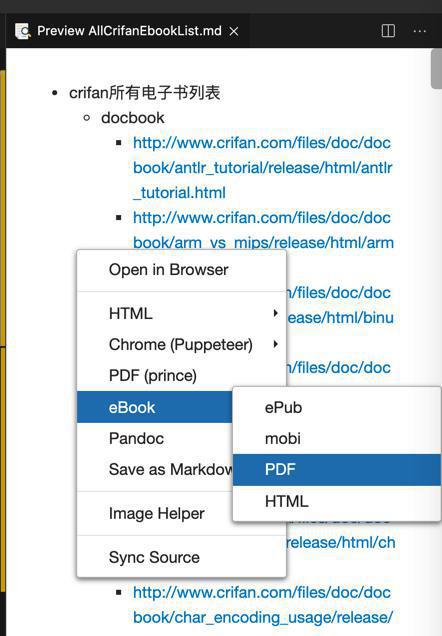
,会生成 非常大 没必要的 10MB的pdf,所以注意不要用这个方式生成pdf)
pdf预览效果:
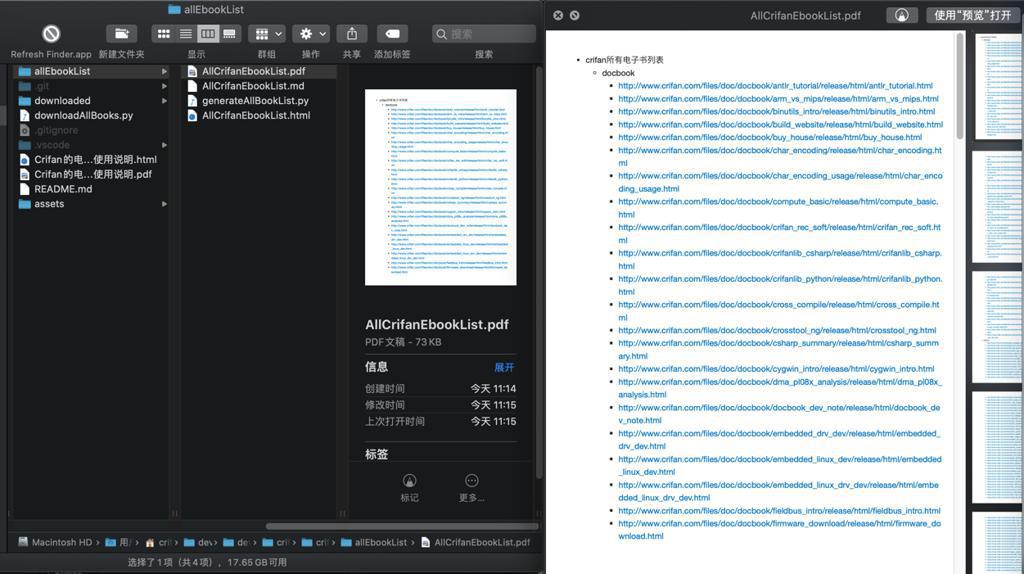
所有代码和文件:
都可以在
找到:
- 代码
- 文件