折腾:
【记录】用PySpider去爬取scholastic的绘本书籍数据
期间,突然发现需要爬取的页面中,其实js的代码中包含了更多我想要的信息:
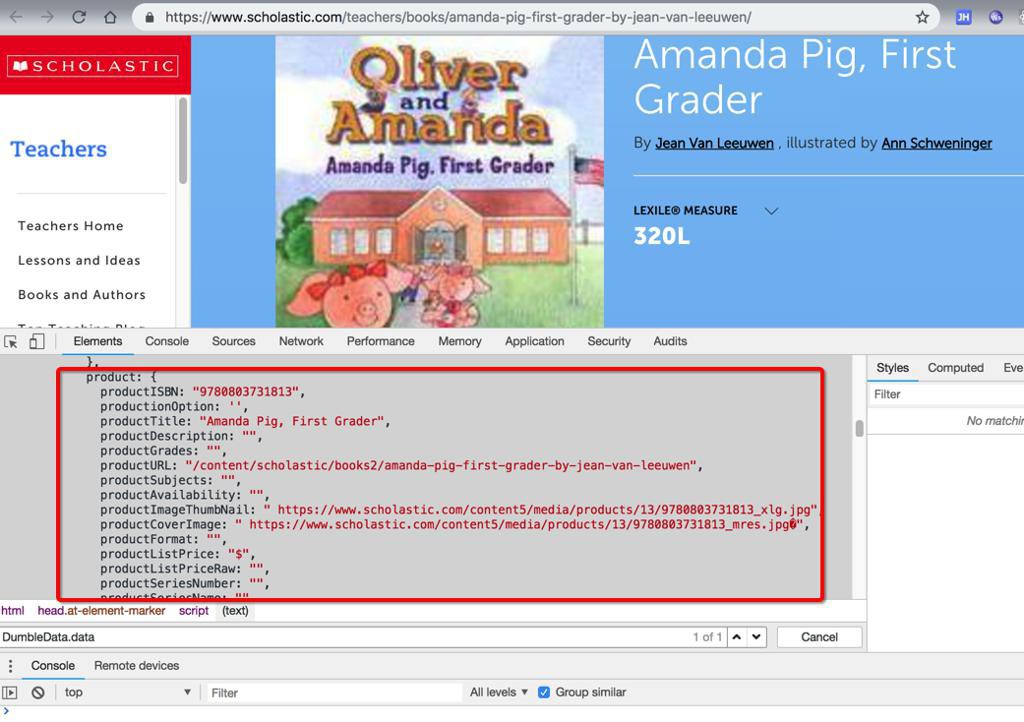
var DumbleData = {};
DumbleData.data = {
omniture: {
...
product: {
productISBN: "9780446608855",
productionOption: '',
productTitle: "Vengeance of Dragons",
productDescription: "The future of peace in the world depends on keeping an ancient and powerful artifact from evil hands. Kait Galweigh searches out the Mirror of Souls, hoping it can bring back her family, while Crispin Sabir wants the mirror because he thinks it will give",
productGrades: "9-12",
productURL: "/content/scholastic/books2/vengeance-of-dragons-by-holly-lisle",
productSubjects: "Character and Values,Friends and Friendship",
productAvailability: "",
productImageThumbNail: "
https://www.scholastic.com/content5/media/products/55/9780446608855_xlg.jpg
",
productCoverImage: "
https://www.scholastic.com/content5/media/products/55/9780446608855_mres.jpg
�",
productFormat: "",
productListPrice: "$",
productListPriceRaw: "",
productSeriesNumber: "",
productSeriesName: "",
productContributorDetails: "Holly Lisle|Author|/content/scholastic/contributors/holly-lisle",
productAvailabilityText: "",
productCartButtonText: "",
productInventory: "",
productReadingLevel: "Guided Reading:N/A | LEXILE MEASURE:920L | Grade Level Equivalent:N/A | DRA:N/A",
productGuidedReadingLevel: "N/A",
productEnglishLexileLevel: "920L",
productGradeLevelEquivalent: "N/A",
productDRALevel: "N/A",
productSalePrice: "$",
productSalePriceRaw: ""
}
}
};.....需要去想办法拿到这部分的js的字符串
然后再去转换js对象,获取我们要的product部分的值
pyspider get js
pyspider get js code
好像没有提及
自己去找找
先看看html或text中能否得到js字符串
抽空看看:
Response.text
Response.content
Response.etree
以及:
Response.doc
中找找<script type=”text/javascript”>
的部分
也要看看:
Response.js_script_result
content returned by JS script
经过测试发现:
respText = response.text
print("respText=%s" % respText)
respContent = response.content
print("respContent=%s" % respContent)
respEtree = response.etree
print("respEtree=%s" % respEtree)
respJsScriptResult = response.js_script_result
print("respJsScriptResult=%s" % respJsScriptResult)结果:
<!DOCTYPE HTML>
<html>
<script type="text/javascript">
var DumbleData = {};
DumbleData.data = {
omniture: {
...
product: {
productISBN: "9780688147327",
。。。
</body>
</html>
respContent=b'\n<!DOCTYPE HTML>\n<html>\n
respEtree=<Element html at 0x1031de048>
respJsScriptResult=None即:
- .content返回是二进制的数据:忽略
- .text:返回的字符串,且包含我们要的js的代码字符串
所以接着就可以去利用response.text,去提取自己要的js的字符串了。
【总结】
此处PySpider中在crawl的callback中,可以通过response.text得到html的字符串,其中包含了js的代码字符串。
转载请注明:在路上 » 【已解决】PyQuery中如何获取html中的js代码的文本字符串